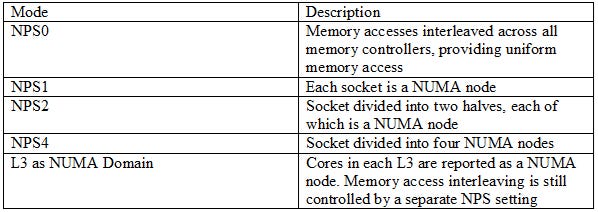
NUMA, or Non-Uniform Memory Access, lets hardware expose affinity between cores and memory controllers to software. NUMA nodes traditionally aligned with socket boundaries, but modern server chips can subdivide a socket into multiple NUMA nodes. It’s a reflection of how non-uniform interconnects get as core and memory controller counts keep going up. AMD designates their NUMA modes with the NPS (Nodes Per Socket) prefix.
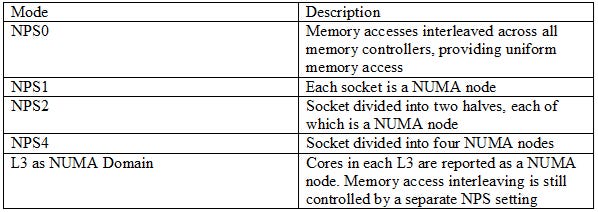
NPS0 is a special NUMA mode that goes in the other direction. Rather than subdivide the system, NPS0 exposes a dual socket system as a single monolithic entity. It evenly distributes memory accesses across all memory controller channels, providing uniform memory access like in a desktop system. NPS0 and similar modes exist because optimizing for NUMA can be complicated and time intensive. Programmers have to specify a NUMA node for each memory allocation, and take are to minimize cross-node memory accesses. Each NUMA node only represents a fraction of system resources, so code pinned to a NUMA node will be constrained by that node’s CPU core count, memory bandwidth, and memory capacity. Effort spent getting an application to scale across NUMA nodes might be effort not spent on a software project’s other goals.
A massive thank you goes to Verda (formerly DataCrunch) for proving an instance with 2 AMD EPYC 9575Fs and 8 Nvidia B200 GPUs. Verda gave us about 3 weeks with the instance to do with as we wished. While this article looks at the AMD EPYC 9575Fs, there will be upcoming coverage of the B200s found in the VM.
This system appears to be running in NPS0 mode, giving an opportunity to see how a modern server acts with 24 memory controllers providing uniform memory access.
A simple latency test immediately shows the cost of providing uniform memory access. DRAM latency rises to over 220 ns, giving a nearly 90 ns penalty over the EPYC 9355P running in NPS1 mode. It’s a high penalty compared to using the equivalent of NPS0 on older systems. For example, a dual socket Broadwell system has 75.8 ns of DRAM latency when each socket is treated as a NUMA node, and 104.6 ns with uniform memory access[1].
NPS0 mode does have a bandwidth advantage from bringing twice as many memory controllers into play. But the extra bandwidth doesn’t translate to a latency advantage until bandwidth demands reach nearly 400 GB/s. The EPYC 9355P seems to suffer when a latency test thread is mixed with bandwidth heavy ones. A bandwidth test thread with just linear read patterns can achieve 479 GB/s in NPS1 mode. However, my bandwidth test produces low values on the EPYC 9575F because not all test threads finish at the same time. I avoid this problem in the loaded memory latency test, because I have bandwidth load threads check a flag. That lets me stop all threads at approximately the same time.

Per-CCD bandwidth is barely affected by the different NPS modes. Both the EPYC 9355P and 9575F use “GMI-Wide” links for their Core Complex Dies, or CCDs. GMI-Wide provides 64B/cycle of read and write bandwidth at the Infinity Fabric clock. On both chips, each CCD enjoys more bandwidth to the system compared to standard “GMI-Narrow” configurations. For reference, a GMI-Narrow setup running at a typical desktop 2 GHz FCLK would be limited to 64 GB/s of read and 32 GB/s of write bandwidth.
Higher memory latency could lead to lower performance, especially in single threaded workloads. But the EPYC 9575F does surprisingly well in SPEC CPU2017. The EPYC 9575F runs at a higher 5 GHz clock speed, and DRAM latency is only one of many factors that affect CPU performance.
Individual workloads show a more complex picture. The EPYC 9575F does best when workloads don’t miss cache. Then, its high 5 GHz clock speed can shine. 548.exchange2 is an example. On the other hand, workloads that hit DRAM a lot suffer in NPS0 mode. 502.gcc, 505.mcf, and 520.omnetpp see the EPYC 9575F’s higher clock speed count for nothing, and the higher clocked chip underperforms compared to 4.4 GHz setups with lower DRAM latency.
SPEC CPU2017’s floating point suite also shows diverse behavior. 549.fotonik3d and 554.roms suffer in NPS0 mode as the EPYC 9575F struggles to keep itself fed. 538.imagick plays nicely to the EPYC 9575F’s advantages. In that test, high cache hitrates let the 9575F’s higher core throughput shine through.
NPS0 mode performs surprisingly well in a single threaded SPEC CPU2017 run. Some sub-tests suffer from higher memory latency, but enough other tests benefit from the higher 5 GHz clock speed to make up the difference. It’s a lesson about the importance of clock speeds and good caching in a modern server CPU. Those two factors go together, because faster cores only provide a performance advantage if the memory subsystem can feed them. The EPYC 9575F’s good overall performance despite having over 220 ns of memory latency shows how good its caching setup is.
As for running in NPS0 mode, I don’t think it’s worthwhile in a modern system. The latency penalty is very high, and bandwidth gains are minor for NUMA-unaware code. I expect those latency penalties to get worse as server core and memory controller counts continue to increase. For workloads that need to scale across socket boundaries, optimizing for NUMA looks to be an unfortunate necessity.
Again, a massive thank you goes to Verda (formerly DataCrunch) without which this article, and the upcoming B200 article, would not be possible!