Two months ago I wrote about why we decided to stop treating pretraining like someone else's job.
At the time, Trinity Nano Preview and Trinity Mini had just released, and Trinity Large had started training. We were in the middle of our first run so big that you either laughed or got nauseous. Frankly, I felt either we’d end up with a really great base model or fall flat on our faces with a tired wallet.
Little did I know, we’d get both.
Here’s what we’re shipping, what surprised us, what broke, and what it took to make a 400B sparse MoE behave.
We're putting out three variants: Trinity-Large-Preview is lightly post-trained and chat-ready, Trinity-Large-Base is our best pretraining checkpoint after the full 17T recipe, and TrueBase is an early checkpoint from the same run at 10T tokens, without any instruct data or LR anneals. What many would consider a true base model.
Trinity-Large is a 400B parameter sparse MoE with 13B active parameters per token. It uses 256 experts with 4 experts active per token. That sparsity ratio is pretty high compared to our peers, save for Llama-4-Maverick:
We originally aimed for a slightly different total size (420B), but we ended up increasing the number of dense layers (from 3 to 6) to help keep routing stable at this sparsity.
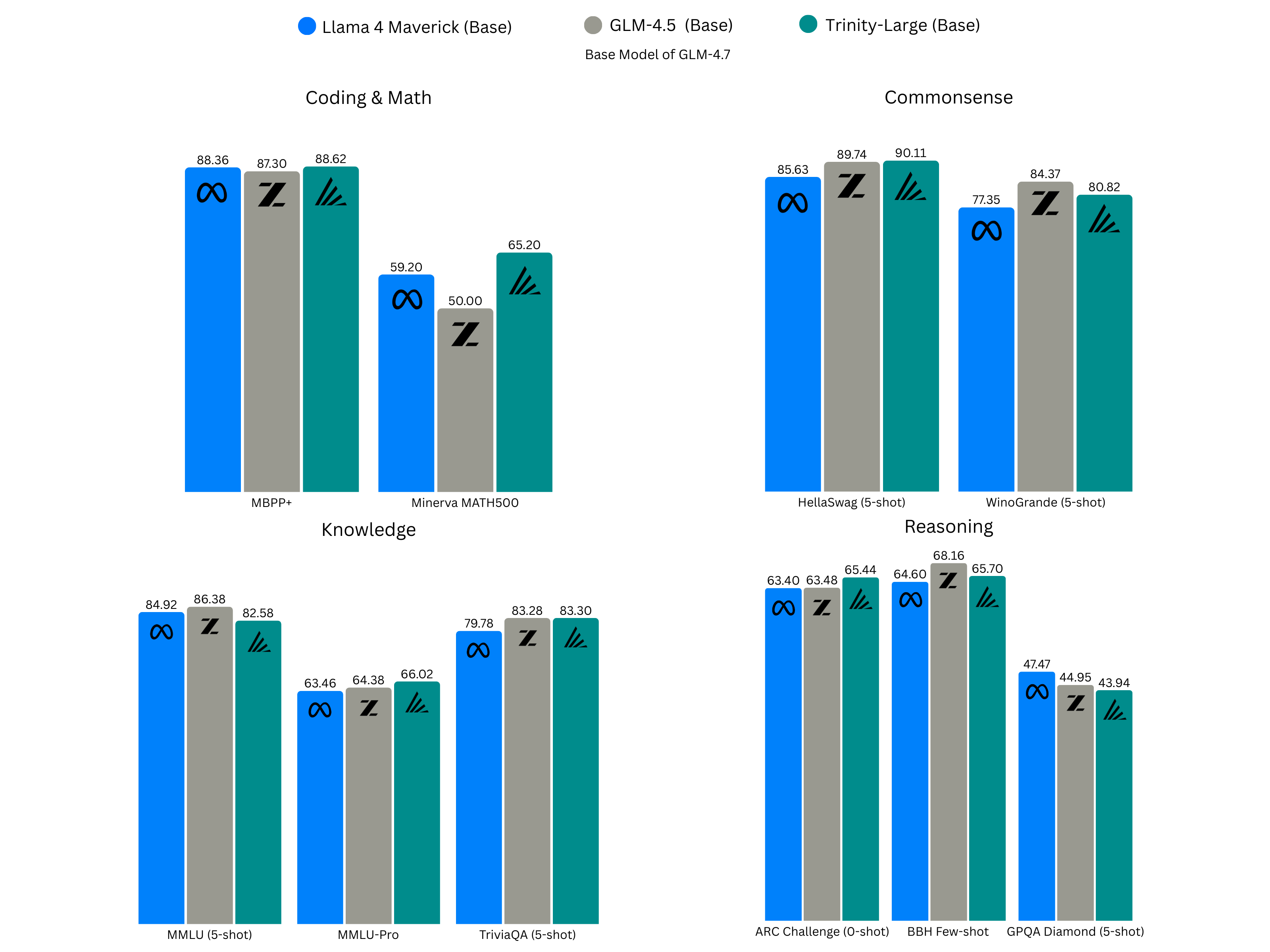
Trinity-Large-Base is a true frontier-class foundation model. We match and exceed our peers in open-base models across a wide range of benchmarks, including math, coding, scientific reasoning, and raw knowledge absorption.
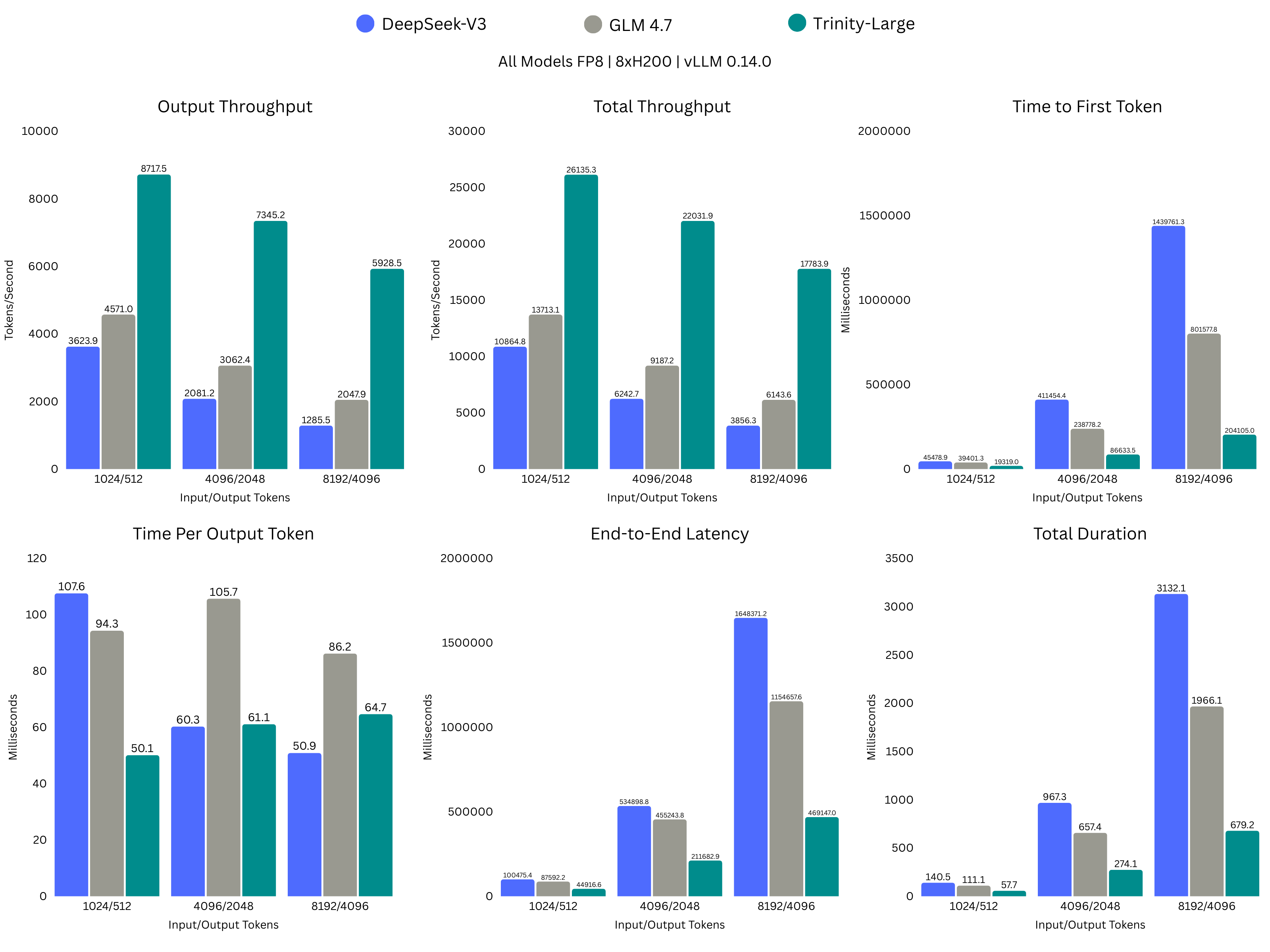
Inference efficiency
We trained on 2048 Nvidia B300 GPUs. As far as we can tell, it’s the largest (publicly stated, at least) pretraining run done on these machines. That means two things:
- They’re wicked fast.
- They’re not cheap.
Therefore, we had to make the most of the money we allotted to these machines, which was just over 30 days. Ridiculously fast for a run of this scale, so efficient training was the name of the game. Hence, the level of sparsity referred to above. Combined with our efficient attention outlined in our technical report, this enabled us to train and, by extension, run inference much faster than our peers in the same weight class. All while not sacrificing performance. Roughly 2-3x faster for the same hardware.
Momentum-based expert load balancing
We keep MoE routing under control by nudging each expert’s router bias up or down depending on whether that expert is being over- or under-used. The update is capped with a tanh clip so it stays bounded, and we add momentum to smooth it across steps and avoid step-to-step ping-pong. On top of that, we include a small per-sequence balance loss so load is not only balanced in expectation across the batch, but also within individual sequences.
z-loss
We use z-loss to stop the LM-head logits from drifting upward during training. It is a lightweight regularizer that keeps logit scale from creeping up without bound. We also log basic logit stats (for example max and mean) as a simple early warning for instability.
The exact equations are in the technical report.
Our fastest configuration was HSDP with expert parallelism set to 8, which gave us 2048 data-parallel ranks. In that setup, we pushed throughput further by increasing batch size after 5T tokens of training. We were comfortable doing that because the model is highly sparse, Muon supports a larger critical batch size than AdamW, and the MiniMax-01 paper suggests batch-size scaling remains workable in this regime.
In the main run, once we had stability dialed in, the loss curve stayed smooth the whole way through. You can see clear phase transitions, no spikes, and a steady march to the end.
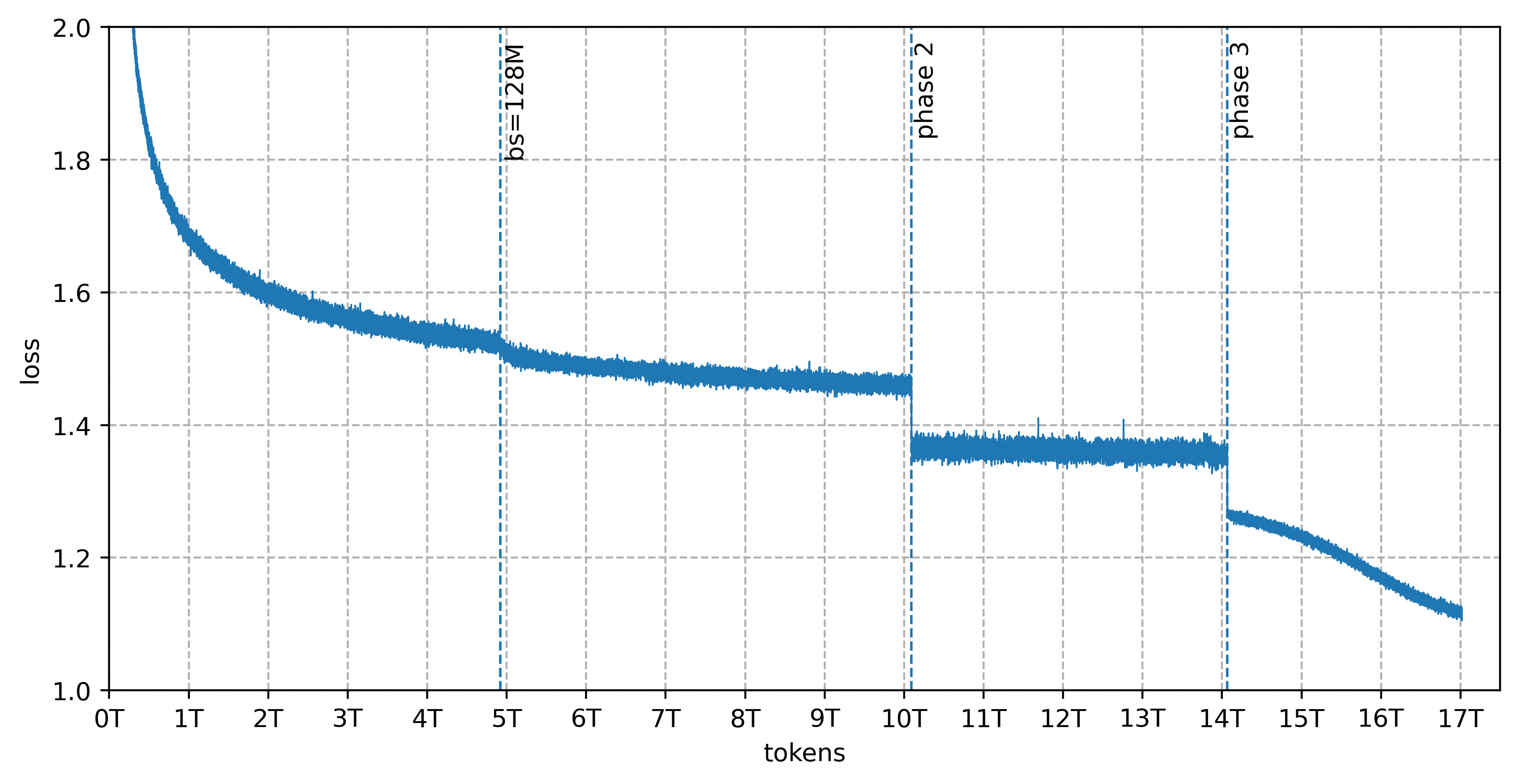
The full pretraining run finished in 33 days. That's pre-training only; it doesn't include context extension or post-training.
Data
Trinity Large was trained on 17T tokens of data curated by DatologyAI, split across three phases of 10T, 4T, and 3T tokens. This mix uses state-of-the art programming, STEM, reasoning, and multilingual data curation, targeting 14 non-English languages. Notably, over 8 trillion tokens of synthetic data were generated for this dataset across web, code, math, reasoning, and multilingual domains, using a breadth of state-of-the-art rephrasing approaches.
A less advanced version of this curation approach worked well for smaller models like Trinity Nano and Trinity Mini, but we wanted to shoot for the moon with Trinity Large. So DatologyAI delivered a number of curation advancements specifically for inclusion into Trinity Large. There’s always a leap of faith when doing something for the first time in public, but the effectiveness of the curation approach as a whole is reflected in the downstream evaluations, where the Trinity Large-Base demonstrates frontier-level performance across the targeted capability domains.
Trinity-Large-Preview
The preview we’re releasing today is not a reasoning model. A benefit beyond production inference efficiency is that it also carries over into RL, enabling quicker rollouts for a given total parameter size. But it’s equally as sensitive as pretraining was, and while it’s currently undergoing further post-training and will be a full-fledged reasoning model upon release, we believe there’s a fine line between intelligence and usefulness, and while the reasoning variant is very intelligent, it needs longer in training before it becomes maximally useful given the extra tokens per output.
As such, to maximize usefulness and provide an early checkpoint, Preview is a non-reasoning, or “instruct,” model. It’s a particularly light post-training, as most of our compute went towards pre-training and is continuing with the reasoning version. It is an extremely capable model for its size and gave us the opportunity to flex some old-school post-training muscles we haven’t had the chance to flex in quite some time. It excels in creative writing, storytelling, role-play, chat scenarios, and real-time voice assistance, better than your average reasoning model usually can. But we’re also introducing some of our newer agentic performance. It was trained to navigate well in agent harnesses like OpenCode, Cline, and Kilo Code, and to handle complex toolchains and long, constraint-filled prompts. It certainly isn’t perfect, but we cannot wait to see what you do with it. It’s free in OpenRouter until Large (non-preview) fully releases.
It’s currently roughly in line with Llama-4-Maverick’s Instruct model across standard academic benchmarks, and we’ll update this blog over time with more evaluations.
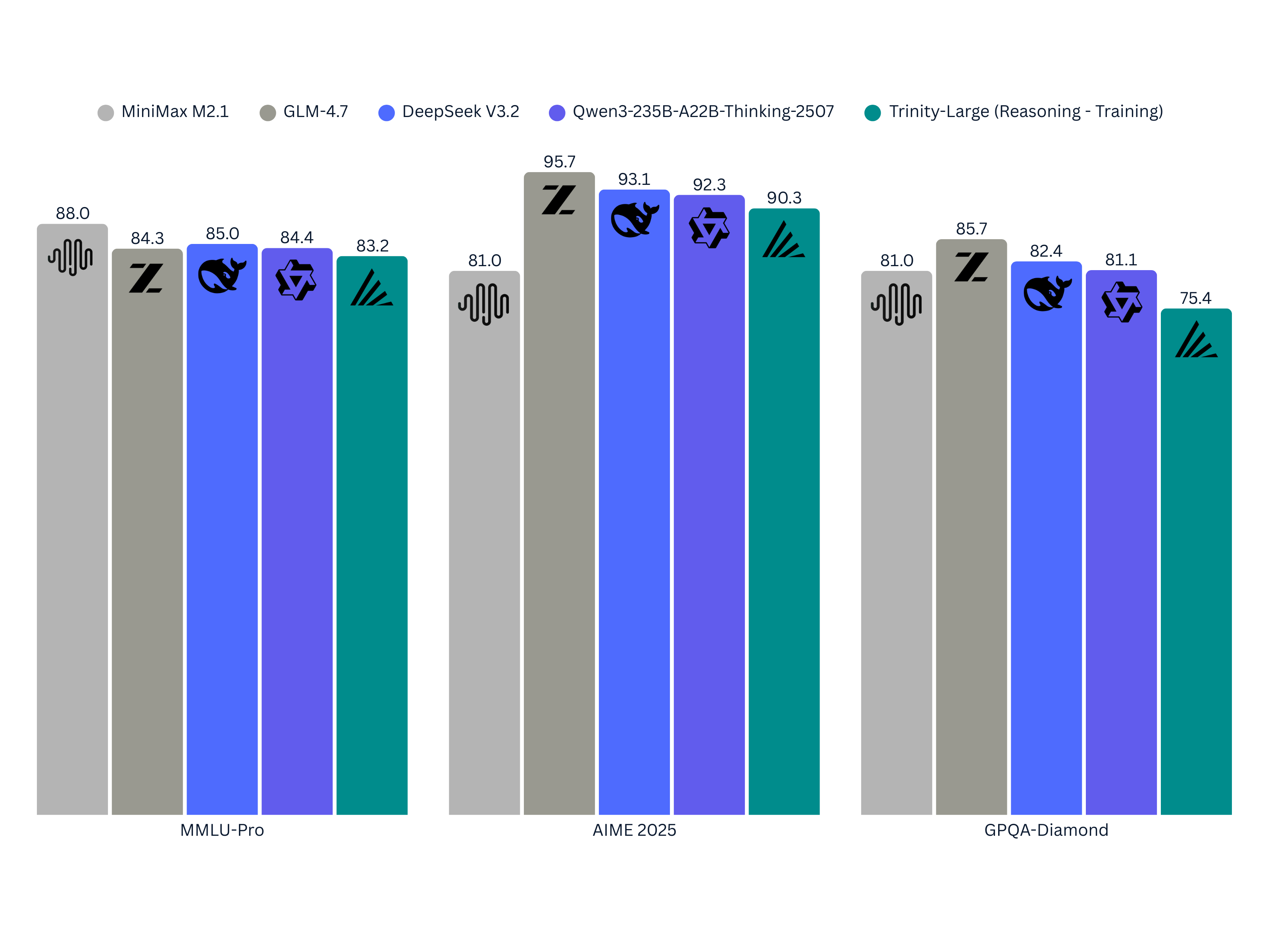
But we like to tease, so I’ll leave you with some early evaluations of the reasoning Trinity-Large. These are not exhaustive, and by no means representative of the full capabilities of any of these models, but it is a fun look at how we plan to take this model.
Cost
When we started this run, we had never pretrained anything remotely like this before.
There was no guarantee this would work. Not the modeling, not the data, not the training itself, not the operational part where you wake up, and a job that costs real money is in a bad state, and you have to decide whether to restart or try to rescue it.
All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million. 4 Models got us here in 6 months.
That number is big for us. It's also small compared to what frontier labs spend just to keep the lights on. We don't have infinite retries.
What is TrueBase?
One more thing about Trinity-Large-TrueBase.
Most "base" releases have some instruction data baked in. TrueBase doesn't. It's 10T tokens of pretraining on a 400B sparse MoE, with no instruct data and no LR annealing.
If you're a researcher who wants to study what high-quality pretraining produces at this scale—before any RLHF, before any chat formatting—this is one of the few checkpoints where you can do that. We think there's value in having a real baseline to probe, ablate, or just observe. What did the model learn from the data alone? TrueBase is where you answer that question.
Where to use it
OpenRouter has Trinity-Large-Preview available now, free during the preview period (through at least February 2026). If you want to kick the tires without spinning up infrastructure, that's the fastest path.
We also worked with Kilo Code, Cline, and OpenCode to have integrations ready at launch. If you're already using one of those for coding, Trinity Large should show up as an option. This is an extremely young post-train, in the scheme of RL runs that go on for months at a time, like our peers. We’ll get there soon, but we’re oh-so-proud to have our own model to do it with. Expect rough edges, specifically in coding agents. For everyday agents, though, it’s outstanding.
Context and hosting
Trinity Large natively supports 512k context.
The preview API is running at 128k context with 8-bit quantization as we tune our inference infrastructure. This release is as much a preview of our hosting platform as it is a model launch.
Try Trinity Large
If you put this model into something real and it breaks, tell us. The fastest way for open models to get better is for people to actually use them, hard, in places that don't look like benchmarks.
We like to say that we built Trinity so you can own it. Being able to say that about a frontier-level model is something we’re immeasurably proud of.