持续集成(CI)通常被视为一种“托管计算”挑战,但在 Blacksmith,我们认为它本质上是一个存储问题。随着我们的集群每天创建并销毁数以百万计的短期瞬态虚拟机,传统的存储工具已无法应对这种环境下巨大的数据吞吐量、高并发性以及高延迟要求。 大多数 CI 任务都遵循一种可预测且资源密集型的模式:拉取源代码、设置环境、执行测试以及缓存构建产物。由于这些任务具有瞬时性和高并发性,它们往往会面临冗余数据传输和“冷启动”的问题。标准解决方案(如单任务块设备或通用对象存储)无法处理成千上万个近乎相同的环境的去重复杂性,也无法管理在不受信任的任务之间共享数据所带来的“影响范围”。 其核心挑战在于构建一个能够在极致性能与细致持久性之间取得平衡的系统:即在将绝大多数数据视为临时数据的同时,确保构建产物能被安全地持久化。通过利用全集群数据池化,并摒弃“一刀切”的存储模式,Blacksmith 旨在重新定义 CI 的基础。我们正在构建能够解决特定实际工作负载的系统,将 CI 固有的“频繁变动”转化为统计学上的优势,而非性能瓶颈。
每日HackerNews RSS
抱歉。
 人工智能革命已将开发者的角色从实现者转变为统筹者,预计到 2028 年,90% 的工程师将使用 AI 助手。尽管 AI 极大地加速了编码过程,但也引发了“信任危机”:开发者在交付自己并未完全理解的、基于“感觉编程”(vibe-coded)构建的复杂系统,使维护工作变成了一场高风险的博弈。
核心挑战在于问责制。当 AI 为非核心功能(如自定义网格或表单)生成定制代码时,就埋下了“定时炸弹”。由于 AI 无法提供职业信誉或技术支持合同,人类开发者必须对他们无法验证的代码中的漏洞承担全部责任。
作者主张进行战略性转变:
1. **区分差异化:** 在非核心任务(如营销网站)中自由使用 AI,但针对业务的核心目标,必须保留深厚的专业技术储备。
2. **委派责任:** 为非核心组件依赖专业维护且易于 AI 理解的库。这将会把具体的实现方式外包给那些能够提供变更日志、支持和可靠性的专家,而这是 AI 自身所欠缺的。
归根结底,AI 时代的成功软件工程要求摒弃定制化的“感觉编程”,转向集成受信任、且支持 AI 代理的库,从而让团队在保持高开发速度的同时最大限度地降低风险。
人工智能革命已将开发者的角色从实现者转变为统筹者,预计到 2028 年,90% 的工程师将使用 AI 助手。尽管 AI 极大地加速了编码过程,但也引发了“信任危机”:开发者在交付自己并未完全理解的、基于“感觉编程”(vibe-coded)构建的复杂系统,使维护工作变成了一场高风险的博弈。
核心挑战在于问责制。当 AI 为非核心功能(如自定义网格或表单)生成定制代码时,就埋下了“定时炸弹”。由于 AI 无法提供职业信誉或技术支持合同,人类开发者必须对他们无法验证的代码中的漏洞承担全部责任。
作者主张进行战略性转变:
1. **区分差异化:** 在非核心任务(如营销网站)中自由使用 AI,但针对业务的核心目标,必须保留深厚的专业技术储备。
2. **委派责任:** 为非核心组件依赖专业维护且易于 AI 理解的库。这将会把具体的实现方式外包给那些能够提供变更日志、支持和可靠性的专家,而这是 AI 自身所欠缺的。
归根结底,AI 时代的成功软件工程要求摒弃定制化的“感觉编程”,转向集成受信任、且支持 AI 代理的库,从而让团队在保持高开发速度的同时最大限度地降低风险。
这篇 Hacker News 讨论批评了人工智能在软件工程中的应用,并强调将大语言模型(LLM)集成到开发工作流程时需要权衡利弊。
主要观点包括:
* **质量与呈现:** 用户批评 AI 生成的文章内容重复且冗长,认为简洁的总结或人类原创内容更为有效。
* **精细化实施:** 评论者区分了“氛围编程”(在没有监督的情况下生成代码)与将大语言模型作为高级自动补全工具之间的区别。
* **约束是关键:** 参与者一致认为,大语言模型在受限环境中表现出色,例如遵循既定模式或现有的代码库规范。相反,它们在处理高层架构或设计任务时则表现不佳。
* **预期管理:** AI 在软件工程中的成功取决于具体任务。宽泛、模糊的项目更容易失败,而缩小解决方案的范围能显著提高 AI 辅助输出的可靠性和质量。
“解释深度的错觉”是一种认知偏差,指我们高估了自己对马桶或灯泡等日常用品运作原理的理解。虽然我们每天都在使用这些物品,也自认为对其非常了解,但当试图解释其内部机制时,往往会发现我们的知识其实极其肤浅。 这种错觉包含两个部分:一是相信自己能给出清晰的解释,二是假设自己的知识足够透彻。在被迫详细阐述之前,我们对这些知识空白一无所知;一旦开始解释,我们原本认为的“深度”就会坍塌为“解释的浅薄”。 这一现象普遍存在,从儿童到成人皆受其影响。它特指解释性知识,而非简单的事实或流程。只有在我们错误地认为自己理解某个过程时,这种错觉才会产生;如果我们意识到自己的无知,错觉就不会发生。本质上,解释这一行为就像一面镜子,揭示了我们自以为拥有的知识与实际认知之间的差距。
这篇 Hacker News 的讨论探讨了为何人类常会高估自己对世界的理解——这种现象被称为“解释深度的错觉”。
参与者将其归因于以下几个因素:
* **简化模型**:我们依赖于对日常生存有用的思维框架,却无法涵盖现实世界中事物运作的复杂性和相互关联性。
* **“孩童”视角**:用户指出,孩子那锲而不舍的好奇心往往会暴露这些认知空白。一种普遍的观点是,我们将使用工具或遵循模式的能力误认为是真正理解了其背后的运作机制。
* **沟通与掌握的区别**:评论者指出,成为专家与成为一名好老师是两回事。将复杂系统综合成准确、简单的类比是一项罕见的技能,这导致许多专家在无法清晰解释事物时,会误以为别人“愚蠢”。
* **认知偏差**:讨论中提到了达克效应(Dunning-Kruger effect),指出知识最匮乏的人往往最自信,而专家则更清楚自己知识的局限性。
归根结底,此次讨论认为,承认自己的无知是真正学习的第一步。
 在芝加哥首届修复艺术技术展示会上,八位殡葬师同台竞技,对“僵尸”硅胶人头模型进行修复,展现了这项正逐渐式微的遗体美化技艺。修复艺术曾是美国葬礼传统的支柱,但如今正面临挑战:火葬的普及、成本的上升,以及一种崇尚“坦然面对死亡”的文化,往往将此类行为视为昂贵、过时或虚伪。
对于像安东尼·萨尔迪瓦(Anthony Saldivar)——一位在守护逝者的“牧羊犬”角色中找到人生意义的资深从业者,以及强调开棺瞻仰对尊严和社区意义的丹妮尔·科尔基特(Danielle Colquitt)等参赛者而言,这项工作是慈悲的结晶。自杰西卡·米特福德(Jessica Mitford)1963年的深度报道以来,批评者认为这些仪式掩盖了死亡的真相。然而,随着现代社会趋向于直接火葬和私人化的“被剥夺的”悲伤,这些专家认为,他们的艺术提供了一种最后且至关重要的尊重。
尽管殡葬业日益将修复视为一项可有可无、利润微薄的服务,但支持者坚持认为,这些为逝者进行的精细“修饰”是为生者服务的,它为缅怀逝者提供了一个必要且复杂的过渡。
在芝加哥首届修复艺术技术展示会上,八位殡葬师同台竞技,对“僵尸”硅胶人头模型进行修复,展现了这项正逐渐式微的遗体美化技艺。修复艺术曾是美国葬礼传统的支柱,但如今正面临挑战:火葬的普及、成本的上升,以及一种崇尚“坦然面对死亡”的文化,往往将此类行为视为昂贵、过时或虚伪。
对于像安东尼·萨尔迪瓦(Anthony Saldivar)——一位在守护逝者的“牧羊犬”角色中找到人生意义的资深从业者,以及强调开棺瞻仰对尊严和社区意义的丹妮尔·科尔基特(Danielle Colquitt)等参赛者而言,这项工作是慈悲的结晶。自杰西卡·米特福德(Jessica Mitford)1963年的深度报道以来,批评者认为这些仪式掩盖了死亡的真相。然而,随着现代社会趋向于直接火葬和私人化的“被剥夺的”悲伤,这些专家认为,他们的艺术提供了一种最后且至关重要的尊重。
尽管殡葬业日益将修复视为一项可有可无、利润微薄的服务,但支持者坚持认为,这些为逝者进行的精细“修饰”是为生者服务的,它为缅怀逝者提供了一个必要且复杂的过渡。
最近 Hacker News 上围绕《哈珀斯》(Harper's)杂志一篇关于殡葬师这一“濒危艺术”的文章展开了讨论,揭示了不同社会在处理死亡问题上,在全球范围和经济层面存在显著差异。
评论者们分享了个人经历,说明了美国葬礼成本高昂且往往不透明的现状;在这里,火葬价格会根据殡仪馆是否拥有自己的火葬场或将服务外包而产生巨大波动。讨论还揭示了鲜明的国际差异:美国的殡葬习俗通常涉及大量的遗体修复和防腐处理,但这在英国和欧洲许多地区被视为罕见。
关于时间节点的文化规范也存在很大差异;在一些地区,葬礼会在几天内举行,而在其他地区(如英国部分地方)则可能面临数周的延误。对话还涉及了这些最后仪式所承载的情感重量、该行业以掠夺性定价闻名的声誉,以及如日本电影《入殓师》中对这一职业的刻画。归根结底,这一讨论强调了殡葬习俗与当地法规、文化传统以及对逝者应如何尊重的不同期望之间有着深刻的联系。
克里斯托弗·诺兰耗资 2.5 亿美元改编的《奥德赛》是一部宏大的合家欢式视听盛宴,它更侧重于爆炸性的技术成就,而非情感或思想的深度。虽然电影映照了荷马史诗中的主题——如空间、时间和记忆的复杂性——但最终未能将这些概念转化为可信的角色弧线或逻辑连贯的道德论述。 该片采取了“极简主义”的反面——“极繁主义”手法,屏幕充斥着喧嚣与动作,却让片中的人物显得单薄且肤浅。马特·达蒙饰演的奥德修斯缺乏原著中那种“狡黠”的复杂性,而影片试图强行植入关于仇外心理和反恐战争的现代政治隐喻,也导致了叙事的混乱。此外,影片台词空洞且说教意味浓厚,缺乏同类改编作品中应有的心理细腻感。 尽管该片在伦理上引发了争议——因在被占领的西撒哈拉拍摄——但它仍是一项重要的文化事件。通过将观众带回电影院并重新激发人们对这部基石史诗的兴趣,这部电影或许能无意中鼓励观众去阅读荷马的原著,从而在文学参与度日益下降的时代,为文学研究起到一定的推动作用。
抱歉。
美国住宅代理(将恶意互联网流量通过毫无戒心的家庭网络进行路由)是垃圾信息、社交媒体操纵和网络攻击的重要推手。这些代理通常通过被入侵的智能电视、免费VPN或恶意软件实现,由于其源自合法的家庭IP地址,平台方难以将其封锁。 这造成了系统性的安全漏洞。虽然“威胁情报”公司通过追踪这些IP牟利,但他们几乎没有动力去解决这一问题。此外,该问题还构成了实质性的国家安全风险,助长了外国影响力行动、身份盗窃和僵尸网络活动。 为缓解这一问题,政府应将这些代理网络视为严重威胁。此外,大型互联网服务提供商(ISP)必须承担起责任,监测可疑流量并提醒设备被入侵的客户。归根结底,解决住宅代理问题对于维护安全、健康的互联网基础设施至关重要。
关于“住宅代理服务器作为国家安全威胁”的 Hacker News 讨论,核心在于这些网络究竟构成系统性危险,还是仅仅是网络安全状况不佳的症状。
**关键观点:**
* **安全威胁与症状:** 许多评论者认为,住宅代理是物联网设备安全性不足和软件实践落后的副产品。他们主张从根本上改善设备安全性和互联网服务提供商(ISP)的透明度,而非采取“打地鼠”式的封禁手段。
* **“国家安全”论调:** 一个反复出现的批评是,将其贴上“国家安全威胁”的标签,往往是一种政治暗语,旨在为加强政府监控、互联网监管及侵蚀数字隐私辩护。
* **合法使用与滥用:** 参与者区分了以隐私为导向的自愿代理使用与通过恶意软件驱动的僵尸网络。虽然网页抓取和比价网站依赖这些代理来绕过激进的 IP 封锁,但其他人指出,同样的网络也为僵尸网络、广告欺诈和网络攻击提供了便利。
* **基础设施问题:** 讨论中还涉及运营商级 NAT(CGNAT)和 IPv6 普及缓慢是否加剧了这一问题。这些因素模糊了恶意流量,导致 ISP 难以区分合法用户和基于代理的恶意行为者。
Netflix旗下Eyeline Studios的前副总裁兼创意总监凯文·贝利(Kevin Baillie)正对该公司提起不当解雇诉讼。贝利声称,他在一次公司“信任练习”中透露自己曾因母亲去世后患上临床抑郁症,并在医疗监督下接受了氯胺酮(ketamine)治疗,随后便遭到了解雇。 诉讼称,尽管该治疗是处方医疗行为,但Netflix仍将其视为涉嫌滥用娱乐性药物进行调查。贝利于2026年4月被解雇,公司法律顾问明确表示,氯胺酮疗法是他被解雇的原因之一。 此外,贝利认为公司的理由虚伪,因为在首席执行官杰夫·夏皮罗(Jeff Shapiro)的领导下,公司企业文化中充斥着酒精。诉讼列举了许多管理层在公司活动和办公室内带头并纵容酗酒的案例。曾参与《哈利·波特》和《加勒比海盗》等大型系列电影制作的贝利,目前正寻求陪审团审判,要求赔偿工资损失、精神损害赔偿及惩罚性赔偿,并称公司在调查后不公平地拒绝支付遣散费。
据报道,一名Netflix高管在公司务虚会期间,于一场旨在建立“脆弱性与信任”的练习中透露了自己正在接受医生监管下的氯胺酮治疗,随后被解雇。该高管凯文·贝利(Kevin Baillie)称,他是因公司鼓励坦诚交流才分享了这一信息,但Netflix后来以该治疗为由将其解雇,称此举引发了对其进行娱乐性药物使用的担忧。
这一事件在Hacker News上引发了关于现代企业文化的激烈讨论。许多评论者认为,“展现真实自我”的倡议往往是旨在淘汰异见者或识别“害群之马”的陷阱。许多专业人士的共识是,职场务虚会绝非安全空间,员工应保持严格的界限,将雇主与员工的关系视为一种交易性且本质上带有对抗性的关系。
尽管一些参与者为建立真实职场关系的价值进行了辩护,但主流观点警告称,人力资源部门的存在是为了保护公司,而非个人。外界普遍建议,切勿在专业场合主动披露个人医疗、宗教或政治信息,因为这类披露常被用于评估“文化契合度”或作为解雇的理由。
作者是一位 Modal 员工。他描述了在自己的私有基础设施上部署开源模型(Kimi K3)后,获得了一种出人意料的自由感。作者通常依赖 Claude 或 ChatGPT 等商业 AI 服务,但为了节省副项目的订阅费用,他寻求了一种个人化的替代方案。 利用公司平台,他仅用了五分钟就成功建立了一个私有推理端点。这种转变带来了一种意想不到的自主感和“数字喘息空间”。他将这种体验比作从臃肿、功能繁多的文本编辑器转向简洁、高效的 Vim。通过切断对外部提供商的依赖并掌控自己的数据流,作者感受到了一种新获得的独立与清晰,这凸显了自托管 AI 工具在心理层面上的吸引力。
此 Hacker News 讨论帖探讨了从依赖昂贵的“前沿”AI 模型(如 Claude Opus)转向使用更灵活的开源权重模型(如 DeepSeek 或 Kimi)的趋势。
**核心要点:**
* **效率与臃肿:** 许多开发者认为,为整个应用程序使用传统的“一次性”提示词往往会导致代码臃肿且过度设计。通过将项目分解为小型、有针对性的功能并进行迭代,开发者发现小模型表现得与最昂贵的模型一样好,甚至更好。
* **成本与自主权:** 用户发现小模型的 API 成本微不足道,几美元的额度有时可以使用数周。除了成本,人们还倾向于“掌控技术栈”,并通过避免依赖单一企业提供商来确保数据隐私。
* **“工具框架”至关重要:** 开发体验的质量往往更多地取决于“工具框架”(如 Claude Code 或自定义脚本),而非模型本身。
* **市场颠覆:** 评论者指出,开源竞争正在迅速使 AI 商品化,迫使价格陷入“逐底竞争”,并削弱了主流 AI 实验室的议价能力。
 若您在乘坐车辆时使用 iPhone 感到晕车,可以开启“车辆动态效果”功能。此功能会在屏幕边缘显示跟随车辆运动的动画圆点,且不会遮挡您的屏幕内容。
**如何开启:**
前往“设置” > “辅助功能” > “动态效果” > “显示车辆动态效果”。您可以将其设置为“自动”,这样仅在手机检测到车辆运动时才会触发圆点;也可以通过控制中心手动管理。
**自定义设置:**
在设置菜单中,您可以根据个人喜好调整圆点样式(常规或动态)、颜色以及可见度(圆点大小和频率)。
**重要安全提示:**
此功能仅供乘客使用。**请勿在驾驶车辆时**或需要保持注意力的安全情况下使用“车辆动态效果”。为获得最佳效果,请在面向前方乘坐时使用此功能。
若您在乘坐车辆时使用 iPhone 感到晕车,可以开启“车辆动态效果”功能。此功能会在屏幕边缘显示跟随车辆运动的动画圆点,且不会遮挡您的屏幕内容。
**如何开启:**
前往“设置” > “辅助功能” > “动态效果” > “显示车辆动态效果”。您可以将其设置为“自动”,这样仅在手机检测到车辆运动时才会触发圆点;也可以通过控制中心手动管理。
**自定义设置:**
在设置菜单中,您可以根据个人喜好调整圆点样式(常规或动态)、颜色以及可见度(圆点大小和频率)。
**重要安全提示:**
此功能仅供乘客使用。**请勿在驾驶车辆时**或需要保持注意力的安全情况下使用“车辆动态效果”。为获得最佳效果,请在面向前方乘坐时使用此功能。
Hacker News 社区近日讨论了苹果的“车辆运动提示”(Vehicle Motion Cues)功能。该功能旨在通过在屏幕上显示随车辆运动而移动的动画圆点,以缓解乘客的晕车感。
用户普遍对该功能表示赞赏,指出它有效调和了静止屏幕与内耳感知到的运动之间的感官冲突。许多参与者分享了个人成功案例,称这些提示使他们能够在乘车、乘火车甚至乘渡轮时工作或阅读,而不会感到恶心。
讨论还涉及了关于“隐藏”辅助功能的更广泛话题。虽然一些用户批评苹果将如此实用的工具埋在设置中,缺乏明确的引导机制,但另一些人则指出,该公司对“理想路径”的关注往往能带来精致但低调的创新。尽管安卓系统上存在一些类似的第三方应用,但用户指出,像苹果这样基于传感器集成的原生实现效果往往更好。总之,这篇讨论凸显了深思熟虑的、基于传感器的 UI 设计如何能够解决长期存在的生理不适,从而为易晕车的人群改善旅行体验。
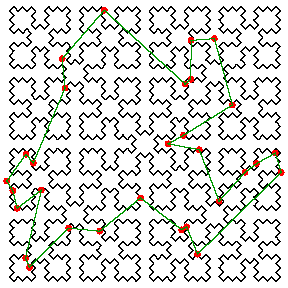 由 L. Platzman 与本文作者共同开发的填空曲线(SFC)启发式算法,为解决旅行商问题(TSP)提供了一种高效方法。该算法通过将二维空间中的点映射到一条连续曲线上,对位置进行排序,使相邻点保持在曲线的邻近位置,从而在无需显式计算距离的情况下生成可行的路径。
尽管 SFC 解通常比理论最优解长 25%–34%,但该算法具有显著的实际优势:它速度极快,仅需 $O(n \log n)$ 的时间,且高度可并行化,易于更新。此外,它还允许对曲线进行简单划分,从而简化了多车辆物流管理。
这些效率优势使其在现实世界中得到了广泛应用,涵盖了“送餐上门”服务、红十字会血液配送、工业绘图仪优化以及商业地理信息系统(GIS)软件等领域。SFC 启发式算法是计算密集型“重型”优化软件包的一种“轻量级”替代方案。虽然重型方法可能需要数年时间才能计算出完美路线,但 SFC 启发式算法能在几秒钟内提供近乎最优的解。这种以牺牲绝对路径长度为代价,换取极致速度与简洁性的权衡,使其成为解决大规模路径规划难题的有力工具。
由 L. Platzman 与本文作者共同开发的填空曲线(SFC)启发式算法,为解决旅行商问题(TSP)提供了一种高效方法。该算法通过将二维空间中的点映射到一条连续曲线上,对位置进行排序,使相邻点保持在曲线的邻近位置,从而在无需显式计算距离的情况下生成可行的路径。
尽管 SFC 解通常比理论最优解长 25%–34%,但该算法具有显著的实际优势:它速度极快,仅需 $O(n \log n)$ 的时间,且高度可并行化,易于更新。此外,它还允许对曲线进行简单划分,从而简化了多车辆物流管理。
这些效率优势使其在现实世界中得到了广泛应用,涵盖了“送餐上门”服务、红十字会血液配送、工业绘图仪优化以及商业地理信息系统(GIS)软件等领域。SFC 启发式算法是计算密集型“重型”优化软件包的一种“轻量级”替代方案。虽然重型方法可能需要数年时间才能计算出完美路线,但 SFC 启发式算法能在几秒钟内提供近乎最优的解。这种以牺牲绝对路径长度为代价,换取极致速度与简洁性的权衡,使其成为解决大规模路径规划难题的有力工具。
抱歉。