Modern AI appears remarkably human. We can talk to LLMs like friends, get instant relationship advice, and send them photos of our outfits. And just like humans, these models aren't perfect. They sometimes misremember facts, make simple arithmetic errors, and over-agree with our favorite conspiracy theories.
We argue this similarity between humans and AI is largely superficial. In fact, we believe that AI systems will become less human-like as they continue to scale and improve in their capabilities. This has important implications for alignment and interpretability as AI plays an increasingly powerful role in society.
Specifically, we argue that humans and LLMs are fundamentally different computational architectures, each operating under distinct constraints and algorithms. Even if their outputs become more similar with scale, the underlying mechanisms remain separable. To make this distinction clearer, we propose a process-focused framework for evaluating LLM-human likeness.
Humans vs. LLMs
When a human sits down to write even a simple email, they draw on a small, personal set of memories: their relationship with the recipient, past interactions, and immediate goals. They think briefly, using limited attention and working memory, and then craft a message that fits the social context. An LLM can also produce a useful email, but it does so under entirely different constraints. Instead of lived experience, it relies on patterns extracted from billions of text examples - far more than any human could ever encounter - and maps the prompt into a high-dimensional representation to generate the next token. In other words, humans and LLMs may produce similar outputs, but the computational resources, amount and nature of available data, time pressures, and underlying reasoning algorithms they use are fundamentally different. The following sections outline these contrasts in turn.
Computational constraints
Humans: Cognitive theorists like Simon, Gigerenzer, and Griffiths argue human reasoning is best understood as bounded - we make good-enough decisions with limited computational resources. Even though the brain is massively parallel, with ~10¹¹ neurons and ~10¹⁴-10¹⁵ synapses, its effective, moment-to-moment computation is still bottlenecked by metabolic limits, slow spike transmission, and small capacity buffers. A useful analogy is that while the brain's "parameter count" (synapses) is enormous, its usable working compute at any given time is restricted, making online reasoning resource-limited.
LLMs: In principle, LLMs can be scaled almost arbitrarily in ways biological brains cannot: more parameters, more training compute, more depth. They are not bound by biology, though of course in practice they are bounded by hardware, energy and training budgets. Current 70-billion-parameter models are tiny compared to the human brain. But unlike humans, LLMs can scale up as much as we want.
Data constraints
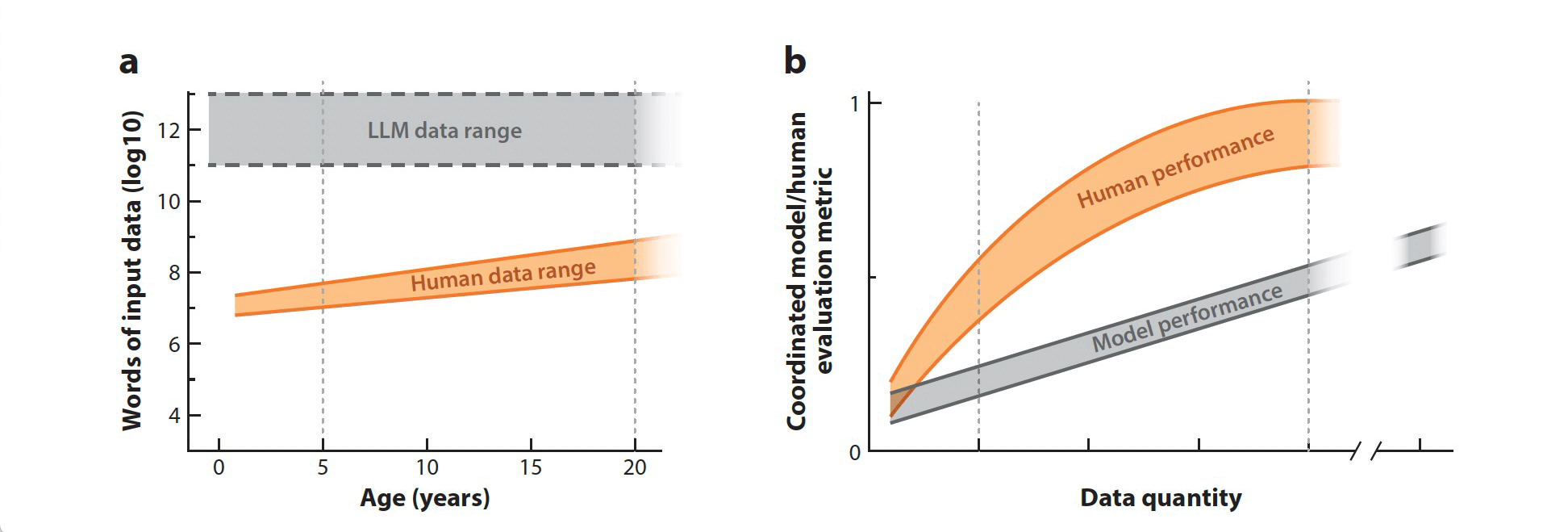
Humans: We are constantly hit with a large, continuous stream of sensory input, but we cannot process or store more than a very small part of it. Vision alone delivers millions of information bits per second, and almost all of it is discarded automatically. What gets through is filtered by attention, relevance to survival, prior knowledge, and social context. So while humans technically encounter huge amounts of information, the part that enters memory and shapes learning is tiny compared to what AI systems can retain (See Figure 1).
LLMs: Compared to humans, LLMs have effectively unbounded training data. They are trained on billions of text examples covering countless topics, styles, and domains. Their exposure is far broader and more uniform than any human's, and not filtered through lived experience or survival needs.

Time constraints
Humans: Humans often have to act quickly. Deliberation is slow, so many decisions rely on fast, heuristic processing. In many situations (danger, social interaction, physical movement), waiting for more evidence simply isn't an option.
LLMs: An LLM only needs to respond fast enough to avoid frustrating the user. Seconds or minutes (for larger reasoning models) may feel slow, but these are generous time budgets compared to biological reaction times or most real-world decision pressures.
Algorithm differences
Humans: Human thinking works in a slow, step-by-step way. We pay attention to only a few things at a time, and our memory is limited - try holding several new ideas in mind at once and you'll feel them start to slip unless you keep rehearsing them. We compress information, rely on cues to remember things, and update our thoughts one step after another. This makes us efficient, but it also means we can't process everything at once.
LLMs: LLMs process information very differently. They look at everything in parallel, all at once, and can use the whole context in one shot. Their “memory” is stored across billions of tiny weights, and they retrieve information by matching patterns, not by searching through memories like we do. Researchers have shown that LLMs automatically learn specific little algorithms (like copying patterns or doing simple lookups), all powered by huge matrix multiplications running in parallel rather than slow, step-by-step reasoning.
Together, these divergent constraints—computational, data, time, and algorithmic—give rise to fundamentally distinct problem-solving strategies. Humans evolved heuristics optimized for survival under tight resource limits, while LLMs have developed strategies optimized for next-token prediction across vast corpora.
Can we eliminate the human-LLM gap?
Given these fundamental differences, a natural question arises: can we engineer AI systems to process information more like humans do? Two approaches seem most promising: scaling models to match human-level performance, and alignment techniques designed to shape model behavior toward human preferences.
Scale
Early LLM generations like GPT 2 were obviously limited - they struggled with multi-turn conversations, often had repetitive answers and failed at basic reasoning. Communicating with them mostly felt extremely unnatural. Given the capabilities of current models (GPT-5.1, Claude Opus 4.5, Gemini 3), does this mean that scale is gradually pushing LLMs toward human-like cognition? We believe It’s quite unlikely, as increasing the model size, adding more training data, or adopting more sophisticated training recipes does not alter the fundamental differences outlined in Section 1. There’s evidence from multiple domains that supports this:
- Namazova et al. (2025) find that models cannot reproduce key behavioral properties in generative tasks, regardless of scale, even when fine-tuned to predict human behavior.
- Gao (2025) shows that larger models diverge more, not less, from human strategies in certain game-theoretic settings.
- Duan et al. (2024) find that increases in model size improve text prediction, but do not make language use more human-like in pragmatic or social contexts.
- Schröder et al. (2025) show that LLMs fail to replicate human moral judgment patterns.

Alignment
Alignment methods aim to make models behave more like humans. The most common approach, RLHF (Reinforcement Learning from Human Feedback), uses human preference ratings as feedback to the LLM, with the goal of adjusting the model's responses.
RLHF primarily tweaks behavioral outputs, and doesn't really touch the underlying information-processing mechanisms (Casper et al., 2023). This is very different from, for example, how we learn what's appropriate or not as children: children learn social norms by asking "why" because they are building internal causal and social models.
By contrast, RLHF teaches models which responses receive approval. The consequence of shaping surface behavior without instilling the deeper principles that govern human reasoning is that a model can appear aligned in familiar settings yet behave unpredictably when the situation changes. Methods like RLAIF and Constitutional AI (Bai et al., 2022) offer rule-based guidance rather than human ratings, but these approaches offer only limited guarantees, don't consistently work for smaller models, and still struggle when the model encounters something outside its training conditions.
The fundamental issue is that many alignment approaches and evaluations rely on surface-level agreement: does the model give the same answer as a human? But this tells us nothing about the process generating the response. Two systems can produce identical answers via entirely different mechanisms, and those similarities often disappear under novelty, ambiguity, or shifted incentives. Because alignment fine-tunes outputs rather than the underlying process, it cannot ensure that models reason, or will generalize, like humans. In short: both scaling and alignment optimize what the model says, not how it thinks.
How can we test if LLMs are human-like?
As we argued in Section 2, focusing only on whether an LLM's answers look human-like obscures the deeper differences in how the two systems actually process information. To evaluate human-likeness at the process level we need tools that can reveal how LLMs form decisions, update beliefs, and navigate uncertainty.
Computational cognitive science already provides a framework for this. Cognitive scientists design carefully controlled tasks to probe the mechanisms behind human thought. We can adapt this approach for LLMs by building "behavioral sandboxes" - task environments specifically designed to reveal the model's decision-making process, not just the final answer.
These environments should support:
- Process tracking - capturing intermediate steps, continuous behaviors, or reasoning traces so we can see how the model arrives at a solution.
- Ambiguity, novelty, and underspecified goals - testing models under the kinds of pressures humans face, where the correct path isn't obvious.
- Dynamic feedback - tasks where the context or goals change mid-interaction, forcing the model to update its strategy.
- Evaluation beyond accuracy - using richer metrics suited for generative systems, not just right/wrong scoring.
Conclusion
LLMs may be becoming less human in their internal workings as they scale, but that does not make them opaque or ungovernable. At Roundtable, we are using the insights outlined in this post to build Proof of Human—an invisible, continuous API for verifying human identity. Contact us today if you'd like to learn more.
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Hernandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., ... Kaplan, J., 2022. Constitutional AI: Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073. https://arxiv.org/abs/2212.08073
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., Wang, T., Marks, S., Segerie, C.-R., Carroll, M., Peng, A., Christoffersen, P., Damani, M., Slocum, S., Anwar, U., ... Hadfield-Menell, D., 2023. Open problems and fundamental limitations of reinforcement learning from human feedback. Transactions on Machine Learning Research. https://arxiv.org/abs/2307.15217
Duan, X., Xiao, B., Tang, X., & Cai, Z. G., 2024. HLB: Benchmarking LLMs' Humanlikeness in Language Use. arXiv preprint arXiv:2409.15890. https://arxiv.org/abs/2409.15890
Frank, M. C. & Goodman, N. D., 2025. Cognitive modeling using artificial intelligence. Annual Review of Psychology (forthcoming). https://worthylab.org/wp-content/uploads/2025/10/frank-goodman-2025.pdf
Gao, Y., Lee, D., Burtch, G., & Fazelpour, S., 2025. Take caution in using LLMs as human surrogates. Proceedings of the National Academy of Sciences, Vol 122(24), e2501660122. DOI: 10.1073/pnas.2501660122
Namazova, S., Brondetta, A., Strittmatter, Y., Shenhav, A., & Musslick, S., 2025. Not Yet AlphaFold for the Mind: Evaluating Centaur as a Synthetic Participant. arXiv preprint arXiv:2508.07887. https://arxiv.org/abs/2508.07887
Schröder, S., Morgenroth, T., Kuhl, U., Vaquet, V., & Paaßen, B., 2025. Large language models do not simulate human psychology. arXiv preprint arXiv:2508.06950. https://arxiv.org/abs/2508.06950
Milena Rmus, Mathew Hardy, and Mayank Agrawal, work at Roundtable Technologies Inc., where they are building Proof of Human, an invisible authentication system for the web. Previously, they completed PhDs in cognitive science at the University of California, Berkeley (Milena) and Princeton University (Matt and Mayank).