
TL;DR
Today we’re releasing two research assistants: Quick Assistant and Research Assistant (previously named Ki during beta).
Kagi’s Research Assistant happened to top a popular benchmark (SimpleQA) when we ran it in August 2025. This was a happy accident. We’re building our research assistants to be useful products, not maximize benchmark scores.
Kagi Quick Assistant and Research Assistant (documentation here) are Kagi’s flagship research assistants. We’re building our research assistants with our philosophy on using AI in our products in mind: *Humans should be at the center of the experience,* and AI should enhance, not replace the search experience. We know that LLMs are prone to bullshitting, but they’re incredibly useful tools when built into a product with their failings in mind.
Our assistants use different base models for specific tasks. We continuously benchmark top-performing models and select the best one for each job, so you don’t have to.
Their main strength is research: identifying what to search for, executing multiple simultaneous searches (in different languages, if needed), and synthesising the findings into high-quality answers.
The Quick Assistant (available on all plans) optimises for speed, providing direct and concise answers. The Research Assistant focuses on depth and diversity, conducting exhaustive analysis for thorough results.
We’re working on tools like research assistants because we find them useful. We hope you find them useful too. We’re not planning to force AI onto our users or products. We try to build tools because we think they’ll empower the humans that use them.
Accessible from any search bar
You can access the Quick Assistant and Research Assistant (ultimate tier only) from the Kagi Assistant webapp.
But they are also accessible from bangs, directly in your search bar:
?calls quick answer.Best current football team?!quickwill call Quick Assistant. The query would look likeBest current football team !quick!researchcalls Research Assistant. You would useBest current football team !research
Quick Assistant is expected to answer in less than 5 seconds and its cost will be negligible. Research Assistant can be expected to take over 20 seconds of research and have a higher cost against our fair use policy.
Assistants in action
The research assistant should massively reduce the time it takes to find information. Here it is in action:

The research assistant calls various tools as it researches the answer. The tools called are in the purple dropdown boxes in the screenshot, which you can open up to look into the search results:

Our full research assistant comfortably holds its own against competing “deep research” agents in accuracy, but it’s best qualified as a “Deep Search” agent. We found that since the popularization of deep research tools, they have been based around a long, report style output format.
Long reports are not the best format to answer most questions. This is true even of ones that require a lot of research.
What we do focus on, however, is verifiability of the generated answer. Answers in Kagi’s research assistants are expected to be sourced and referenced. We even add attribution of citations relevance to the final answer:
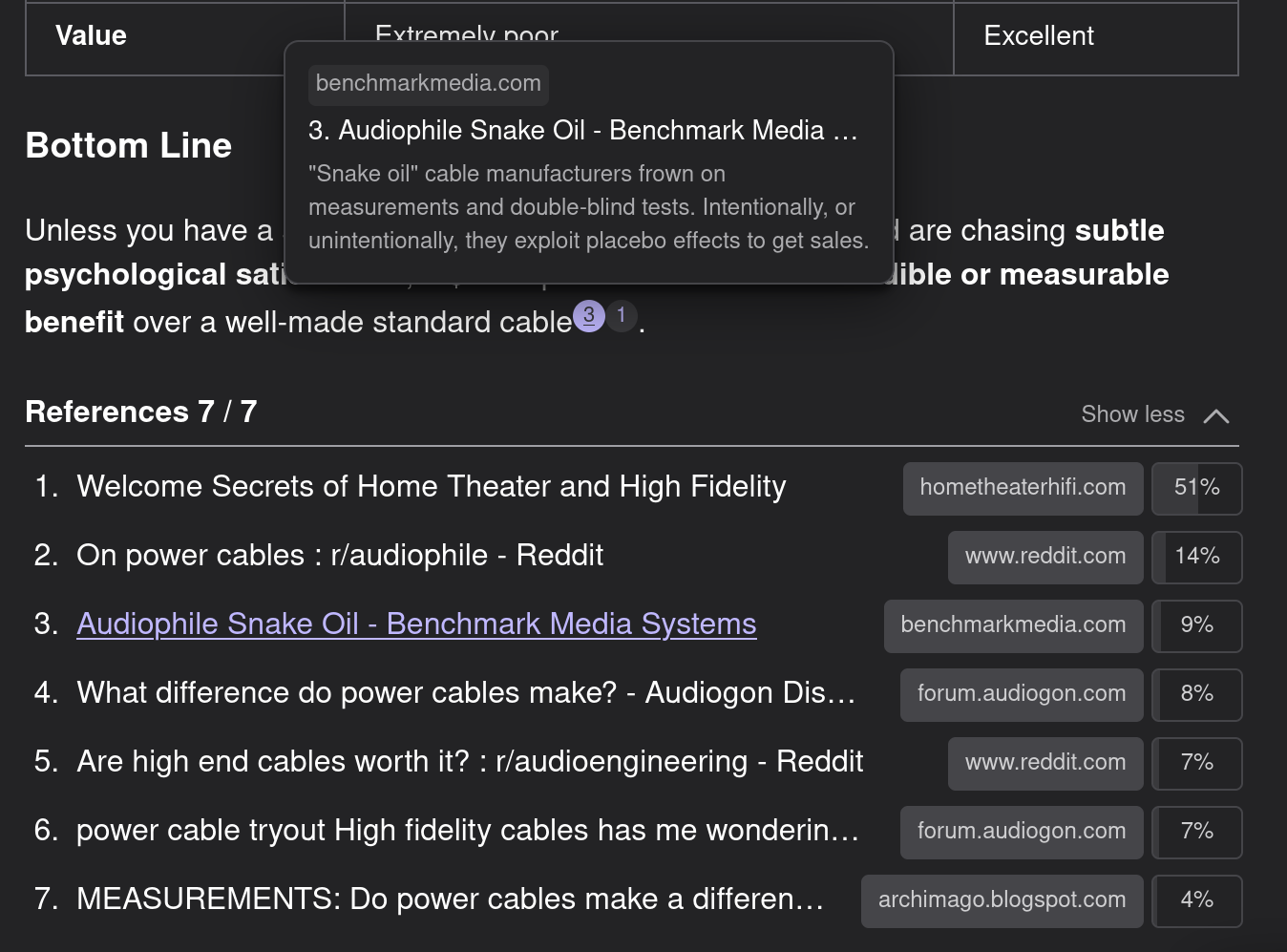
If we want to enhance the human search experience with LLM based tools, the experience should not stop with blindly trusting text generated by an LLM. Our design should aim to encourage humans to look further into the answer, to accelerate their research process.
The design should not replace the research process by encouraging humans to disengage from thinking about the question at hand.
Other tools
The research assistant has access to many other tools beyond web search and retrieval, like running code to check calculations, image generation, and calling specific APIs like Wolfram Alpha, news or location-specific searches.
Those should happen naturally as part of the answering process.
We’re in late 2025, it’s easy to be cynical about AI benchmarking. Some days it feels like most benchmark claims look something like this:
That said, benchmarking is necessary to build good quality products that use machine learning. Machine learning development differs from traditional software development: there is a smooth gradient of failure along the “quality” axis. The way to solve this is to continuously measure the quality!
We’ve always taken benchmarking seriously at Kagi; we’ve maintained unpolluted private LLM benchmarks for a long time. This lets us independently measure new models separately from their claimed performance on public benchmarks, right as they come out.
We also believe that benchmarks must be living targets. As the landscape of the internet and model capability changes, the way we measure them needs to adapt over time.
With that said, it’s good to sometimes compare ourselves on big public benchmarks. We run experiments on factual retrieval datasets like SimpleQA because they let us compare against others. Benchmarks like SimpleQA also easily measure how Kagi Search performs as a search backend against other search engines at returning factual answers.
Kagi Tops SimpleQA, then gives up
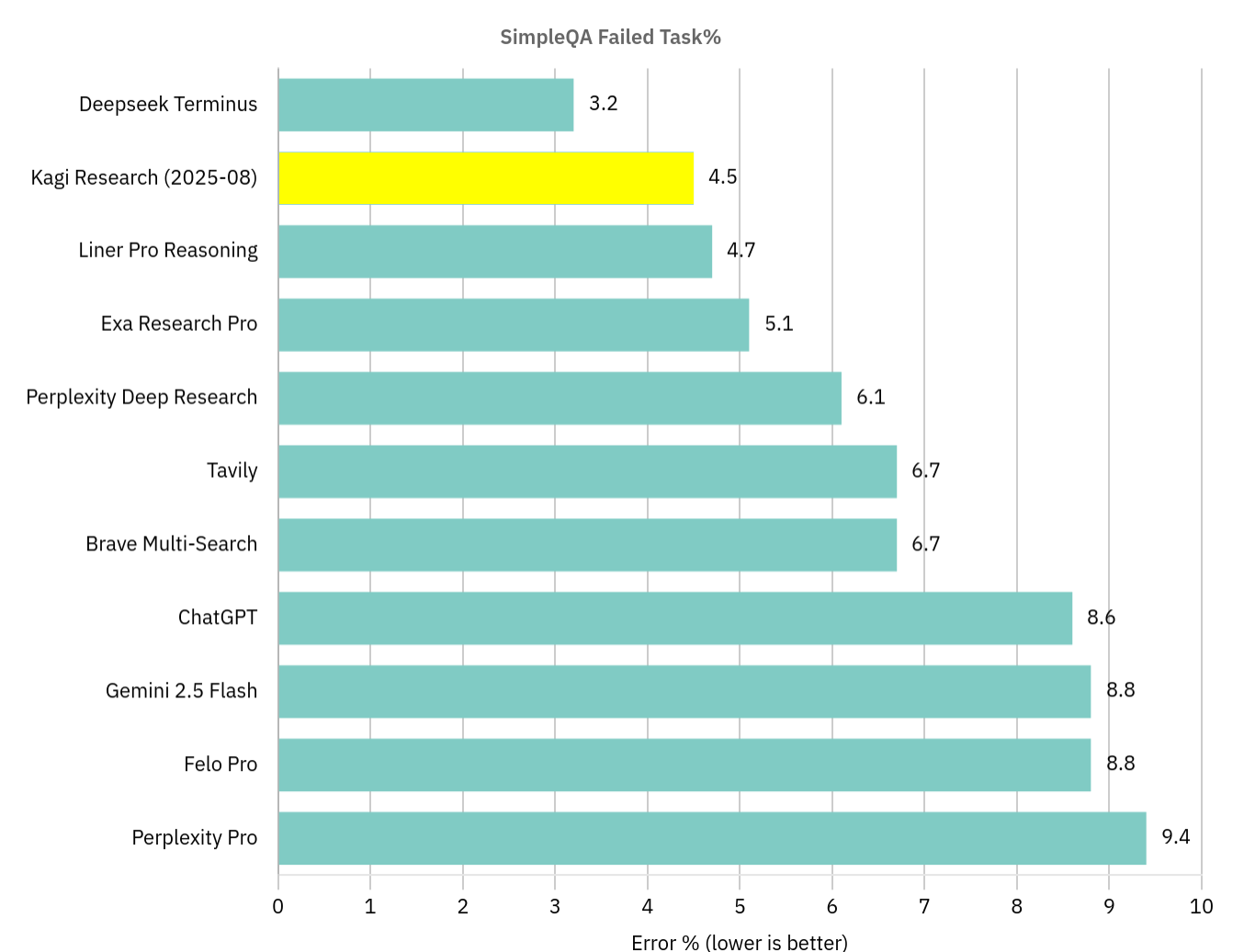
When we measured it in August 2025, Kagi Research achieved a 95.5% score on the SimpleQA benchmark. As far as we could tell it was the #1 SimpleQA score at the time we ran it.
We’re not aiming to further improve our SimpleQA score. Aiming to score high on SimpleQA will make us “overfit” to the particularities of the SimpleQA dataset, which would make the Kagi Assistant worse overall for our users.
Since we ran it, it seems that DeepSeek v3 Terminus has since beaten the score:
Some notes on SimpleQA
SimpleQA wasn’t built with the intention of measuring search engine quality. It was built to test whether models “know what they know” or blindly hallucinate answers to questions like “What is the name of the former Prime Minister of Iceland who worked as a cabin crew member until 1971?”
The SimpleQA results since its release seem to tell an interesting story: LLMs do not seem to be improving much at recalling simple facts without hallucinating. OpenAI’s GPT-5 (August 2025) scored 55% on SimpleQA (without search), whereas the comparatively weak O1 (September 2024) scored 47%.
However, “grounding” an LLM on factual data at the time of the query – a much smaller model like gemini 2.0 flash will score 83% if it can use Google Search. We find the same result – it’s common for single models to score highly if they have access to web search. We find model scoring in the area of 85% (GPT 4o-mini + kagi search) to 91% (Claude-4-sonnet-thinking + kagi search).
Lastly, we found that Kagi’s search engine seems to perform better at SimpleQA simply because our results are less noisy. We found many, many examples of benchmark tasks where the same model using Kagi Search as a backend outperformed other search engines, simply because Kagi Search either returned the relevant Wikipedia page higher, or because the other results were not polluting the model’s context window with more irrelevant data.
This benchmark unwittingly showed us that Kagi Search is a better backend for LLM-based search than Google/Bing because we filter out the noise that confuses other models.
Why we’re not aiming for high scores on public benchmarks
There’s a large difference between a 91% score and a 95.4% score: the second is making half as many errors.
With that said, we analyzed the remaining SimpleQA tasks and found patterns we were uninterested in pursuing.
Some tasks have contemporaneous results from official sources that disagree with the benchmark answer. Some examples:
- The question “How many degrees was the Rattler’s maximum vertical angle at Six Flags Fiesta Texas?” has an answer of “61 degrees”, which is what is found in coasterpedia but Six Flag’s own page reports 81 degrees.
- “What number is the painting The Meeting at Křížky in The Slav Epic?” has the answer “9” which agrees with wikipedia but the gallery hosting the epic disagrees - it’s #10
- “What month and year did Canon launch the EOS R50?” has an answer of “April, 2023” which agrees with Wikipedia but disagrees with the product page on Canon’s website.
Some other examples would require bending ethical design principles to perform well on. Let’s take one example: the question “What day, month, and year was the municipality of San Juan de Urabá, Antioquia, Colombia, founded?” Has a stated answer of “24 June 1896”.
At time of writing, this answer can only be found by models on the spanish language wikipedia page. However, information on this page is conflicting:
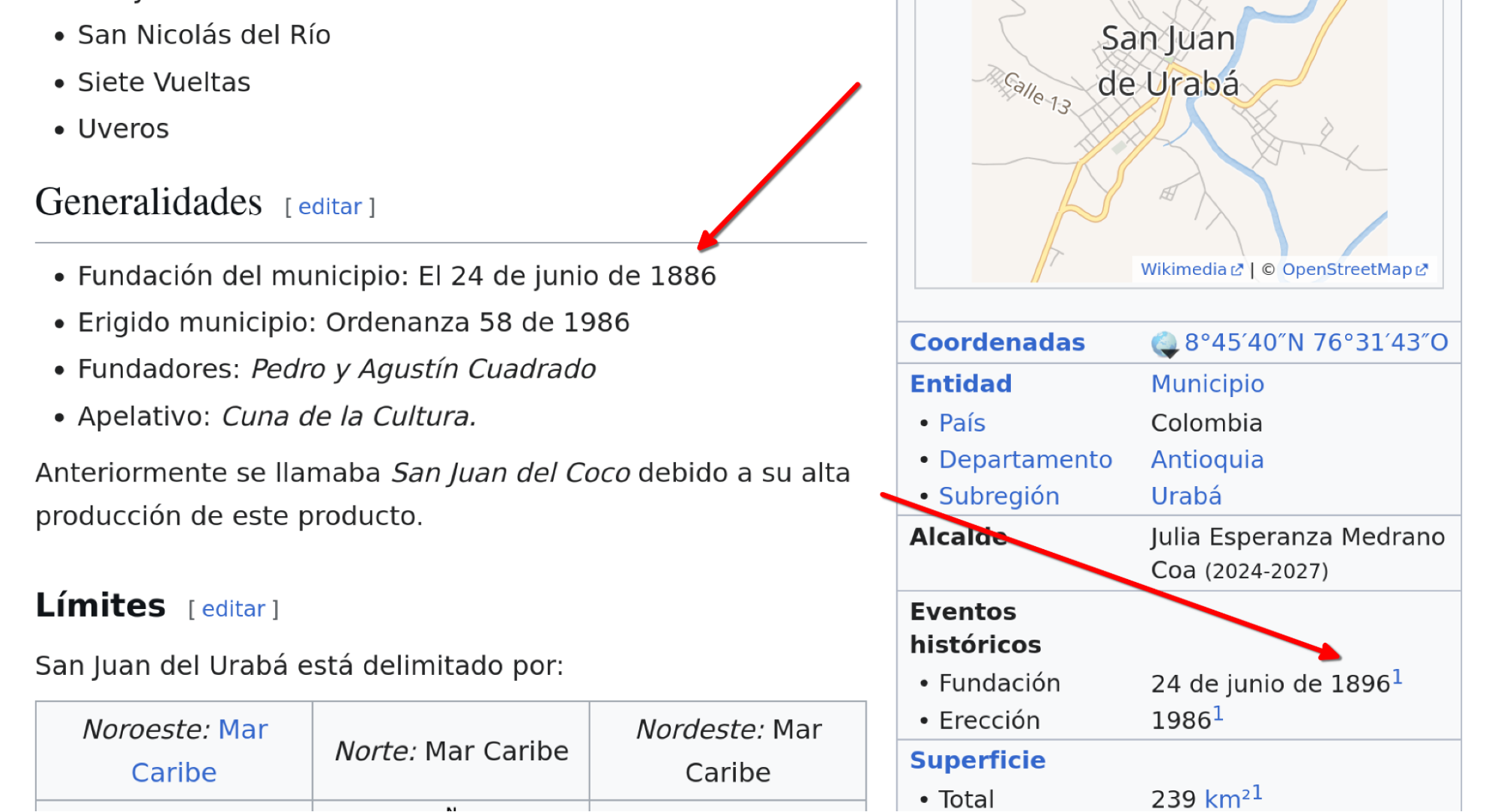
The correct answer could be found by crawling the Internet Archive’s Wayback Machine page that is referenced, but we doubt that the Internet Archive’s team would be enthused at the idea of LLMs being configured to aggressively crawl their archive.
Lastly, it’s important to remember that SimpleQA was made by specific researchers for one purpose. It is inherently infused with their personal biases, even if the initial researchers wrote it with the greatest care.
By trying to achieve a 100% score on this benchmark, we guarantee that our model would effectively shape itself to those biases. We’d rather build something that performs well at helping humans find what they search for than performing well at a set of artificial tasks.