请启用 JavaScript 并关闭广告拦截器
每日HackerNews RSS
针对近期前沿人工智能(AI)访问受限的情况,智谱 AI 重申了其对彻底开放的承诺,并发布了迄今为止最先进的开源模型 **GLM-5.2**。 智谱认为,通用人工智能(AGI)应成为全球协作的资源,而非少数人垄断的工具。通过保持前沿智能的可访问性和可构建性,他们旨在确保开发者不会因技术被随意撤销而受到影响。 GLM-5.2 专为支持复杂的智能体应用而设计,拥有强大的 100 万长度上下文窗口,并在长程任务完成和编码方面具备行业领先的能力。该模型现已向所有 GLM 编码计划(GLM Coding Plan)用户开放,API 访问权限将于下周上线。此次发布标志着智谱致力于实现人工智能民主化,确保通往 AGI 的道路对所有人保持开放与包容。
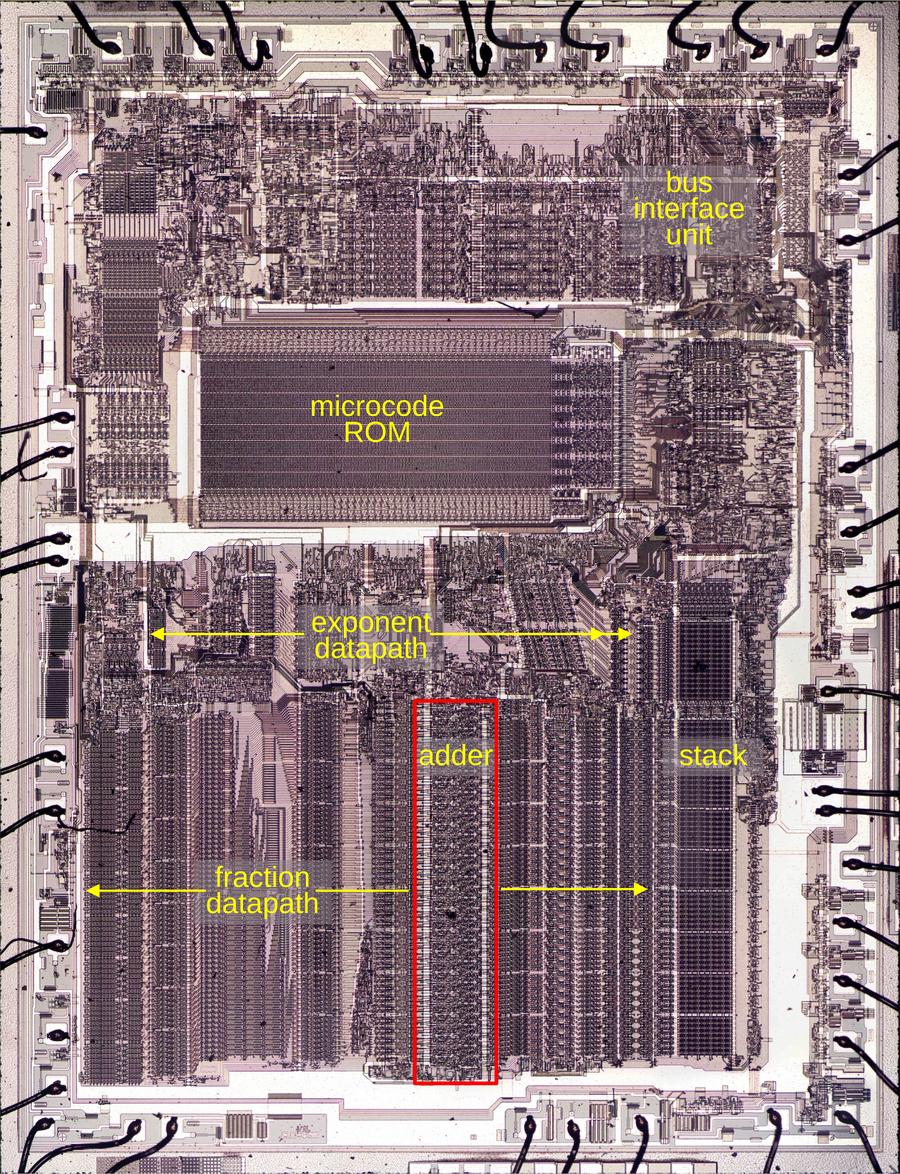 1980年发布的 Intel 8087 是一款开创性的浮点协处理器,它将数学运算性能提升了最高 100 倍。其核心是一个 69 位加法器,它是执行算术运算、超越函数以及除法和平方根等复杂运算的引擎。
为了克服行波进位延迟带来的性能瓶颈,Intel 采用了“曼彻斯特进位链”(Manchester carry chain)技术。该技术利用基于生成(Generate)、传递(Propagate)和删除(Delete)逻辑的并行开关,使进位信号能够高速通过导线,而不会被逻辑门所延迟。为了在芯片有限的晶体管预算内管理复杂性,8087 将加法器组织成 4 位块,并采用“进位跳跃”(carry-skip)电路在各块之间刷新进位信号。
该设计采用 NMOS 晶体管和基于预充电的逻辑系统,加法运算需要两个时钟周期。其架构经过专门优化,以支持硬件加速乘除法所需的舍入位和多位移位操作。通过在速度与硬件约束之间取得平衡,8087 的加法器设计成为了高性能计算的基础架构,证明了高效的电路布局如何能大幅超越当时的各种标准处理方法。
1980年发布的 Intel 8087 是一款开创性的浮点协处理器,它将数学运算性能提升了最高 100 倍。其核心是一个 69 位加法器,它是执行算术运算、超越函数以及除法和平方根等复杂运算的引擎。
为了克服行波进位延迟带来的性能瓶颈,Intel 采用了“曼彻斯特进位链”(Manchester carry chain)技术。该技术利用基于生成(Generate)、传递(Propagate)和删除(Delete)逻辑的并行开关,使进位信号能够高速通过导线,而不会被逻辑门所延迟。为了在芯片有限的晶体管预算内管理复杂性,8087 将加法器组织成 4 位块,并采用“进位跳跃”(carry-skip)电路在各块之间刷新进位信号。
该设计采用 NMOS 晶体管和基于预充电的逻辑系统,加法运算需要两个时钟周期。其架构经过专门优化,以支持硬件加速乘除法所需的舍入位和多位移位操作。通过在速度与硬件约束之间取得平衡,8087 的加法器设计成为了高性能计算的基础架构,证明了高效的电路布局如何能大幅超越当时的各种标准处理方法。
这篇 Hacker News 讨论聚焦于肯·谢里夫(Ken Shirriff)发布的一篇关于 8087 浮点运算芯片加法器架构的技术深度解析。
讨论中的关键见解包括:
* **架构:** 8087 的 69 位加法器使用了大约 2,014 个晶体管。与采用 Kogge-Stone 加法器等复杂设计的现代 CPU 不同,8087 的设计受限于当时可用的金属布线层数。
* **工程演进:** 专家指出,电路设计中的“优化”是一个动态目标,必须与当时的工程能力(如电源电压、晶体管速度和金属密度)相匹配。
* **时序:** 加法器本身并非由时钟驱动;系统微代码会阻塞执行一个周期,以确保信号在进位链中保持稳定。
* **遗产:** 讨论强调了对 8087 进行逆向工程或综合的难度。尽管许多爱好者已在 FPGA 上重现了 8086 CPU,但 8087 因其复杂性仍是一个难以攻克的对象,且受关注度较低,主要原因是现代软件无需专用硬件仿真即可轻松处理浮点运算。
对于个人AI辅助编程,主要有三种策略,每种都在成本和性能之间寻求平衡: 1. **自托管**:涉及购买专用硬件来运行开源模型。虽然没有按 token 收费的费用,但高昂的前期成本和硬件迭代的快速,使得这对大多数用户来说既有风险又往往效率低下。 2. **租用 API 访问权限**:最灵活的选择。通过使用 OpenRouter 等提供商,你可以避免硬件过时,并能随模型更新随时切换至最新版本,且仅需按实际使用量付费。 3. **前沿模型订阅**:订阅 OpenAI 或 Anthropic 等服务对于人工驱动的任务极具价值,但其使用上限使其不适合高频、自动化的智能体工作流。 **最佳实践**:结合多种策略。利用前沿模型订阅进行高层架构设计和复杂推理,同时依靠更便宜的开源 API 来执行机械、重复的任务。通过利用昂贵的模型制定详细规范,并由更便宜的模型填充代码,你可以在大幅降低成本的同时,获得企业级的产出。
这篇 Hacker News 的讨论探讨了 AI 辅助编程的策略,重点在于如何在能力与成本之间取得平衡。
讨论的核心议题之一是对“感觉流编码”(vibe coding)的怀疑——即在几乎无人监督的情况下让 AI 生成大量代码。许多用户认为,这种做法会导致代码质量低劣、难以维护,并造成 Token 的过度消耗。经验丰富的开发者建议,最有效的方法是保持“人在回路”,将 AI 作为完成原子化任务、重构或撰写文档的工具,而非工程判断力的替代品。
主要观点包括:
* **成本管理:** 许多贡献者认为,每月 20 至 100 美元的标准订阅费已足以应对专业级工作。高额的 Token 成本(每月 400 美元以上)通常源于拙劣的提示词工程、过度的上下文加载(如加载过多的工具或技能),以及在简单任务上过度依赖“前沿”模型。
* **高效替代方案:** 用户推荐通过 Claude Code 或 OpenCode 等工具使用高性价比、高性能的 API,例如 DeepSeek(特别是 V4 Flash)。
* **硬件与 API 的选择:** 虽然有人提倡在高端硬件上自托管模型,但大多数人认为这目前仍属于“爱好者”行为。目前的共识是,在本地硬件能力成熟之前,使用托管 API 能够提供更即时的灵活性和成本效益。
尽管具备技术潜力,但 OpenCL 和 SYCL 等便携式 GPU 编程模型未能挑战 NVIDIA 在 AI 领域的 CUDA 主导地位。这种失败源于“开放式竞合”的陷阱以及委员会驱动型开发的固有缺陷。 主要挑战包括: * **创新缓慢:** 标准化、委员会主导的流程无法跟上 AI 快速演进的步伐。 * **生态碎片化:** 由于缺乏统一的参考实现,硬件供应商各自创建了不兼容的分支和专有扩展,破坏了可移植性的目标。 * **性能差距:** 这些标准缺乏对现代 AI 专用硬件(如 Tensor Core)的原生支持。因此,与 CUDA 相比,使用它们往往会导致显著的性能损失。 与此同时,NVIDIA 通过将 CUDA 与 PyTorch 和 TensorFlow 等 AI 框架紧密集成,确保了卓越的开箱即用性能,从而蓬勃发展。 为了在未来取得成功,AI 基础设施项目必须吸取教训,优先考虑单一、高性能的参考实现,保持强有力的领导,并以 AI 研究的速度进行迭代。作者最终认为,委员会式的标准方法并不适合统一 AI 计算,因为相比于官僚式的共识,行业更需要敏捷性、深度的性能优化以及开发者友好的生态系统。
关于 Modular.com 一篇讨论 OpenCL 和 CUDA 的文章,Hacker News 上引发了关于 GPU 计算现状的争论。一位经验丰富的开发者反驳了文中关于“碎片化”导致 OpenCL 失败的观点,他认为其衰落是主要厂商蓄意破坏的结果。
据这位专家称,NVIDIA 为了保护 CUDA 的市场主导地位而故意忽视 OpenCL,而苹果则通过放弃 OpenCL 来实施厂商锁定。此外,他认为 AMD 从高质量的 OpenCL 支持转向举步维艰的 ROCm 实现,导致整个生态系统陷入混乱。虽然 Khronos 尝试转向 Vulkan,但这一过程充满了复杂性,使得 OpenCL 1.2 尽管年代久远,却依然是唯一可行的跨平台标准。
其他参与者则质疑了该开发者的立场,指出行业内缓慢的开发进度是委员会制标准的典型特征。这场对话凸显了行业内更广泛的挫败感:虽然 PyTorch 等高级框架掩盖了这些问题,但跨厂商 GPU 计算 API 的底层环境仍然是一个碎片化且不一致的“噩梦”,无论是 Vulkan 还是更新的计划都未能完全解决这一问题。
Exif(可交换图像文件格式)是一种自 1995 年起沿用至今的元数据标准,用于在图像文件中存储相机设置、时间戳和方向数据。尽管它起源于数码相机,但作为一种虽然陈旧却至关重要的标准,它至今仍嵌入在 JPEG、WebP 和 HEIC 等多种文件格式中。 关键在于,Exif 是可选的且往往不可靠;它可能丢失、被移除或被篡改。一个常见的技术难点涉及“方向标签”(Orientation tag),它指示查看器如何旋转图像,而无需实际更改像素矩阵。开发人员在进行像素级处理前,应先标准化此方向(例如使用 `exiftool` 或 `Sharp`、`PIL` 等库),以避免结果不一致。 元数据不仅限于 Exif;通常还包括 XMP、IPTC、ICC 色彩配置文件以及 C2PA 等较新的标准。开发人员应将所有元数据视为不可信输入。构建图像处理流水线时,最佳实践如下: 1. 在处理像素前,先标准化图像方向。 2. 若涉及隐私问题,请明确移除元数据。 3. 使用 `exiftool` 等成熟工具进行检查,并使用稳健的图像处理库来执行生产任务。 简而言之:不要盲目信任元数据(无论它是否存在或是否准确),请务必有意识地进行处理。
Hacker News 关于 EXIF 元数据的讨论揭示了一个复杂且常令人沮丧的现状。贡献者们将 EXIF 描述为“丛林”——这是一个由不一致的厂商实现、未归档的属性以及多变的数据格式所定义的遗留标准。由于 EXIF 最初源自早期数码相机底层的二进制内存转储,对其进行操作需要极高的技术精确度,这对于现代的高级开发者而言往往极具挑战。
讨论涵盖了几个核心主题:
* **碎片化:** EXIF、IPTC 和 XMP 等重叠标准的存在导致了持续的兼容性问题,不同平台和浏览器处理元数据剥离方式的不一致也是如此。
* **隐私与实用性的争论:** 虽然元数据带来了显著的隐私风险(例如共享精确的 GPS 坐标),但用户也抱怨平台经常剥离时间戳和地理位置等必要数据,导致个人照片整理变得复杂。
* **实用工具:** 尽管 *ExifTool* 因其功能强大而广受好评,但开发者警告称不要在生产流水线中使用它,而倾向于使用经过优化的原生库。
归根结底,参与者将 EXIF 称为“最冠冕堂皇的技术债”——这是一种混乱且老化的标准,尽管它存在诸多缺陷,但在照片溯源和档案记录方面,它依然是不可或缺的工具。
 “正统 C++”(Orthodox C++)是一种编程哲学,主张使用 C++ 语言中极简且稳定的子集,以避免“现代 C++”带来的复杂性。支持者认为,许多语言特性(如异常、RTTI、流和过度的元编程)会引入不必要的运行时开销、隐性成本以及架构上的复杂性。
通过优先编写 C 程序员易于阅读的代码,“正统 C++”旨在构建更易于维护、高度可移植且兼容旧编译器的软件。这种方法不鼓励立即采用新标准,建议至少等待五年以确保稳定性及工具链的广泛支持。与其依赖繁重的抽象或 STL(尤其是那些会进行隐式内存分配的部分),“正统 C++”更推崇一种更手动、更显式的风格,并依赖于 `<stdio.h>` 和 `<math.h>` 等标准 C 库。
归根结底,这一哲学的目标是以简洁为重,而非追逐最新特性,从而确保项目保持易用性,并避免因混合 C 风格错误处理与复杂 C++ 运行时系统而产生的“割裂”。截至 2025 年,该社区已谨慎地批准了对 C++20 部分特性的选择性使用。
“正统 C++”(Orthodox C++)是一种编程哲学,主张使用 C++ 语言中极简且稳定的子集,以避免“现代 C++”带来的复杂性。支持者认为,许多语言特性(如异常、RTTI、流和过度的元编程)会引入不必要的运行时开销、隐性成本以及架构上的复杂性。
通过优先编写 C 程序员易于阅读的代码,“正统 C++”旨在构建更易于维护、高度可移植且兼容旧编译器的软件。这种方法不鼓励立即采用新标准,建议至少等待五年以确保稳定性及工具链的广泛支持。与其依赖繁重的抽象或 STL(尤其是那些会进行隐式内存分配的部分),“正统 C++”更推崇一种更手动、更显式的风格,并依赖于 `<stdio.h>` 和 `<math.h>` 等标准 C 库。
归根结底,这一哲学的目标是以简洁为重,而非追逐最新特性,从而确保项目保持易用性,并避免因混合 C 风格错误处理与复杂 C++ 运行时系统而产生的“割裂”。截至 2025 年,该社区已谨慎地批准了对 C++20 部分特性的选择性使用。
这篇 Hacker News 帖子讨论了“正统 C++”(Orthodox C++),这是一种主张使用 C++ 的最小、最稳定子集的哲学,旨在避免现代特性(如异常、RTTI 和占用大量内存的 STL 容器)所带来的复杂性和“魔法”。
这场讨论反映了 C++ 社区内部的深刻分歧:
* **支持者**认为该语言已变得臃肿且复杂,存在风险。他们偏好“类 C”风格的 C++,看重其可读性、可预测性和高性能。这种观点常见于嵌入式或游戏开发领域,因为这些领域对资源的精细化控制至关重要。
* **批评者**认为这种“正统”方法是倒退或教条的。他们认为元编程、现代容器和异常处理对于提高开发效率、确保安全性以及管理复杂的抽象必不可少。许多人建议,如果开发者觉得 C++ 太过复杂,应该直接转向 Rust 或 Zig 等更现代的语言。
* **中间派**认为,所谓的“最佳”C++ 是主观的,取决于具体项目。参与者强调,C++ 就像一个“自助餐”,挑战不在于特性本身,而在于如何保持纪律并避免不必要的复杂性。
归根结底,这场争论凸显出:尽管 C++ 依然强大,但其多范式的本质导致人们在何为“合理”或“可维护”的代码上存在巨大分歧。
治疗胰腺肿瘤可能揭示了癌症的总开关 New pancreatic cancer drug might open the door to much longer survival times
15 天前
请启用 JavaScript 和 Cookie 以继续。
医学界正热议一种名为 **daraxonrasib** 的新药,它针对的是 KRAS 突变——这一长期被认为“不可成药”的“总开关”驱动了 90% 的胰腺癌和 50% 的结肠癌。
与以往的疗法不同,daraxonrasib 的作用机制是将突变的 KRAS 蛋白“粘附”到另一种蛋白上,从而有效地阻断癌细胞赖以生存的生长信号。在近期的临床试验中,该药物展现出了缩小或稳定肿瘤的巨大潜力,为面临最致命癌症之一的患者带来了希望。
尽管关于此类疗法的长期疗效以及生活方式在癌症管理中的作用仍存在一些争议,但专家们认为这是一项里程碑式的突破。该药物的成功为相关研究打开了大门,试验范围已扩展至其他癌症类型,包括儿童横纹肌肉瘤。
虽然它并非万能的“治愈方法”,但该药物代表了肿瘤学领域迈出的关键且可衡量的一步。随着研究人员不断完善治疗方案并探索联合疗法,科学界对此持乐观态度,认为这一机制将在未来几年成为更有效、更个性化癌症治疗的基石。
美国禁止在人口普查数据中使用差分隐私技术 Noise infusion banned from statistical products published by Census Bureau
15 天前
 美国商务部近期禁止了“噪声注入”(差分隐私的关键组成部分)在人口普查局和经济分析局统计产品中的使用。此举要求相关机构转向以“粗粒化”(降低数据精度)和“抑制”(删除数据)作为保护机密信息的主要方法。
差分隐私被认为是平衡数据效用与隐私的黄金标准。它利用经过校准的噪声来防止个人记录被重构,而此前的数据交换等方法因存在该漏洞已不再安全。通过禁止依赖随机性的技术,政府正迫使各机构放弃目前可用的最有效的隐私风险缓解工具。
批评人士认为,这项命令导致了灾难性的权衡:未来的统计数据发布要么存在严重的安全隐患,要么在功能上毫无用处,尤其是针对小型人口群体的数据。由于竞争性方法较为粗糙,且在抵御现代重构攻击方面效果较差,该禁令可能会阻碍研究人员追踪人口差异。无论其动机是出于政治议程(如不公平选区划分)还是出于对隐私与效用之间权衡难题的逃避,该指令都显著降低了美国政府数据的质量与安全性。
美国商务部近期禁止了“噪声注入”(差分隐私的关键组成部分)在人口普查局和经济分析局统计产品中的使用。此举要求相关机构转向以“粗粒化”(降低数据精度)和“抑制”(删除数据)作为保护机密信息的主要方法。
差分隐私被认为是平衡数据效用与隐私的黄金标准。它利用经过校准的噪声来防止个人记录被重构,而此前的数据交换等方法因存在该漏洞已不再安全。通过禁止依赖随机性的技术,政府正迫使各机构放弃目前可用的最有效的隐私风险缓解工具。
批评人士认为,这项命令导致了灾难性的权衡:未来的统计数据发布要么存在严重的安全隐患,要么在功能上毫无用处,尤其是针对小型人口群体的数据。由于竞争性方法较为粗糙,且在抵御现代重构攻击方面效果较差,该禁令可能会阻碍研究人员追踪人口差异。无论其动机是出于政治议程(如不公平选区划分)还是出于对隐私与效用之间权衡难题的逃避,该指令都显著降低了美国政府数据的质量与安全性。
近期针对人口普查局数据产品中“噪声注入”(差分隐私)的禁令,引发了关于政府数据采集作用的激烈辩论。
禁令的支持者常以选区划分不公和政府权力过度扩张为由,认为统计“噪声”掩盖了真实数据,可能导致数据被操纵,并削弱其在政策决策中的有效性。许多人认为,政府不应收集可能被用于针对特定群体的敏感细颗粒度数据。
相反,批评者认为该禁令是一个危险的举措,将迫使普查局发布容易遭受重识别攻击的数据,从而实质性地损害美国公民的隐私。他们指出,在大数据时代,“匿名化”的数据集很容易通过外部信息进行去匿名化。他们警告称,侵蚀对人口普查隐私的信任将导致回复率下降和数据质量降低,因为个人会因不信任政府而不愿提供准确信息。
这场辩论的深层冲突在于人口普查的目的:它究竟应仅仅是用于分配议席的人数统计,还是用于为重要公共政策和资源配置提供参考的综合人口统计工具。
为了克服本地大语言模型的显存限制,作者将一张 RTX 5080 与一张翻新的 RTX 3090(24GB)进行了组合。通过使用华硕 Prime X570-Pro 主板,将 PCIe 通道配置为 8x/8x 分割模式。 主要设置要求包括: * **BIOS 配置:** 禁用 CSM,启用 Above 4G Decoding 和 ReSize BAR,并将 PCIe 链路速度设置为 Gen 4。 * **驱动设置:** 使用标准的 `nvidia-open` 驱动程序,因为两种不同的 GPU 架构(Ampere 和 Blackwell)无法使用高级 P2P 内核模块。 * **Llama.cpp 优化:** 构建时设置 `CMAKE_CUDA_ARCHITECTURES="86;120"` 以支持两张显卡,并禁用 NCCL 以获得更好的性能。 通过使用 `llama-server`(结合张量分割)将模型分配到两张 GPU 上,作者在运行 Qwen 3.6 (Q8) 等大型量化模型时,成功达到了每秒 80–90+ tokens 的速度。该方案证明,混合使用异构 NVIDIA 架构是扩展显存容量并提升本地 AI 实验推理性能的一种可行途径。
这篇 Hacker News 讨论探讨了在双 GPU(RTX 5080/3090)配置下运行本地大语言模型(特别是 Qwen 3.6 27B)的实用性与权衡。
**主要内容包括:**
* **性能与云端的对比:** 用户通过使用 MTP(多 Token 预测)和投机采样技术,实现了令人印象深刻的推理速度(60–80 tok/s)。尽管 Claude 等云端服务在文笔上更出色,但用户通常更青睐本地模型,因为它们具有可预测的失效模式、不会生成“令人困惑”的代码,且更具数据隐私性。
* **“极客”理念:** 许多贡献者将本地 AI 视为应对未来审查、限制性 API 条款或服务中断的保障。尽管运行高端硬件成本高昂且耗电,但用户更看重基础设施的自主权,而非租用服务。
* **技术优化:** 讨论深入探讨了技术细节,包括通过限制 GPU 功耗来管理发热、使用 Oculink 等专业硬件组建多 GPU 系统,以及为实现最佳解码效果而配置 `llama.cpp`。
* **应用场景:** 除了编程,参与者还分享了本地智能体在现实任务中的成功实践,例如管理杂货库存和自动购物,这突显了 AI 应用正向个性化、本地化方向转变。