 Tribblix:复古风格的 illumos 发行版
Tribblix 是由 Peter Tribble 创建的开源操作系统。它基于 illumos,将复古风格与现代组件融为一体。
新闻:2026 年 6 月 12 日:Milestone 40 版本现已发布。(更新内容)。请参阅 X86 版本说明。
新闻:2026 年 4 月 21 日:SPARC m34 ISO 镜像现已可供下载,此前已提供从 m33 到 m34 的升级。(SPARC 版本说明。)
重要提示:现已完全移除对 32 位硬件的支持。
尽管 SPARC 版本仍因缺乏测试而存在硬件支持不完善的问题,但 x86 版本已相当稳定。您可以下载镜像、安装到硬盘并直接使用。
[email protected] :: GitHub :: 隐私政策
Tribblix:复古风格的 illumos 发行版
Tribblix 是由 Peter Tribble 创建的开源操作系统。它基于 illumos,将复古风格与现代组件融为一体。
新闻:2026 年 6 月 12 日:Milestone 40 版本现已发布。(更新内容)。请参阅 X86 版本说明。
新闻:2026 年 4 月 21 日:SPARC m34 ISO 镜像现已可供下载,此前已提供从 m33 到 m34 的升级。(SPARC 版本说明。)
重要提示:现已完全移除对 32 位硬件的支持。
尽管 SPARC 版本仍因缺乏测试而存在硬件支持不完善的问题,但 x86 版本已相当稳定。您可以下载镜像、安装到硬盘并直接使用。
[email protected] :: GitHub :: 隐私政策
每日HackerNews RSS
Tribblix 是一款独特的、基于 Illumos 的独立发行版,由 Peter Tribble 开发和维护已超过 15 年。该项目源于对 OpenSolaris 构建方式的探究,它通过弃用现代软件包系统、转而采用传统的 SVR4 软件包,从而在众多 Illumos 发行版中独树一帜。
该项目因其长久的生命力以及对 SPARC 硬件和 x86 系统的持续支持而备受推崇。用户将其描述为一个功能性强、类似于“Slackware”的 Unix 发行版,而非仅仅是一个怀旧项目。它不仅提供 Xfce 等现代桌面环境,还为追求传统美学的用户提供了对 CDE 等经典界面的支持。
社区讨论突显了维护一个独立 Illumos 发行版的挑战,以及在硬件兼容性(特别是在现代系统上)方面所面临的技术障碍。尽管存在这些挑战,用户仍报告称其在各种老旧机器(包括旧款 ThinkPad 和 UltraSPARC 硬件)上运行良好,并称赞它是一种体验不同于 Linux 的 Unix 操作系统的高效方式。
免费的 SQL 转 ER 图工具,浏览器内运行,无需上传任何内容。 Free SQL→ER diagram tool, runs in the browser, nothing uploaded
13 天前
**SQL 转 ER 图**是一款免费、开源的网页工具,可将 SQL `CREATE TABLE` 语句即时转换为交互式实体关系图 (ERD)。它支持 PostgreSQL、MySQL、SQLite 和 SQL Server 等主流 SQL 方言。 该工具完全基于浏览器运行,确保了隐私安全:无需上传数据、无需注册账户、无需安装程序。用户可以通过拖拽表格来自定义布局、添加注释,并可视化查看主外键关系。完成后的图表可以导出为高分辨率的 PNG 或 SVG 文件,或通过共享链接保存。这是一款高效、安全且易于使用的数据库可视化解决方案。
我一直觉得《吃豆人》里的幽灵有点可怜。它们在迷宫里巡逻,把那家伙逼到角落,结果他吃了一颗能量球,反过来却成了它们要逃命。所以我做了一个小游戏,让你终于可以换个角度来玩。吃豆人有自己的 AI,你的任务是在他清空迷宫前抓住他。游戏的转折点和当年让我这个幽灵倒霉的情况一样:如果他吃了能量球,局势就会反转,他会追捕你几秒钟。那时你就得逃跑。你可以在这里玩这个游戏。玩得开心!
最近一篇在 Hacker News 上发布的帖子展示了一个网页版《吃豆人》游戏,玩家可以在其中扮演幽灵,引发了广泛讨论。虽然一些用户觉得这个概念很有趣,但其他人批评其实现手法为“AI 垃圾”,并指出其存在操控迟缓、响应性差以及移动逻辑粗糙等问题。
讨论很快转向了人们对非对称式本地多人游戏的怀旧之情。用户们回忆起由宫本茂设计的 2003 年 GameCube 游戏《吃豆人 Vs.》,该游戏利用 Game Boy Advance 作为私人控制器,同时也提到了《任天堂大陆》中类似的机制。
评论者们还探讨了“沙发多人游戏”的现状,指出尽管在主流 3A 游戏中,这种模式已逐渐被在线联机所取代,但在任天堂 Switch 和 Steam 等平台上,它对于家人和朋友来说依然是一个充满活力的细分领域。该讨论帖还提到了《Crawl》等其他游戏中类似的“英雄对战怪物”机制,并就如何通过模仿原版游戏的特定 AI 模式和移动限制来改进所展示的《吃豆人》原型提出了建议。
图形用户界面为用户与软件系统之间提供了丰富的交互方式。这种丰富性管理起来十分复杂,因此,通过深思熟虑的架构来控制这种复杂性至关重要。“表单与控件”模式适用于流程简单的系统,但当系统复杂度增加时,该模式便难以支撑,大多数人会转向“模型-视图-控制器”(MVC)。遗憾的是,MVC 是最容易被误解的架构模式之一。以该名称命名的系统在实现上存在一系列重大差异,有时还会以“应用模型”、“模型-视图-呈现器”、“表示模型”、“MVVM”等名称来描述。理解 MVC 的最佳方式,是将其视为一套包含以下原则的集合:即表现层与领域逻辑的分离,以及通过事件(观察者模式)实现表现层状态的同步。
这段文字是对 GitHub 仓库页面“RE-Verse-2026-Slides”(由用户 AnalogCyberNuke 创建)的导航与界面描述。 该页面展示了标准的 GitHub 环境,其中包含一个名为 `Reverse26.pdf`(8.09 MB)的文件。界面中包含常见的仓库管理工具,例如分叉(fork)、加星(star)、管理议题(issues)和合并请求(pull requests),以及访问安全或项目洞察信息的选项。所提供的文字主要由顶部导航菜单、侧边栏元素、平台功能链接(如 GitHub Copilot、Actions、Security)以及页脚政策信息组成。文中未显示 PDF 文件的具体内容,仅体现了文件的存在及其周边的 GitHub 框架。
抱歉。
原生加密货币活动运营轻量、审计透明,且能直接对接那些将隐私与开放基础设施视为共同事业的社区。为了确保系统安全可靠,上线初期仅支持 BTC、ETH、XMR、ZEC 和 GLM,后续阶段可能会增加更多币种。您仍可通过项目官网直接捐赠法币(USD/CAD/EUR),但只有通过此活动进行的加密货币捐赠才有资格获得配捐资金。
抱歉。
**Weave** 是一款用于 Git 的实体级语义合并驱动程序,旨在消除不必要的合并冲突。与依赖于行级比较的标准 Git 不同,Weave 使用 `tree-sitter` 来解析代码结构。这使其能够智能地在函数和类级别合并更改,从而确保同一文件不同部分的编辑可以自动集成,无需人工干预。 主要功能包括: * **语义合并:** 当多个智能体或开发人员修改同一文件中的不同实体时,防止冲突发生。 * **协同机制:** 为多智能体工作流程提供可选的基于 CRDT 的层,以便在冲突发生前预先声明实体,从而避免冲突。 * **广泛的兼容性:** 支持 28 种语言(包括 Python、Go、Rust 和 TypeScript)及 5 种数据格式。 * **AI 集成:** 内置 MCP 服务器,使 Claude 等 AI 智能体能够直接与代码库进行交互。 Weave 已通过超过 4,900 次文件合并测试且零回归,旨在简化现代 AI 辅助开发流程。安装简单:通过 Homebrew 安装并运行 `weave setup` 即可配置 Git。请访问完整文档,了解如何将其替换为您现有的行级合并策略。
抱歉。
自 2017 年 CSS Grid 发布以来,开发者们一直在问:“我该如何制作瀑布流布局?”多年来,唯一的选择是使用 JavaScript——但通常既臃肿又脆弱,效果也不尽如人意。现在,CSS Grid Lanes 在浏览器原生层面解决了这一需求。Grid Lanes 在 CSS 工作组内经历了多年的设计、原型制作和辩论。我们对最终成果感到由衷自豪。只需四行 CSS,无需任何库,无需任何框架。它既快速又稳健。本网站由从一开始就参与其中的团队制作。每一个演示、每一张图表、每一项声明都经过了严谨的准确性审查。这正是 Grid Lanes 的工作原理,直接来自源头。我们希望您能用 Grid Lanes 创造出令人惊叹的作品。它的功能远不止于经典的瀑布流布局。我们迫不及待地想看到您的作品。
抱歉。
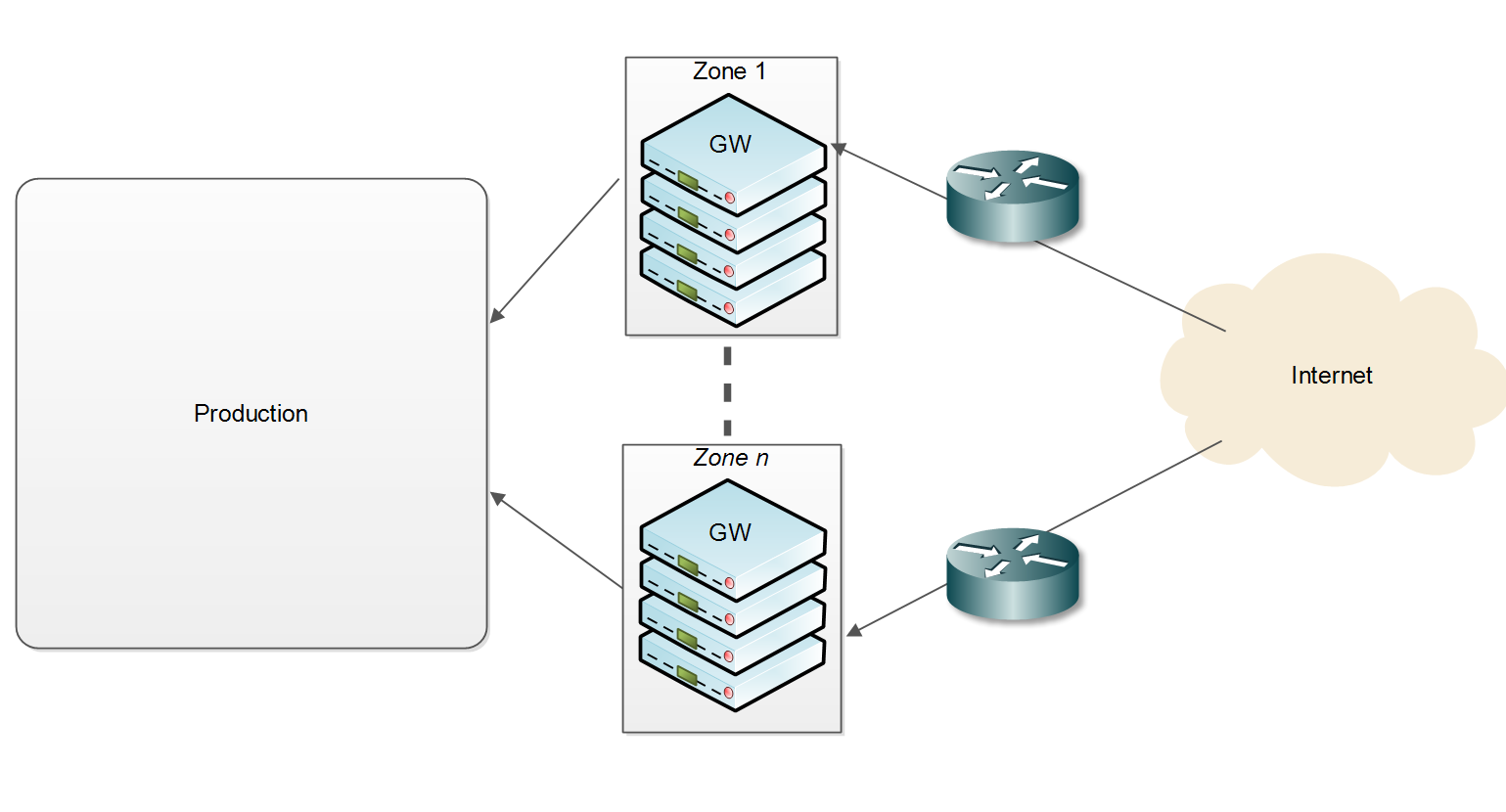 在对客户的反向网关基础设施进行例行安全评估时,研究人员发现了一场长期且复杂的间谍活动。这些使用定制 Linux 内核和 Golang 应用程序的网关正遭到系统性的入侵。
调查始于对 HTTPS 流量中个人身份信息(PII)泄露的分析。研究人员注意到流量分布存在异常,并最终追溯到 NFS-ganesha 服务器和 Linux 内核中的恶意修改。这些修改建立了两个隐蔽通道:一个利用畸形的 NFS “open” 请求进行数据外泄,另一个利用伪文件协助命令与控制(C2)操作。
进一步分析显示,该恶意软件在运行时动态挂钩了 Golang 的 `net/http` 库函数,以拦截并检查解密后的 HTTP 流量。攻击者很可能是通过入侵内核开发人员的构建环境,从而在 CI/CD 构建过程中植入了恶意代码。
研究人员识别出了复杂且经过混淆的有效载荷,以及其他基于 Windows 的恶意软件证据,其中包括一种潜在的 EDR 绕过技术。尽管调查仍在进行中,但该案例凸显了攻击者如何利用基础设施组件(如 NFS 和 CI/CD 流水线)来维持隐蔽、持久的访问并窃取敏感数据。
在对客户的反向网关基础设施进行例行安全评估时,研究人员发现了一场长期且复杂的间谍活动。这些使用定制 Linux 内核和 Golang 应用程序的网关正遭到系统性的入侵。
调查始于对 HTTPS 流量中个人身份信息(PII)泄露的分析。研究人员注意到流量分布存在异常,并最终追溯到 NFS-ganesha 服务器和 Linux 内核中的恶意修改。这些修改建立了两个隐蔽通道:一个利用畸形的 NFS “open” 请求进行数据外泄,另一个利用伪文件协助命令与控制(C2)操作。
进一步分析显示,该恶意软件在运行时动态挂钩了 Golang 的 `net/http` 库函数,以拦截并检查解密后的 HTTP 流量。攻击者很可能是通过入侵内核开发人员的构建环境,从而在 CI/CD 构建过程中植入了恶意代码。
研究人员识别出了复杂且经过混淆的有效载荷,以及其他基于 Windows 的恶意软件证据,其中包括一种潜在的 EDR 绕过技术。尽管调查仍在进行中,但该案例凸显了攻击者如何利用基础设施组件(如 NFS 和 CI/CD 流水线)来维持隐蔽、持久的访问并窃取敏感数据。
抱歉。
为了避免拖着笨重的终端或占用笔记本电脑,作者利用二手的 IBM 7316-TF3 1U 机架式控制台,DIY 了一款便携式独立串行控制台。 该项目涉及将 Tattler Solutions 的串行转 VGA/USB 终端模拟器改装到 IBM 设备中。由于该模拟器硬件不支持 IBM 原装的“UltraNav”键盘,作者将其更换为兼容的 Perixx 超薄键盘。为确保便携性和功能性,作者安装了迷你电源插排、手动 USB/VGA 切换器,并使用魔术贴和 Z 型支架搭建了线缆管理系统。 最终成品允许用户在原生 USB/VGA 连接与专用 VT100 串行终端之间切换,为管理旧式硬件提供了一种紧凑、便携的工具。尽管在粘合剂固化时间和键盘间隙方面遇到了一些小挑战,但成品功能齐全,已成功用作包括 POWER9 Blackbird 和 AT&T 3B2/310 在内的多种系统的控制台。