 LG电子宣布将暂停所有使用住宅代理软件开发工具包(SDK)的智能电视应用。此前,Spur进行的一项安全研究显示,LG webOS应用商店中超过42%的应用(三星Tizen OS中超过四分之一的应用)正将电视变成“常驻”代理节点。这些SDK允许第三方通过用户设备路由互联网流量,通常用于协助数据抓取。
LG表示,住宅代理网络并非其电视的预设用途。目前,该公司正在审查其应用商店,并要求开发者删除这些组件,否则将面临停用处理。安全专家警告称,这些代理功能往往隐藏在游戏和屏保等应用中,存在严重的隐私风险,因为用户(包括未成年人)可能在不知情的情况下同意将电视变成代理节点。
尽管LG的打击行动对消费者安全而言是积极的一步,但该公司同时也因未经用户授权,通过Windows更新在其高端显示器中捆绑不必要的McAfee推广软件而受到批评。
LG电子宣布将暂停所有使用住宅代理软件开发工具包(SDK)的智能电视应用。此前,Spur进行的一项安全研究显示,LG webOS应用商店中超过42%的应用(三星Tizen OS中超过四分之一的应用)正将电视变成“常驻”代理节点。这些SDK允许第三方通过用户设备路由互联网流量,通常用于协助数据抓取。
LG表示,住宅代理网络并非其电视的预设用途。目前,该公司正在审查其应用商店,并要求开发者删除这些组件,否则将面临停用处理。安全专家警告称,这些代理功能往往隐藏在游戏和屏保等应用中,存在严重的隐私风险,因为用户(包括未成年人)可能在不知情的情况下同意将电视变成代理节点。
尽管LG的打击行动对消费者安全而言是积极的一步,但该公司同时也因未经用户授权,通过Windows更新在其高端显示器中捆绑不必要的McAfee推广软件而受到批评。
LG 正计划在其智能电视的应用程序中禁止使用住宅代理服务。此举旨在应对一种充满争议的做法,即通过将用户的家庭网络连接转变为第三方流量的代理节点,从而将用户“货币化”。
Hacker News 上关于此新闻的讨论重点关注了以下几个核心问题:
* **安全与欺诈:** 评论者指出,这些代理常被恶意攻击者用于僵尸网络活动、社交媒体操纵和欺诈行为。参与此类网络的用户,其家庭 IP 地址面临被标记为非法活动的风险。
* **缺乏透明度:** 尽管一些开发者声称他们提供了知情同意选项(例如选择使用代理来代替观看广告),但许多用户可能并未完全理解他们实际上是在自愿贡献网络供外部使用。
* **系统安全:** 一些用户认为,像游戏机(PS5/Xbox)这样的独立设备比智能电视操作系统更安全、更值得信赖,后者往往缺乏严格的安全监管。
总的来说,社区普遍认为 LG 的这一决定是一项积极且早该采取的举措,有助于改善用户隐私和网络安全,有效地遏制了许多人认为属于掠夺性的行为。

太空食品研究过去主要关注军事化的效率和热量摄入,如今正转向对文化与身份的保护。研究员兼艺术家科布伦茨(Coblentz)挑战了“宇航员即机器”的叙事,认为在孤立的太空中,食物是与人类联系的重要纽带。 虽然像美国国家航空航天局(NASA)这样的机构坚持提供标准化的安全测试菜单,但日本宇宙航空研究开发机构(JAXA)和韩国等则优先考虑文化代表性,甚至专门为轨道飞行研发了泡菜等民族主食。科布伦茨本人的工作——包括一个在国际空间站发酵味噌的里程碑式项目——探索了活性食物在微重力环境下的表现。 在实验室之外,科布伦茨还在北极斯瓦尔巴群岛等偏远环境中进行实地研究。通过观察极度孤立环境下的科学家如何不遗余力地获取家乡风味,她强调了在严酷环境中,人类的生存与其说是孤独的挑战,不如说是一种社会性的努力。她的研究表明,在未来的太空旅行中,食物不应仅仅是燃料;它应当是环境、人类微生物群以及我们从地球带来的文化之间一种动态的、鲜活的关系。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
去过太空的味噌 (ambrook.com)
5 分,作者:surprisetalk,1 小时前 | 隐藏 | 过往 | 收藏 | 讨论 | 帮助
考虑申请 YC 2026 年秋季班!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
 在林赛·格雷厄姆参议员去世后,他的妹妹达琳·格雷厄姆(原名诺多内)正式宣布竞选其参议员席位。在得到唐纳德·特朗普的支持下,她正在寻求完整的六年任期,尽管她此前并无担任民选公职的经验。为了利用其兄长的政治品牌,她已将姓名从达琳·诺多内改为“达琳·格雷厄姆”。
共和党阵营的竞争现已十分激烈,参选者包括特朗普的忠实拥护者、众议员拉塞尔·弗莱,以及众议员拉尔夫·诺曼、商人马克·林奇和律师杜克·巴克纳。此前被视为潜在竞争者的众议员南希·梅斯已宣布不参选。8月11日初选的获胜者将在大选中对阵民主党人安妮·安德鲁斯,该选区目前被视为共和党的“稳赢区”。
批评人士指出,格雷厄姆缺乏资格,且将参议院席位视为“可继承财产”的做法引发了负面观感。由于目前尚未安排任何辩论,这场竞选将是一次考验:特朗普的背书能否克服选民对其履历单薄的担忧,以及南卡罗来纳州的选民是否会支持一场仅以延续其兄长备受争议的干涉主义外交政策为核心的竞选。
在林赛·格雷厄姆参议员去世后,他的妹妹达琳·格雷厄姆(原名诺多内)正式宣布竞选其参议员席位。在得到唐纳德·特朗普的支持下,她正在寻求完整的六年任期,尽管她此前并无担任民选公职的经验。为了利用其兄长的政治品牌,她已将姓名从达琳·诺多内改为“达琳·格雷厄姆”。
共和党阵营的竞争现已十分激烈,参选者包括特朗普的忠实拥护者、众议员拉塞尔·弗莱,以及众议员拉尔夫·诺曼、商人马克·林奇和律师杜克·巴克纳。此前被视为潜在竞争者的众议员南希·梅斯已宣布不参选。8月11日初选的获胜者将在大选中对阵民主党人安妮·安德鲁斯,该选区目前被视为共和党的“稳赢区”。
批评人士指出,格雷厄姆缺乏资格,且将参议院席位视为“可继承财产”的做法引发了负面观感。由于目前尚未安排任何辩论,这场竞选将是一次考验:特朗普的背书能否克服选民对其履历单薄的担忧,以及南卡罗来纳州的选民是否会支持一场仅以延续其兄长备受争议的干涉主义外交政策为核心的竞选。
 Monitoring Analytics总裁Joseph Bowring指出,在PJM互联公司最新的容量拍卖中,数据中心承担了38%(63亿美元)的成本。在过去四次拍卖中,数据中心共推高了294亿美元的费用,占总成本的46%。
Bowring认为,PJM目前“照常营业”的做法忽略了数据中心快速扩张所带来的范式转变,这迫使普通纳税人为更高的能源和输电成本买单。尽管谷歌、Meta和微软等大型科技公司已承诺保护消费者免受价格上涨的影响,但Bowring认为,在现行市场规则下,这根本无法实现。
他建议PJM专门为数据中心举行单独的容量拍卖。通过将这些高需求、高不确定性的负荷与基础拍卖剥离,电网运营商可以确保居民和商业用户的价格稳定。PJM目前正在制定一项后备拍卖提案,以解决这些可靠性问题,并计划于本月提交给联邦监管机构。与此同时,晨星DBRS警告称,公众和监管机构对数据中心日益增长的反对情绪,可能很快会为该行业带来重大的信贷和开发风险。
Monitoring Analytics总裁Joseph Bowring指出,在PJM互联公司最新的容量拍卖中,数据中心承担了38%(63亿美元)的成本。在过去四次拍卖中,数据中心共推高了294亿美元的费用,占总成本的46%。
Bowring认为,PJM目前“照常营业”的做法忽略了数据中心快速扩张所带来的范式转变,这迫使普通纳税人为更高的能源和输电成本买单。尽管谷歌、Meta和微软等大型科技公司已承诺保护消费者免受价格上涨的影响,但Bowring认为,在现行市场规则下,这根本无法实现。
他建议PJM专门为数据中心举行单独的容量拍卖。通过将这些高需求、高不确定性的负荷与基础拍卖剥离,电网运营商可以确保居民和商业用户的价格稳定。PJM目前正在制定一项后备拍卖提案,以解决这些可靠性问题,并计划于本月提交给联邦监管机构。与此同时,晨星DBRS警告称,公众和监管机构对数据中心日益增长的反对情绪,可能很快会为该行业带来重大的信贷和开发风险。
 作者曾是一名拥有九年经验的电台主持人,他曾一度怀念这一行业,但如今已毫无回归的念头。回首从校园广播到在特雷霍特从事专业广播的职业生涯,他深情地回忆起与听众交流及磨练技艺的乐趣。
然而,他认为现代广播已经失去了灵魂。企业兼并、旨在削减成本的“预录播音”模式的兴起,以及以广告受众数据为核心、忽视人际联结的程序化节目,掏空了整个行业。这些转变,再加上播放列表取代了主持人个人特色,使得曾经充满活力的电台变成了“无名的工具”。
尽管作者承认技术与文化在不断演进,但他感叹广播业的没落很大程度上是咎由自取。如今,他不再收听传统电台,而是转向流媒体或美国公共广播电台(NPR)。在他看来,曾定义了他青春岁月的、那种充满个人色彩和社区感的广播体验已经消逝,这使得重返直播间对他已不再具有吸引力。
作者曾是一名拥有九年经验的电台主持人,他曾一度怀念这一行业,但如今已毫无回归的念头。回首从校园广播到在特雷霍特从事专业广播的职业生涯,他深情地回忆起与听众交流及磨练技艺的乐趣。
然而,他认为现代广播已经失去了灵魂。企业兼并、旨在削减成本的“预录播音”模式的兴起,以及以广告受众数据为核心、忽视人际联结的程序化节目,掏空了整个行业。这些转变,再加上播放列表取代了主持人个人特色,使得曾经充满活力的电台变成了“无名的工具”。
尽管作者承认技术与文化在不断演进,但他感叹广播业的没落很大程度上是咎由自取。如今,他不再收听传统电台,而是转向流媒体或美国公共广播电台(NPR)。在他看来,曾定义了他青春岁月的、那种充满个人色彩和社区感的广播体验已经消逝,这使得重返直播间对他已不再具有吸引力。
Hacker News 最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交 登录
收音机的现状真令人遗憾 (jimgrey.net)
22 分,sonicrocketman 发布于 3 小时前 | 隐藏 | 过往 | 收藏 | 讨论 帮助
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
 以中央情报局为首的美国情报官员正日益与特朗普政府针对伊朗的持续冲突拉开距离。经过五个月的敌对状态,情报评估显示,美国持续的军事打击不仅无效,也不太可能迫使德黑兰重回谈判桌或软化其立场。
白宫官员最初将当前的战略宣传为一场“迅速、有限”的行动,但它却演变成了一场危险且无期限的僵局。分析人士警告称,本届政府从根本上低估了伊朗的民族主义决心,以及该国为确保政权存续而忍受严重经济和军事压力的意愿。
通过泄露这些评估,情报官员似乎是在为他们的怀疑态度留下记录,因为波斯湾地区的冲突仍在不断升级,且没有明确的退出战略。专家认为,进一步的军事压力只会加深泥潭,因为尽管损失惨重,伊朗仍致力于维持其战略筹码。最终,情报专业人士和独立分析人士一致认为,政府的“极限施压”方针未能实现其目标,导致两国都被困在动荡的僵局之中。
以中央情报局为首的美国情报官员正日益与特朗普政府针对伊朗的持续冲突拉开距离。经过五个月的敌对状态,情报评估显示,美国持续的军事打击不仅无效,也不太可能迫使德黑兰重回谈判桌或软化其立场。
白宫官员最初将当前的战略宣传为一场“迅速、有限”的行动,但它却演变成了一场危险且无期限的僵局。分析人士警告称,本届政府从根本上低估了伊朗的民族主义决心,以及该国为确保政权存续而忍受严重经济和军事压力的意愿。
通过泄露这些评估,情报官员似乎是在为他们的怀疑态度留下记录,因为波斯湾地区的冲突仍在不断升级,且没有明确的退出战略。专家认为,进一步的军事压力只会加深泥潭,因为尽管损失惨重,伊朗仍致力于维持其战略筹码。最终,情报专业人士和独立分析人士一致认为,政府的“极限施压”方针未能实现其目标,导致两国都被困在动荡的僵局之中。
```
Hacker News 最新 | 往期 | 评论 | 提问 | 展示 | 招聘 | 投稿 登录
通往幸福的十个步骤 (hintjens.com)
8 分,由 emerongi 发布于 48 分钟前 | 隐藏 | 往期 | 收藏 | 2 条评论
帮助
ldayley 0 分钟前 | 下一条 [–]
昨天我刚和孩子们一起回忆了一篇 Pieter Hintjens 的旧文。它们至今仍然适用。安息吧。(标题需要加上 2016)
回复
two_handfuls 22 分钟前 | 上一条 [–]
进来时没抱太大期望,但这些观点都很好,表达也很简洁。
回复
考虑申请 YC 2026 年秋季班吧!申请通道开放至 7 月 27 日。
指南 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
```
 该工作室旨在通过利用人工智能降低成本、绕过日本剥削性的制作委员会制度,并为艺术家提供更优厚的薪酬,从而使动画制作在美国实现商业可行性。他们认为,通过简化制作流程,可以实现动画创作的民主化,并培育本土产业。
他们的工作流优先考虑故事的“核心”——即关键的情感或叙事钩子,通常会删减次要情节以确保节奏紧凑且有效。在剧本创作上,他们摒弃了通用的语言大模型,而是采用以人为本的方法进行分镜和节拍表设计。
制作流程遵循精简模式:
1. **初稿:** 生成粗略片段以测试节奏、氛围和角色动作。
2. **AI 动画:** 初稿确定后,利用一致的角色/环境参考以高质量重新生成镜头。
3. **后期制作:** 通过 Photoshop 等工具手动清理 AI 伪影,并对视觉效果进行升频。
4. **音频:** 对话由人类或 AI 完成,音乐和音效则由 AI 生成以提高效率。
归根结底,该工作室将 AI 视为连接创意抱负与预算限制之间的桥梁,在不牺牲核心叙事体验的前提下,实现更快速的迭代。
该工作室旨在通过利用人工智能降低成本、绕过日本剥削性的制作委员会制度,并为艺术家提供更优厚的薪酬,从而使动画制作在美国实现商业可行性。他们认为,通过简化制作流程,可以实现动画创作的民主化,并培育本土产业。
他们的工作流优先考虑故事的“核心”——即关键的情感或叙事钩子,通常会删减次要情节以确保节奏紧凑且有效。在剧本创作上,他们摒弃了通用的语言大模型,而是采用以人为本的方法进行分镜和节拍表设计。
制作流程遵循精简模式:
1. **初稿:** 生成粗略片段以测试节奏、氛围和角色动作。
2. **AI 动画:** 初稿确定后,利用一致的角色/环境参考以高质量重新生成镜头。
3. **后期制作:** 通过 Photoshop 等工具手动清理 AI 伪影,并对视觉效果进行升频。
4. **音频:** 对话由人类或 AI 完成,音乐和音效则由 AI 生成以提高效率。
归根结底,该工作室将 AI 视为连接创意抱负与预算限制之间的桥梁,在不牺牲核心叙事体验的前提下,实现更快速的迭代。
Hacker News 上关于一篇 AI 生成动画文章(《AI 动画是如何制作的》)的讨论,突显了该媒介在技术进步与伦理争议并存的现状。
评论者认为,尽管 AI 视频生成技术正在不断改进,甚至已能有效表现快节奏的动作场面,但仍存在明显的局限性,例如剪辑破碎以及视觉瑕疵(如角色与物体融合)。虽然有人认为该技术目前适用于商业广告或电子游戏过场动画等短片内容,但也有人反驳称,制作高质量的长篇动画依然遥不可及。
讨论帖还涉及了 AI 对劳动力市场的影响。用户们争论 AI 是否真的能提高人类画师的待遇,许多人指出,动画行业低薪的根源在于创意领域常见的“激情剥削”模式。一小部分用户出于道德立场彻底否定该技术,将整个生成过程斥为剽窃。
Show HN:一个将异步工作实践转化为工具的 MCP 服务器 Show HN: An MCP server that turns async-work practices into tools
3 小时前
 **Open and Async MCP 服务器**将专业的异步工作实践直接集成到你的 AI 辅助编辑器中。通过将《Open and Async》手册中的原则转化为可操作的工具,它使团队能够在不离开开发环境的情况下简化协作流程。
主要功能包括:
* **方法工具**:生成结构化的决策文档(ADR)、将会议内容转化为异步工件、为状态更新评分以提高透明度,并促进异步站会。
* **决策支持**:使用“分类”功能来确定任务最适合同步还是异步处理,并提供相应的理由。
* **参考工具**:访问《Open and Async》一书的原则,搜索针对常见异步异议的反驳意见,并获取针对特定角色的指导。
* **“教练”提示词**:一个综合性工具,可用于评估复杂情况、起草相应的文档,并提供可分享的摘要。
该服务器被设计为一种实用工具而非营销工具,它提供带有引用和模板的输出,旨在帮助团队“公开工作”(work loudly)并减少不必要的会议。它兼容任何符合 MCP 标准的客户端(如 Claude Desktop 或 Claude Code),并确保你的工作流程保持结构化、文档化且高效。
**Open and Async MCP 服务器**将专业的异步工作实践直接集成到你的 AI 辅助编辑器中。通过将《Open and Async》手册中的原则转化为可操作的工具,它使团队能够在不离开开发环境的情况下简化协作流程。
主要功能包括:
* **方法工具**:生成结构化的决策文档(ADR)、将会议内容转化为异步工件、为状态更新评分以提高透明度,并促进异步站会。
* **决策支持**:使用“分类”功能来确定任务最适合同步还是异步处理,并提供相应的理由。
* **参考工具**:访问《Open and Async》一书的原则,搜索针对常见异步异议的反驳意见,并获取针对特定角色的指导。
* **“教练”提示词**:一个综合性工具,可用于评估复杂情况、起草相应的文档,并提供可分享的摘要。
该服务器被设计为一种实用工具而非营销工具,它提供带有引用和模板的输出,旨在帮助团队“公开工作”(work loudly)并减少不必要的会议。它兼容任何符合 MCP 标准的客户端(如 Claude Desktop 或 Claude Code),并确保你的工作流程保持结构化、文档化且高效。
GitHub 远程办公实践老兵 Ben Balter 推出了一款开源的**模型上下文协议(MCP)服务器**,旨在帮助团队转型为异步工作流。
受其相关新书的启发,Balter 开发了这一工具,旨在为静态文档提供一种交互式的 AI 驱动替代方案。用户无需仅依赖查阅手册,而是可以将该服务器集成到 Claude 等 AI 助手之中,从而获得针对特定工作挑战的个性化指导。
该 MCP 服务器包含多种专用工具,例如:
* `draft_decision_doc`:自动生成决策文档。
* `convert_meeting_to_async`:将会议议程转换为异步格式。
* `score_status_update`:分析并提升沟通清晰度。
* `triage_sync_vs_async`:协助确定特定任务的最佳沟通模式。
该工具免费且开源,任何人都可以通过 `npx -y @open-and-async/mcp` 进行安装。Balter 将此项目描述为一场在 AI 时代下优化职场指导的实验。
一个偶发性测试暴露了 Redis 客户端的释放后使用(use-after-free)漏洞。 A flaky test exposed a Redis client use-after-free
3 小时前
 这个故事讲述了对一个复杂、非确定性内存损坏问题的调查过程,该问题由 Redis gem 升级触发。起初看似简单的“不稳定性测试”或竞态条件,在工程师遇到无法解释的崩溃和“双重释放(double free)”错误时,演变成了一场深度的调查。
突破口出现在一位开发者的自定义插件自动捕获了一次段错误(segmentation fault)的内存转储(core dump)时。对转储文件的分析揭示了一个大小异常庞大的 `memmove` 操作,指向了 `hiredis` C 扩展内的内存损坏。
团队利用之前对地址消毒器(AddressSanitizer, ASAN)的了解,使用这一内存安全工具重新编译了 Ruby,并很快定位到了一个“堆释放后使用(heap use-after-free)”错误。他们发现该 Bug 是由同步问题引起的,即读取线程错误地释放了写入缓冲区。
最终,团队通过禁用有问题的 C 扩展并向上游报告了该 Bug 解决了问题。这次成功凸显了强大的可观测性工具(如自动化测试可靠性跟踪和内存转储捕获)结合内存安全调试工具的重要性,正是它们将一个难以捉摸的长期稳定性问题转化为了一个可修复的技术故障。
这个故事讲述了对一个复杂、非确定性内存损坏问题的调查过程,该问题由 Redis gem 升级触发。起初看似简单的“不稳定性测试”或竞态条件,在工程师遇到无法解释的崩溃和“双重释放(double free)”错误时,演变成了一场深度的调查。
突破口出现在一位开发者的自定义插件自动捕获了一次段错误(segmentation fault)的内存转储(core dump)时。对转储文件的分析揭示了一个大小异常庞大的 `memmove` 操作,指向了 `hiredis` C 扩展内的内存损坏。
团队利用之前对地址消毒器(AddressSanitizer, ASAN)的了解,使用这一内存安全工具重新编译了 Ruby,并很快定位到了一个“堆释放后使用(heap use-after-free)”错误。他们发现该 Bug 是由同步问题引起的,即读取线程错误地释放了写入缓冲区。
最终,团队通过禁用有问题的 C 扩展并向上游报告了该 Bug 解决了问题。这次成功凸显了强大的可观测性工具(如自动化测试可靠性跟踪和内存转储捕获)结合内存安全调试工具的重要性,正是它们将一个难以捉摸的长期稳定性问题转化为了一个可修复的技术故障。
来自 *Buildkite Engineering* 的这篇链接文章详细介绍了对 Redis 客户端中“释放后使用”(use-after-free)内存错误的调查过程,该错误最初是通过一个不稳定的测试(flaky test)被发现的。
Hacker News 上的讨论聚焦于调查流程,用户们对诊断 `memmove` 异常所使用的具体工具(如 GDB 或 Valgrind)表现出了浓厚兴趣。评论者还称赞了该网站交互式的流体模拟 UI,并将其与开发者远藤侑介(Yusuke Endoh)的作品相提并论。除了技术主题外,该讨论串还简要涉及了关于原文标题清晰度的元讨论,以及一些关于语法解读的轻松调侃。
跳至主要内容 盲人杂耍 通过声音和动作进行杂耍 个人资料 正在检查动作权限…… 排行榜 暂无记录。你的最佳成绩将显示在此处。
抱歉。
 美国司法部(DOJ)已对哈佛大学展开调查,以确定其是否违反了《民权法案》第六章。此次调查的重点是,哈佛大学接受来自中国来源超过6.3亿美元的资助,是否设立了基于国籍非法排斥美国学生的经济援助项目。
根据联邦法律,大学必须披露超过25万美元的外国捐赠。司法部指控哈佛大学部分由外国资助的项目可能包含偏袒特定国家学生的限制性条款,从而可能对美国公民构成歧视。助理司法部长哈米特·K·迪隆(Harmeet K. Dhillon)强调,学校在接受联邦资助的同时,不得管理排斥美国人的援助项目。
哈佛大学表示,正在审查司法部的通知,并坚称其在经济援助方面遵守了所有法律报告要求和反歧视法。此前,该大学因招生政策、反犹太主义骚扰指控以及《哈佛法律评论》的成员资格标准等问题,已受到联邦政府的一系列调查。司法部明确表示,目前尚未就此次调查得出任何结论。
美国司法部(DOJ)已对哈佛大学展开调查,以确定其是否违反了《民权法案》第六章。此次调查的重点是,哈佛大学接受来自中国来源超过6.3亿美元的资助,是否设立了基于国籍非法排斥美国学生的经济援助项目。
根据联邦法律,大学必须披露超过25万美元的外国捐赠。司法部指控哈佛大学部分由外国资助的项目可能包含偏袒特定国家学生的限制性条款,从而可能对美国公民构成歧视。助理司法部长哈米特·K·迪隆(Harmeet K. Dhillon)强调,学校在接受联邦资助的同时,不得管理排斥美国人的援助项目。
哈佛大学表示,正在审查司法部的通知,并坚称其在经济援助方面遵守了所有法律报告要求和反歧视法。此前,该大学因招生政策、反犹太主义骚扰指控以及《哈佛法律评论》的成员资格标准等问题,已受到联邦政府的一系列调查。司法部明确表示,目前尚未就此次调查得出任何结论。
 特朗普政府正启动一项 2 亿美元的计划,旨在加速核电站的部署,以专门满足人工智能数据中心激增的能源需求。反应堆开发商 Oklo 和 X-energy 参与了该项目,并与微软和英伟达等合作伙伴携手合作。
与之前资本密集型的政府项目(如 32 亿美元的先进反应堆示范计划)不同,这项新举措的重点在于简化监管和运营障碍。通过利用人工智能、联邦国家实验室和学术合作,该计划旨在大幅缩短设计、许可和建设新核设施所需的时间与人力。
此项公告预计将在能源部峰会上发布,反映了联邦政府为人工智能产业保障可靠电力的持续战略。受此消息影响,Oklo 和 X-energy 的股价出现显著上涨。该项目与包括西屋电气机组计划及各项小型模块化反应堆(SMR)成本分摊奖项在内的一系列联邦核能支持政策相辅相成,进一步巩固了政府扩大核能产能的承诺。
特朗普政府正启动一项 2 亿美元的计划,旨在加速核电站的部署,以专门满足人工智能数据中心激增的能源需求。反应堆开发商 Oklo 和 X-energy 参与了该项目,并与微软和英伟达等合作伙伴携手合作。
与之前资本密集型的政府项目(如 32 亿美元的先进反应堆示范计划)不同,这项新举措的重点在于简化监管和运营障碍。通过利用人工智能、联邦国家实验室和学术合作,该计划旨在大幅缩短设计、许可和建设新核设施所需的时间与人力。
此项公告预计将在能源部峰会上发布,反映了联邦政府为人工智能产业保障可靠电力的持续战略。受此消息影响,Oklo 和 X-energy 的股价出现显著上涨。该项目与包括西屋电气机组计划及各项小型模块化反应堆(SMR)成本分摊奖项在内的一系列联邦核能支持政策相辅相成,进一步巩固了政府扩大核能产能的承诺。
请启用 JavaScript 和 Cookie 以继续。
“Workaround”(workaround.run)的开发者发布了一款网页工具,旨在帮助用户管理 GitHub 星标,这一功能目前在 GitHub 原生界面中尚不存在。
该应用允许用户批量取消星标,并增加了利用人工智能发现新仓库或筛选现有仓库的功能。据开发者介绍,该工具通过特定标准来识别“无效”或过时的仓库:如果项目已存档、描述中包含“deprecated”(弃用)或“unmaintained”(未维护)等关键词,或者两年内没有提交记录,即会被识别出来。该项目现已开源并发布在 GitHub 上。
 尽管美国的一项豁免令已于6月17日到期,但印度从俄罗斯进口的原油仍维持在历史高位,7月份平均每日进口245万桶。这一数字仅略低于6月份264万桶的峰值,因为许多货运是在豁免令生效期间安排的。
俄罗斯已巩固了其作为印度主要原油供应国的地位,这很大程度上归因于持续的地缘政治动荡,包括霍尔木兹海峡与伊朗相关的危机。为降低供应风险,阿联酋和沙特阿拉伯等次要供应国已成功转向红海码头和管道等替代出口路线,以绕过该海峡。
分析人士预计,无论未来美国在油轮豁免政策上如何调整,俄罗斯原油都将继续作为印度能源供应的基石。随着印度持续优先考虑能源安全,俄罗斯作为该国最大石油供应国的地位似乎已稳固确立。
尽管美国的一项豁免令已于6月17日到期,但印度从俄罗斯进口的原油仍维持在历史高位,7月份平均每日进口245万桶。这一数字仅略低于6月份264万桶的峰值,因为许多货运是在豁免令生效期间安排的。
俄罗斯已巩固了其作为印度主要原油供应国的地位,这很大程度上归因于持续的地缘政治动荡,包括霍尔木兹海峡与伊朗相关的危机。为降低供应风险,阿联酋和沙特阿拉伯等次要供应国已成功转向红海码头和管道等替代出口路线,以绕过该海峡。
分析人士预计,无论未来美国在油轮豁免政策上如何调整,俄罗斯原油都将继续作为印度能源供应的基石。随着印度持续优先考虑能源安全,俄罗斯作为该国最大石油供应国的地位似乎已稳固确立。
一位联邦法官已最终批准人工智能公司 Anthropic 与数千名作者之间 15 亿美元的和解协议。该协议结束了一项集体诉讼,诉讼指控 Anthropic 使用盗版书籍来训练其 Claude 聊天机器人。根据条款,符合条件的作者和出版商每本书将获得约 3,000 美元,目前已有超过 91% 的索赔申请提交。 该案由小说家安德烈娅·巴茨(Andrea Bartz)等人于 2024 年发起,是众多正在进行的人工智能版权法律纠纷中首个达成的重要解决方案。尽管该和解协议为创作者提供了可观的经济补偿,但也反映出复杂的法律环境:该案此前的一项裁决确认,虽然 Anthropic 获取盗版作品的行为不当,但利用受版权保护的材料训练人工智能的行为被视为“合理使用”。Anthropic 对此解决方案表示欢迎,强调法院的基本法律解释支持人工智能技术的持续发展。原告律师称赞此结果是历史上规模最大的版权赔偿。
一位联邦法官批准了一项 15 亿美元的和解协议,该协议涉及 Anthropic 使用盗版书籍训练其 Claude AI 的问题。此案专门针对使用来自 LibGen 等网站的未经授权副本,而非 AI 训练行为本身(后者此前已被裁定在合法获取素材的情况下属于“合理使用”)。
主要内容摘要如下:
* **赔偿:** 符合条件的书籍将获得 3,000 美元的赔偿,由作者和出版商分摊。三名集体诉讼代表每人将获得 15,000 美元。
* **法律费用:** 法官将集体诉讼律师费从 12.5%(1.875 亿美元)削减至 6.8%(1.01 亿美元)。
* **争议:** 这一裁决在 Hacker News 上引发了巨大争议。批评者认为,该和解方案只是“隔靴搔痒”,未能考虑到从数据中获得的巨大商业优势;支持者则指出,赔偿金额约为书籍零售价的 100 倍,将其视为解决诉讼中盗版问题的合理方案。
该和解协议未能解决有关 AI 对版权和“衍生作品”影响的更广泛问题。
乌克兰军队总司令成为泽连斯基冒险改组的最新受害者 Ukraine's Army Chief Latest To Fall Victim To Zelensky's Risky Reshuffle
5 小时前
 泽连斯基总统宣布了重大的军事改组,解雇了总司令奥列克桑德尔·瑟尔斯基,并任命米哈伊洛·德拉帕蒂接替其职务。此前,国防部长米哈伊洛·费多罗夫和总理尤利娅·斯维里登科刚被免职,这一系列举动引发了争议,标志着乌克兰政治和军事领导层正在经历全面的重组。
泽连斯基将这些变动定性为旨在巩固乌克兰地位并加强在俄罗斯境内作战努力的战略调整。基辅目前的局势十分紧张;尤其是费多罗夫的被免职引发了罕见的公众抗议,促使泽连斯基提议让他担任负责国家技术的新职务。此前费多罗夫与瑟尔斯基之间曾爆发过矛盾,费多罗夫指责该将军阻碍了必要的军事改革。
尽管政府将这些举措描述为新战略的一部分,但批评人士和分析家对当前战争努力的稳定性表示质疑。尽管乌克兰对俄罗斯基础设施进行了高调的无人机袭击,但俄军在东部战线仍在按部就班地推进。这些高层领导的变动引发了人们的担忧,即政府究竟是在应对真正的内部摩擦,还是在努力掩盖战场上不断恶化的现实。
泽连斯基总统宣布了重大的军事改组,解雇了总司令奥列克桑德尔·瑟尔斯基,并任命米哈伊洛·德拉帕蒂接替其职务。此前,国防部长米哈伊洛·费多罗夫和总理尤利娅·斯维里登科刚被免职,这一系列举动引发了争议,标志着乌克兰政治和军事领导层正在经历全面的重组。
泽连斯基将这些变动定性为旨在巩固乌克兰地位并加强在俄罗斯境内作战努力的战略调整。基辅目前的局势十分紧张;尤其是费多罗夫的被免职引发了罕见的公众抗议,促使泽连斯基提议让他担任负责国家技术的新职务。此前费多罗夫与瑟尔斯基之间曾爆发过矛盾,费多罗夫指责该将军阻碍了必要的军事改革。
尽管政府将这些举措描述为新战略的一部分,但批评人士和分析家对当前战争努力的稳定性表示质疑。尽管乌克兰对俄罗斯基础设施进行了高调的无人机袭击,但俄军在东部战线仍在按部就班地推进。这些高层领导的变动引发了人们的担忧,即政府究竟是在应对真正的内部摩擦,还是在努力掩盖战场上不断恶化的现实。
 新泽西州州长米基·谢里尔(Mikie Sherrill)近日宣布,由于州机动车委员会(Motor Vehicle Commission)的软件错误,导致约 6600 名非公民在 2023 年 6 月至 2024 年 6 月期间被错误地登记为选民。尽管这些人在申请键盘上正确标注了自己的非公民身份,但系统故障仍将其处理为注册选民。
初步审查显示,受影响者中共有不到 400 人投了票。这些登记信息涉及全州不同的政治派别和地区。谢里尔州长形容此次事件为“令人震惊”的失误,并已下令展开调查,指示将受影响人员从选民名单中剔除,同时着手更换负责该软件的供应商。
这一事件引来了特朗普政府的批评,称此错误证明了通过《拯救美国法案》(SAVE America Act)以确保选举完整性的必要性。谢里尔州长强调,该错误已于 2024 年 6 月得到纠正,并重申该州致力于确保只有符合资格的公民才能参与投票。
新泽西州州长米基·谢里尔(Mikie Sherrill)近日宣布,由于州机动车委员会(Motor Vehicle Commission)的软件错误,导致约 6600 名非公民在 2023 年 6 月至 2024 年 6 月期间被错误地登记为选民。尽管这些人在申请键盘上正确标注了自己的非公民身份,但系统故障仍将其处理为注册选民。
初步审查显示,受影响者中共有不到 400 人投了票。这些登记信息涉及全州不同的政治派别和地区。谢里尔州长形容此次事件为“令人震惊”的失误,并已下令展开调查,指示将受影响人员从选民名单中剔除,同时着手更换负责该软件的供应商。
这一事件引来了特朗普政府的批评,称此错误证明了通过《拯救美国法案》(SAVE America Act)以确保选举完整性的必要性。谢里尔州长强调,该错误已于 2024 年 6 月得到纠正,并重申该州致力于确保只有符合资格的公民才能参与投票。
 美国财政部已实施一套新的验证系统,旨在防止联邦政府向已故人员发放款项,这是减少政府浪费和欺诈行为的重要举措。通过将总额 2.7 万亿美元的 8.85 亿笔款项与扩展后的死亡记录进行比对审计,财政部已成功拦截了约 9900 万美元的不当支付。
该倡议落实了特朗普政府的一项指令,并得到了副总统万斯(JD Vance)领导的反欺诈工作组的支持,该工作组旨在彻底改革联邦福利制度。财政部长斯科特·贝森特(Scott Bessent)指出,这只是实现支付系统现代化及保护纳税人资金这一更广泛努力的开端,目标是在今年年底前拦截高达 3.5 亿美元的欺诈性付款。
该计划利用了《停止向已故人员进行不当支付法案》,使财政部能够获取社会保障局的死亡记录。这些举措与政府效率部(DOGE)的工作相辅相成,后者此前已在社会保障系统中识别出数百万名已故人员。官员们强调,这些保障措施对于确保联邦资金惠及预期收款人并解决长期存在的系统性漏洞至关重要。
美国财政部已实施一套新的验证系统,旨在防止联邦政府向已故人员发放款项,这是减少政府浪费和欺诈行为的重要举措。通过将总额 2.7 万亿美元的 8.85 亿笔款项与扩展后的死亡记录进行比对审计,财政部已成功拦截了约 9900 万美元的不当支付。
该倡议落实了特朗普政府的一项指令,并得到了副总统万斯(JD Vance)领导的反欺诈工作组的支持,该工作组旨在彻底改革联邦福利制度。财政部长斯科特·贝森特(Scott Bessent)指出,这只是实现支付系统现代化及保护纳税人资金这一更广泛努力的开端,目标是在今年年底前拦截高达 3.5 亿美元的欺诈性付款。
该计划利用了《停止向已故人员进行不当支付法案》,使财政部能够获取社会保障局的死亡记录。这些举措与政府效率部(DOGE)的工作相辅相成,后者此前已在社会保障系统中识别出数百万名已故人员。官员们强调,这些保障措施对于确保联邦资金惠及预期收款人并解决长期存在的系统性漏洞至关重要。
该工具包是一个利用 **io_uring** 和 **eBPF** 进行 Linux 后渗透与规避研究的程序库。它无需外部框架,通过原始系统调用(syscalls)和极少的依赖项,直接与内核接口交互。
### 核心功能
* **io_uring 操作:** 执行文件、网络和注入操作。由于通过内核工作队列而非 `sys_call_table` 运行,可绕过传统的基于系统调用的 EDR 钩子(hook)。
* **eBPF 工具:** 包含用于管理 BPF 程序、映射(maps)和链接的实用工具,允许用户检查、污染或禁用安全传感器(如 BPF LSM、Falco)。
* **EDR 规避:** 提供约 75 种工具,用于环境侦察、凭据窃取、进程隐藏以及绕过安全监控钩子(如 ftrace、kprobes 和 auditd)。
* **技术库:** 包含针对 Falco 默认规则集的特定绕过方法,利用事件泛洪、路径透视和名称欺骗等技术来逃避检测。
### 环境要求
该项目需要现代 Linux 内核(5.4+)并启用 BTF,同时需安装 `clang`、`gcc` 和标准内核头文件。此工具仅限用于**经过授权的安全研究和红队演练**。开发者强调应负责任地使用,并明确本代码仅供教育和防御性开发使用。
抱歉。
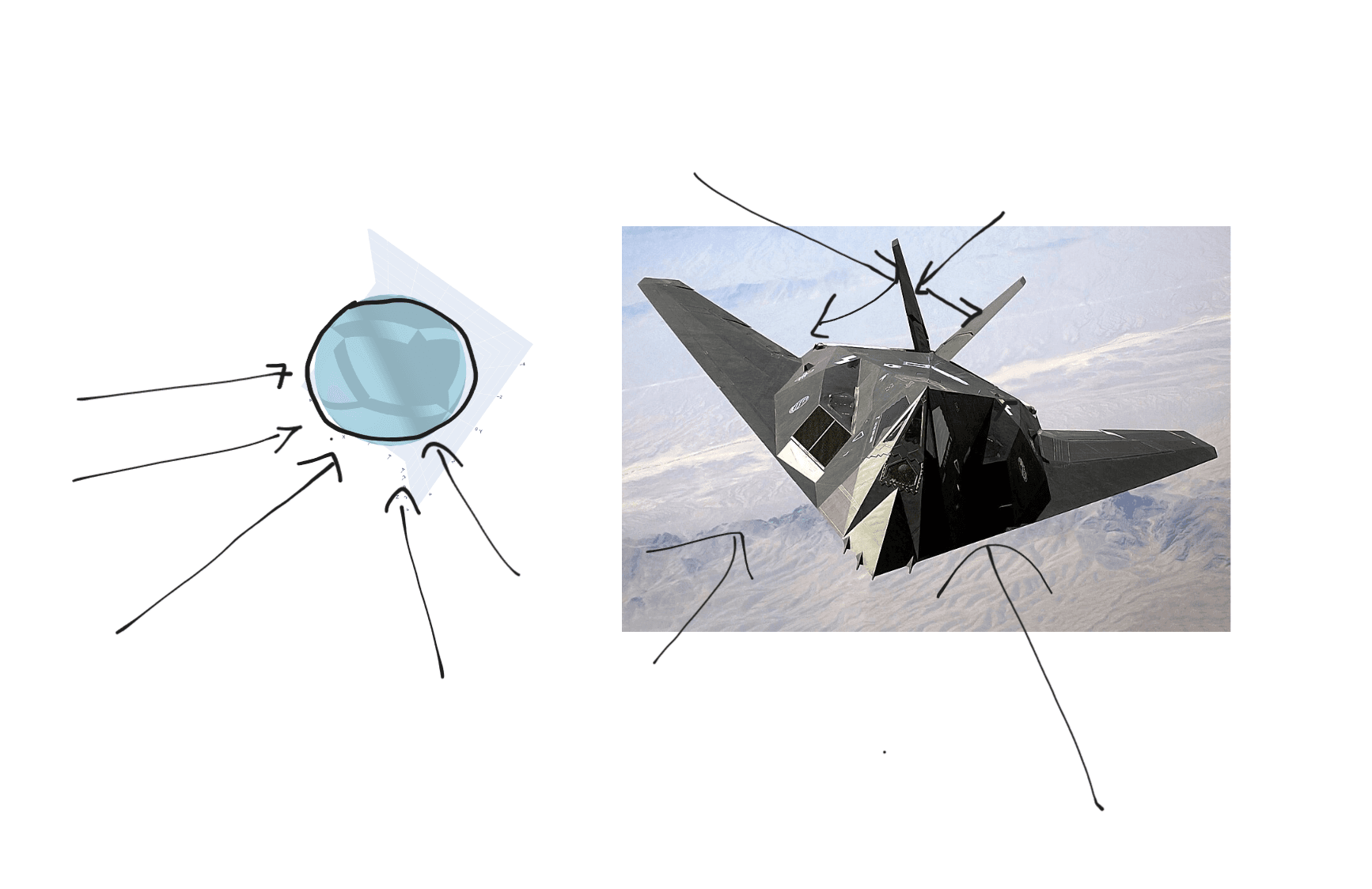 本文探讨了苏联物理学家彼得·乌菲姆采夫(Pyotr Ufimtsev)于1971年关于电磁边缘衍射的研究,如何促成了雷达隐身技术的发展,其中最著名的应用当属F-117“夜鹰”战斗机。
隐身技术的核心挑战在于降低飞机的“雷达散射截面”(RCS),即反射回雷达源的有效面积。早期飞机多依靠速度或轻微改进,而真正的隐身则需要数学优化。由于在20世纪70年代,通过计算求解复杂形状的麦克斯韦方程组是不可能的,工程师们采用了“物理光学法”(PO)。该方法通过简化假设,将雷达反射视为镜面反射,从而在无需模拟每一次相互作用的情况下估算散射。
数学研究表明,曲面会适得其反,因为它们就像迪斯科球一样,几乎能从任何角度将雷达波反射回源头。相反,“隐身”设计倾向于采用平坦的倾斜切面,将雷达能量偏转至远离雷达源的方向。尽管这创造了被称为“摇摆妖精”(Wobbly Goblin)的飞机——其空气动力学性能极不稳定,必须依靠电传操纵计算机来维持平衡——但它确实使F-117在雷达面前几乎隐形。这一途径证明了,在物理学支撑下运用巧妙的几何设计,可以突破传统工程学的局限,实现真正的隐身效果。
本文探讨了苏联物理学家彼得·乌菲姆采夫(Pyotr Ufimtsev)于1971年关于电磁边缘衍射的研究,如何促成了雷达隐身技术的发展,其中最著名的应用当属F-117“夜鹰”战斗机。
隐身技术的核心挑战在于降低飞机的“雷达散射截面”(RCS),即反射回雷达源的有效面积。早期飞机多依靠速度或轻微改进,而真正的隐身则需要数学优化。由于在20世纪70年代,通过计算求解复杂形状的麦克斯韦方程组是不可能的,工程师们采用了“物理光学法”(PO)。该方法通过简化假设,将雷达反射视为镜面反射,从而在无需模拟每一次相互作用的情况下估算散射。
数学研究表明,曲面会适得其反,因为它们就像迪斯科球一样,几乎能从任何角度将雷达波反射回源头。相反,“隐身”设计倾向于采用平坦的倾斜切面,将雷达能量偏转至远离雷达源的方向。尽管这创造了被称为“摇摆妖精”(Wobbly Goblin)的飞机——其空气动力学性能极不稳定,必须依靠电传操纵计算机来维持平衡——但它确实使F-117在雷达面前几乎隐形。这一途径证明了,在物理学支撑下运用巧妙的几何设计,可以突破传统工程学的局限,实现真正的隐身效果。
这篇 Hacker News 讨论帖围绕一篇关于隐形飞机数学原理的博文展开,但对话很快转向了关于 AI 内容创作的辩论。
许多评论者对大语言模型生成的“AI 味”内容表示不满,认为其缺乏深度、校对粗糙,且抑制了真正的个人创造力。批评者认为,依赖 AI 取代人类创作会削弱艺术和技术工作的价值。相比之下,也有参与者为使用 AI 进行辩护,认为这是应对现代内容许可所带来的高成本、法律复杂性及时间限制的务实选择。
除了关于 AI 的元讨论外,部分讨论聚焦于技术本身。用户探讨了雷达散射截面(RCS)探测的物理学原理,明确了由于信号往返衰减,雷达探测遵循四次方反比定律。归根结底,社区观点依然分歧:一些人赞赏其中的技术科普价值,而另一些人则认为,缺乏人类付出和编辑质量导致该项目的可信度大打折扣。
Google 宣布正式发布两款新模型:**Gemini 3.6 Flash** 和 **Gemini 3.5 Flash-Lite**。这两款模型均支持 1M Token 上下文窗口和计算机使用(Computer Use)功能,并要求迁移至 Interactions API。 **模型主要差异:** * **Gemini 3.6 Flash:** 针对复杂的智能体和多模态任务进行了优化。与上一代产品相比,它改进了代码生成和空间推理能力,且输出成本更低(每 1M Token 7.50 美元)。 * **Gemini 3.5 Flash-Lite:** 定位为速度最快、性价比最高的解决方案(每 1M 输入 Token 0.30 美元),非常适合高吞吐量的数据解析和文档提取。 **关键迁移要求:** * **弃用参数:** 采样参数(`temperature`、`top_p`、`top_k`)现已弃用,必须从所有请求中移除。 * **轮次验证:** 不再支持预填充模型轮次(Prefilling model turns);开发人员应改用 `system_instruction` 或结构化输出来进行格式控制。 * **实施:** 可通过 Antigravity 编码智能体的 `gemini-interactions-api` 技能自动完成迁移。开发人员需要更新模型 ID,移除已弃用的采样参数,并确保 API 调用符合新的轮次验证规则。
Google 已正式弃用其最新 Gemini 模型的采样参数 `temperature`、`top_p` 和 `top_k`。这些参数现已被忽略,未来的模型更新若在 API 请求中包含这些参数,将返回 HTTP 400 错误。建议用户从所有当前实现中移除这些参数。
此公告在 Hacker News 的开发者群体中引发了讨论。一些用户对 Google 建议使用“系统指令”来管理模型确定性的做法表示怀疑,认为其可靠性不及传统的采样控制。此外,参与者指出,Claude 3.5 Sonnet 等其他模型也已不再使用这些参数。
此内容为 PDF 文件的二进制数据流,无法翻译为中文。
```Hacker News最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交登录工程师的 USB Type-C 指南 [pdf] (ti.com)8 点,由 sohkamyung 发布于 45 分钟前 | 隐藏 | 过往 | 收藏 | 1 条评论 帮助
SOLAR_FIELDS 17 分钟前 [–]
我还是照例评论一下,该规范竟然没有包含一种能快速直观识别线缆功能(数据传输与供电等)的简易方法,这实在有点荒谬。在我看来,这是该规范最大的缺陷。回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索: ```
 在最近一期《每日秀》节目中,乔恩·斯图尔特幽默地聚焦于唐纳德·特朗普在机场停机坪上时,其身后出现的一位神秘人物。在嘲讽了这位前总统关于一场足球赛的评论后,斯图尔特将话题转向了背景中的那个人——此人有着与特朗普相似的发型和体型,惊人的相似度让这位喜剧演员开玩笑地推测,他发现了“备用总统”。
斯图尔特的困惑引发了一阵搞笑的胡思乱想,他甚至质疑真正的特朗普是否一直以来才是那个“备用”的。然而,这个谜团很快就被解开了:那个人实际上是梅拉尼娅·特朗普 82 岁的父亲维克多·克纳夫斯。尽管这种相似纯属巧合,但斯图尔特还是顺势发挥,打趣说考虑到针对这位前总统的安全威胁,保留一个替身倒也不失为一个好主意。
在最近一期《每日秀》节目中,乔恩·斯图尔特幽默地聚焦于唐纳德·特朗普在机场停机坪上时,其身后出现的一位神秘人物。在嘲讽了这位前总统关于一场足球赛的评论后,斯图尔特将话题转向了背景中的那个人——此人有着与特朗普相似的发型和体型,惊人的相似度让这位喜剧演员开玩笑地推测,他发现了“备用总统”。
斯图尔特的困惑引发了一阵搞笑的胡思乱想,他甚至质疑真正的特朗普是否一直以来才是那个“备用”的。然而,这个谜团很快就被解开了:那个人实际上是梅拉尼娅·特朗普 82 岁的父亲维克多·克纳夫斯。尽管这种相似纯属巧合,但斯图尔特还是顺势发挥,打趣说考虑到针对这位前总统的安全威胁,保留一个替身倒也不失为一个好主意。
 最近的测试表明,在开源模型 Kimi K3 和专有模型 Fable 5 之间进行任务路由,其效果远优于仅依赖单一模型。在一项包含 1,000 多项智能体任务的基准测试中(涵盖软件工程、终端操作和法律分析),K3 和 Fable 的准确率几乎持平,且各自在不同领域展现出独特优势。
尽管质量相当,但在成本方面差异巨大。得益于 Token 定价和高效的提示词缓存,K3 的成本效率提升了高达 50 倍。Oracle 路由模拟显示,采用混合策略——即以 K3 作为默认主力模型,仅在特定的高端任务中使用 Fable——其表现超过了单一模型。
通过将任务分配给最具成本效益且能力匹配的模型,企业可以在大幅降低运营成本的同时获得更优成果。这些发现表明,AI 基础设施的未来在于任务级路由,而非依赖单一的“前沿”模型;路由机制正成为实现可扩展、高性能智能体工作流的核心战略优势。
最近的测试表明,在开源模型 Kimi K3 和专有模型 Fable 5 之间进行任务路由,其效果远优于仅依赖单一模型。在一项包含 1,000 多项智能体任务的基准测试中(涵盖软件工程、终端操作和法律分析),K3 和 Fable 的准确率几乎持平,且各自在不同领域展现出独特优势。
尽管质量相当,但在成本方面差异巨大。得益于 Token 定价和高效的提示词缓存,K3 的成本效率提升了高达 50 倍。Oracle 路由模拟显示,采用混合策略——即以 K3 作为默认主力模型,仅在特定的高端任务中使用 Fable——其表现超过了单一模型。
通过将任务分配给最具成本效益且能力匹配的模型,企业可以在大幅降低运营成本的同时获得更优成果。这些发现表明,AI 基础设施的未来在于任务级路由,而非依赖单一的“前沿”模型;路由机制正成为实现可扩展、高性能智能体工作流的核心战略优势。
近期 Hacker News 上的一场讨论审视了 fireworks.ai 发布的一份声明报告,该报告指出新款 Kimi K3 模型在性能上足以与 Fable 抗衡,并将两者皆称为“业界顶尖”(SotA)。
社区对此反应各异,普遍持怀疑态度。用户指出该报告在呈现方式上存在潜在偏见,强调了 Kimi 的优势表现,却淡化了 Fable 的类似表现。一些评论者表示有兴趣测试 Kimi K3,特别看重它作为一种开源且高性价比的替代方案,且不易受到其他 AI 模型中常见的严格拒绝机制的影响。讨论中还包括了关于“SotA”大小写规范的细致争论,以及对 AI 模型发布频率的一些轻松调侃。
 有报道称,具有军用级“军民两用”功能的拦截无人机正在社交媒体上公开向公众销售。对此,美国联邦通信委员会(FCC)主席布兰登·卡尔提议禁止在美国境内进口和销售外国制造的军用无人机。
FCC 的提案旨在限制民众获取包括具备蜂群作战能力在内的先进技术,这些技术构成了重大的国家安全风险。在此之前,有调查显示个人能轻易通过网络购买这些中国制造的作战无人机,引发了广泛关注。
此举是美国政府保障无人机供应链安全计划的一部分。参谋长联席会议主席丹·凯恩将军曾警告称,国内面临无人机威胁不可避免,因此联邦机构正加紧行动以强化美国领空安全。FCC 希望通过限制非政府主体获取这些高性能系统,保护关键基础设施、军事设施和公共集会免受潜在的武器化无人机袭击。
有报道称,具有军用级“军民两用”功能的拦截无人机正在社交媒体上公开向公众销售。对此,美国联邦通信委员会(FCC)主席布兰登·卡尔提议禁止在美国境内进口和销售外国制造的军用无人机。
FCC 的提案旨在限制民众获取包括具备蜂群作战能力在内的先进技术,这些技术构成了重大的国家安全风险。在此之前,有调查显示个人能轻易通过网络购买这些中国制造的作战无人机,引发了广泛关注。
此举是美国政府保障无人机供应链安全计划的一部分。参谋长联席会议主席丹·凯恩将军曾警告称,国内面临无人机威胁不可避免,因此联邦机构正加紧行动以强化美国领空安全。FCC 希望通过限制非政府主体获取这些高性能系统,保护关键基础设施、军事设施和公共集会免受潜在的武器化无人机袭击。
8月至次年1月 · 按周出售 · 限量供应 我们正在拍卖一批 GPU 节点,租期为今年8月至明年1月,按周出售。竞标方式灵活:您可以自定义节点数量、租赁周数以及您的出价。拍卖采用密封竞价,按实际出价支付;结算完成后,所有成交价格将会公示。竞标现已开放,并将于7月31日截止。 参与拍卖 7月31日截止前保持密封 · 同价竞标以先到者为准 注册后即可查看完整规则和每周排期。
**Computable** 是一个全新的 GPU 算力市场,旨在改善高端算力(如 H100)市场碎片化和低效的现状。该平台由来自 Jump Trading 和 Coinbase 的资深人士创立,将 GPU 算力视为一种大宗商品(类似于能源市场),允许用户按具体的日历周进行买卖,而非签署长期且缺乏灵活性的租赁协议。
核心功能包括:
* **细粒度灵活性:** 用户可以购买精确的时间段,无需长期承诺或支付额外溢价。
* **流动性:** 未使用的时段可以转售,将闲置硬件变现。
* **价格发现:** 用户可以通过锁定未来时间窗口的费率,来对冲未来的价格波动风险。
该平台已启动首场拍卖,提供从 8 月到次年 1 月的节点资源。为了在目前充斥着不透明双边交易的市场中促进透明化,Computable 会在结算后公布所有成交价格。目前,团队正在解答社区关于合规性及市场流动性机制的相关问题。
哪些智能体框架目前可用? 该软件包包含适配 AI SDK 和 Pi 的适配器。基础工具是框架无关的,因此你也可以将它们接入自己的智能体循环中。 我可以使用哪些浏览器提供商? 使用 LocalBrowserProvider 在你的机器上运行 Chromium,或者使用 Libretto Cloud、Browserbase、Kernel 和 Steel 的内置提供商。 为什么 SDK 只公开了六个工具? 大多数浏览器任务只需要两个工具:用于读取页面的 browser_snapshot 和用于运行 Playwright 的 browser_exec。其余四个工具用于打开、连接、检查和关闭浏览器会话。 Browser Tools SDK 会取代 Playwright 吗? 不会。它为智能体提供了一套小型工具,并通过 Playwright 运行其 browser_exec 代码。你仍然可以使用 Playwright API。 Browser Tools SDK 是开源的吗? 是的。该软件包在 Libretto 仓库下以 MIT 许可证发布。
Libretto 的开发者开源了 **Browser Tools SDK**,这是一个专为 AI 智能体(AI agents)提供可靠且高效浏览器控制环境的 TypeScript 开发包。
该 SDK 将智能体的浏览器交互简化为仅有的六个工具,核心包括用于获取页面概览以节省上下文的 `browser_snapshot`,以及用于运行原生 Playwright 代码的 `browser_exec`。得益于模型在 Playwright 方面的既有训练,该 SDK 只需极少的指令即可执行复杂任务。
在针对 26 个实时网站任务、对比现有解决方案(如 `agent-browser` 和 `playwright-cli`)的基准测试中,Browser Tools SDK 以 24/26 的成绩并列最高通过率,同时将 Token 使用量降低了约 36%,成本降低了 55%。
主要特性包括:
* **集成简便:** 开箱即用,支持 Vercel 的 AI SDK 和 Pi,并支持自定义实现。
* **架构灵活:** 兼容多种浏览器提供商(如 Libretto Cloud、Browserbase)或本地 Chromium 执行。
* **开源:** 以 MIT 协议发布。
团队欢迎用户提供反馈,并将继续扩展对更多框架的支持。文档和社区链接可在 Libretto 官网及 Discord 获取。