修复师记录了一台报废 PC Engine LT 艰难的复活过程。经检查,该主机的电源电路附近有严重的电解液泄漏,需要拆除 HuCard 插槽和扩展总线接口进行彻底清洁和超声波处理。 尽管更换了所有电容,主机仍无反应。进一步排查发现,一个 6.5V 的稳压器(M5291FP)损坏,更换后电源和声音恢复正常,但 LCD 屏幕仍无法显示。问题最终定位在负责为屏幕提供负电压的变压器(T500)损坏。 在尝试维修原装变压器时意外将其损毁,修复师随后成功设计了一个紧凑的定制电路来产生所需的电压。该方案完美嵌入外壳内,最终使屏幕恢复显示,标志着这项艰巨的修复工程圆满完成。
每日HackerNews RSS
抱歉。
这份文档提供了对 TI-84 Plus (OS 2.55MP) ROM 的全面技术分析。该系统由 Zilog Z80 处理器驱动,具有 64 KiB 的地址限制,通过复杂的内存分页方案和“bcall”系统调用机制来突破内存限制,从而访问其 1 MiB 的闪存和 128 KiB 的 RAM。 该操作系统构建于四大架构支柱之上: 1. **分页/bcall**:管理闪存库中的代码与数据。 2. **浮点运算引擎**:通过 OP1–OP6 寄存器处理 9 字节 BCD 数学运算。 3. **变量分配表 (VAT)**:管理程序和矩阵等存储对象。 4. **记号化器/解析器**:TI-BASIC 的执行引擎。 该文档涵盖了 14 个核心系统模块(涉及中断、I/O、LCD 和内存管理),以及针对绘图、统计和 USB 连接等用户功能进行深入探讨的“子文档”。分析内容按置信度([已确认]、[标准]、[假设])分类,并辅以反汇编项目和构建工具。本仓库作为 TI-OS 的功能图谱,为系统内部 API、内存布局和执行流程提供了详尽的参考。
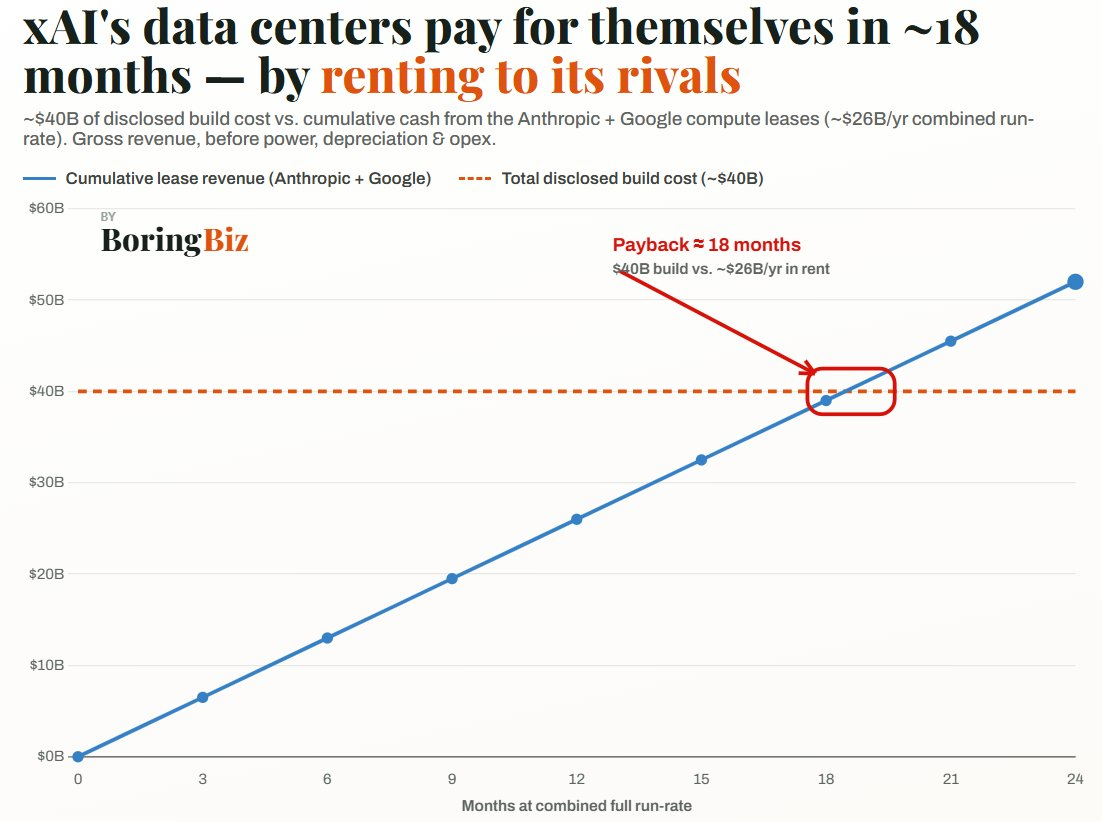 xAI 近期与 Anthropic 和 Google 达成多项高额基础设施协议,向其出租了位于孟菲斯数据中心的大量 GPU 算力。这些合作每月价值超过 20 亿美元,为现已与 SpaceX 合并的实体提供了即时收入,引发了外界对于该公司在潜在巨额 IPO 前进行财务运作的猜测。
这些交易有着实际的考量:Anthropic 正面临严重的算力短缺,而 xAI 以创纪录速度构建基础设施的独特能力,为行业持续的算力紧缺提供了关键解决方案。尽管怀疑论者认为,这些举措可能是受马斯克与 OpenAI 的竞争关系或为了提升 SpaceX 估值的动机驱动,但这些交易更可能反映了对过剩算力务实的货币化处理以及战略重心转移。
通过出租原本计划用于其模型 Grok 的算力,xAI 似乎正在对冲风险。归根结底,xAI 正越来越不像一家传统的 AI 实验室,而更像一家高增长的数据中心房地产投资信托(REIT)。这些合作关系的长期成功以及未来的 IPO 前景,取决于这种基础设施主导地位能否与其在尖端 AI 竞赛中保持竞争优势并行不悖。
xAI 近期与 Anthropic 和 Google 达成多项高额基础设施协议,向其出租了位于孟菲斯数据中心的大量 GPU 算力。这些合作每月价值超过 20 亿美元,为现已与 SpaceX 合并的实体提供了即时收入,引发了外界对于该公司在潜在巨额 IPO 前进行财务运作的猜测。
这些交易有着实际的考量:Anthropic 正面临严重的算力短缺,而 xAI 以创纪录速度构建基础设施的独特能力,为行业持续的算力紧缺提供了关键解决方案。尽管怀疑论者认为,这些举措可能是受马斯克与 OpenAI 的竞争关系或为了提升 SpaceX 估值的动机驱动,但这些交易更可能反映了对过剩算力务实的货币化处理以及战略重心转移。
通过出租原本计划用于其模型 Grok 的算力,xAI 似乎正在对冲风险。归根结底,xAI 正越来越不像一家传统的 AI 实验室,而更像一家高增长的数据中心房地产投资信托(REIT)。这些合作关系的长期成功以及未来的 IPO 前景,取决于这种基础设施主导地位能否与其在尖端 AI 竞赛中保持竞争优势并行不悖。
关于 xAI 转向成为“算力房东”的讨论在 Hacker News 上引发了激烈争议。批评者与支持者都在分析,为何 xAI 和 SpaceX 会从单纯开发前沿模型,转变为向 Google 和 Anthropic 等竞争对手出租海量数据中心容量。
**讨论的核心观点包括:**
* **财务机制:** 许多用户认为,这是一种收回巨额资本支出(CapEx)的策略性举措。通过出租基础设施,xAI 能够产生直接的现金流来抵消 GPU 和电力的昂贵成本,从而有效地转型为一家“基础设施即服务”(IaaS)提供商。
* **“泡沫”争论:** 持怀疑态度者担心 AI 行业正通过循环融资助长泡沫——即大型科技公司投资 AI 初创公司,而初创公司又将这些资金支付给同一批公司以购买云服务或算力。他们警告称,一旦这种投机行为“曲终人散”,其后果可能堪比互联网泡沫破裂。
* **基础设施与智能:** 支持者认为,xAI 正在利用真实且长期的算力短缺局面。他们主张,通过掌握快速构建大规模数据中心的能力,xAI 正在将自身定位为 AI 技术栈中的关键一环,而不论 Grok 是否能在大型语言模型(LLM)竞赛中胜出。
* **风险:** 各界仍对这些快速建设的数据中心所带来的环境影响、硬件的快速折旧,以及建立在可能不可持续的“代币最大化”企业支出基础上的行业长期生存能力表示担忧。
Bloomberg 需要帮助?请联系我们 我们检测到您的计算机网络有异常活动。 为继续访问,请勾选下方方框以证明您不是机器人。 为什么会出现此情况? 请确保您的浏览器已启用 JavaScript 和 Cookie,且未拦截其加载。 欲了解更多信息,请查阅我们的《服务条款》和《Cookie 政策》。 需要帮助? 有关此消息的咨询,请联系我们的支持团队,并提供下方的参考 ID。 拦截参考 ID:6fd5ddd1-6360-11f1-af8c-ec657488ff5a 订阅 Bloomberg.com,随时随地获取最重要的全球市场新闻。 立即订阅
一项近期民意调查显示,如果在英国脱欧投票十年后举行新的公投,结果将会逆转。这一发现引发了 Hacker News 上激烈的讨论,反映出人们对英国脱欧后的经济表现及文化认同存在严重分歧。
脱欧的批评者指出,多项研究表明英国的国内生产总值(GDP)、贸易额和商业投资均出现显著下滑,并认为英国在经济上处境更糟,且正遭受“后帝国”时代的不稳定性困扰。相反,一些评论者将英国当前的困境归咎于治理不善和全球性因素,而非脱欧本身;另一些人则对长期经济预测的可靠性提出了质疑。
关于移民和民族认同的讨论也演变成了一场激烈的争论。一些用户对英国文化和社会凝聚力所受到的侵蚀表示担忧,并将其与日本的单一民族性进行了比较。另一些人则驳斥这些论点为“白人至上主义”言论或仇外心理,反驳称移民在经济上是净增益,人口结构的变化是全球化社会中自然且无害的一面。归根结底,这一讨论凸显了脱欧在多大程度上仍然是一个极具争议的象征,反映了人们对英国全球地位、经济未来以及民族特性演变的广泛焦虑。
**Sydtest** 现已全面支持变异测试。该功能通过自动向代码中引入“变异”,并验证测试套件能否识别出这些变异,从而提供了一种评估测试质量的稳健方法。 从功能上讲,如果代码被修改后测试套件依然通过(即“变异存活”),则说明测试覆盖存在漏洞;如果测试失败(即“变异被杀灭”),则说明测试覆盖有效。在人工智能生成代码的时代,代码产出量往往超过了人工审查和传统测试方法的承载能力,这种客观、自动化的流程显得尤为重要。通过实施这种独立于 AI 的检查机制,开发者可以确保代码得到真正的验证,而非仅仅看起来正确。 Sydtest 与 Nix 无缝集成,开发者可直接将变异检查添加到 `flake.nix` 中。该工具提供人类可读和机器可读两种格式的报告,并支持通过注解排除对非关键代码(如调试日志)的测试。随着人工智能在开发领域的普及,变异测试提供了一种必要的“完整性检查”,以确保测试套件始终保持可靠且全面。
抱歉。
**Music Decoy** 可以防止系统“音乐”应用在按下播放键、使用蓝牙耳机或结束通话时自动启动。macOS 的 `rcd` 守护进程会在没有其他媒体活动时,一旦收到播放指令便会触发“音乐”应用;而 Music Decoy 会拦截这一进程。 **自定义:** 自 v1.1 版本起,你可以配置该应用以启动指定的播放器(如 Spotify)来替代“音乐”。请在终端(Terminal)中运行以下命令: `defaults write com.lowtechguys.MusicDecoy mediaAppPath /Applications/Spotify.app` 如需重置,请使用: `defaults delete com.lowtechguys.MusicDecoy mediaAppPath` **应用管理:** 由于 Music Decoy 在后台运行且没有 Dock 图标或菜单栏图标,你必须通过“活动监视器”或在终端中运行 `killall 'Music Decoy'` 来关闭它。 **为什么选择它?** 与禁用 `rcd` 守护进程(会导致媒体快捷键完全失效)或使用 *noTunes* 等工具(在“音乐”应用启动后将其杀掉)不同,Music Decoy 会主动将播放指令引导至你偏好的应用程序,从而提供更流畅、更节省资源的使用体验。
Hacker News 上的这篇讨论探讨了一种防止 Apple Music 在 macOS 上自动启动的巧妙解决方案,该问题通常由意外触碰耳机或键盘上的“播放”键触发。
文中提到的方案“Music Decoy”是一个轻量级实用程序,它通过模拟与官方 Music 应用相同的 bundle identifier(包标识符)来运行进程,从而产生冲突,阻止真实应用启动。用户称赞这是一种优雅且低代码的工程方案,与那种通过循环强制杀死进程的暴力脚本形成了鲜明对比。
讨论凸显了用户对苹果“排斥用户”设计的普遍不满,特别是无法卸载 Apple Music 或将媒体键重映射到 Spotify 或 VLC 等首选替代应用。许多贡献者认为这种强制集成是一种“服务加售”策略。虽然一些用户提到了 *noTunes* 等长期存在的替代方案,但也有人表达了通过“氛围编码”(vibe code)自行开发工具以夺回本地媒体库控制权的强烈愿望。这些对话反映出一种更广泛的观点:苹果已从提供以用户为中心的优质操作系统,转向优先考虑服务订阅和激进的生态锁定的模式。
此页面为 2026 年 6 月 8 日举办的苹果主题演讲官方活动门户。页面确认直播已结束,演示视频回放将很快发布。页面提供了观看美国手语(ASL)及非手语版本活动的链接,并包含在各类苹果及非苹果设备上实现最佳观看效果的技术要求。此外,该页面也作为 Apple.com 的综合网站地图,提供产品类别(Mac、iPhone、Vision 等)、服务(Apple Music、TV+、Wallet)、支持资源、商务与教育门户,以及有关苹果价值观和投资者关系的企业信息等详尽的导航菜单。
抱歉。
 研究人员日益担忧全球 50 岁以下成年人癌症发病率上升的问题。虽然专家们提出了各种潜在原因,包括超加工食品、肥胖和农用化学品,但目前仍未找到明确的解释。
数据表明,这并非单一现象,而是几种截然不同的趋势。部分增长与临床定义的改变和检测方法的改进有关,例如胰腺癌。然而,其他癌症(尤其是结直肠癌、子宫癌和肝癌)的发病率确实出现了激增,尤其是在较年轻的“出生队列”中。
专家警告称,随着这一群体年龄增长,这种上升趋势可能预示着一场更广泛的公共卫生危机。尽管肥胖是多种癌症的已知风险因素,但临床医生指出,许多年轻患者身体健康,并不符合传统的风险特征。因此,研究人员正将重点转向识别可能对年轻一代产生独特影响的新型环境暴露和生物触发因素。了解这些因素至关重要,因为今天早发的诊断可能预示着这一代人在步入中老年时,癌症负担将大幅增加。
研究人员日益担忧全球 50 岁以下成年人癌症发病率上升的问题。虽然专家们提出了各种潜在原因,包括超加工食品、肥胖和农用化学品,但目前仍未找到明确的解释。
数据表明,这并非单一现象,而是几种截然不同的趋势。部分增长与临床定义的改变和检测方法的改进有关,例如胰腺癌。然而,其他癌症(尤其是结直肠癌、子宫癌和肝癌)的发病率确实出现了激增,尤其是在较年轻的“出生队列”中。
专家警告称,随着这一群体年龄增长,这种上升趋势可能预示着一场更广泛的公共卫生危机。尽管肥胖是多种癌症的已知风险因素,但临床医生指出,许多年轻患者身体健康,并不符合传统的风险特征。因此,研究人员正将重点转向识别可能对年轻一代产生独特影响的新型环境暴露和生物触发因素。了解这些因素至关重要,因为今天早发的诊断可能预示着这一代人在步入中老年时,癌症负担将大幅增加。
这篇 Hacker News 讨论探讨了 50 岁以下人群癌症发病率上升的现象,专家认为这一趋势十分复杂,且很可能是多种因素共同作用的结果。
参与者提出了诸多理论,反映出目前对于主要成因尚未达成共识。主要的担忧领域包括:
* **饮食与代谢:** 超加工食品、肥胖和胰岛素抵抗的增加是关注焦点。一些人认为,现代饮食中膳食纤维摄入不足和营养匮乏是重要原因。
* **环境因素:** 许多评论者指向了普遍存在的毒素,包括 PFAS(“永久性化学物质”)、微塑料、杀虫剂、除草剂和室内空气污染。
* **生活方式的改变:** 现代生活中的诸多变化,如长期的心理压力、睡眠不足和久坐行为,常被认为是导致全身性炎症的潜在因素。
* **传染性疾病:** 一些用户指出,HPV(尤其是其在结直肠癌和口咽癌发病率上升中的作用)是一个关键因素。
许多参与者对缺乏明确答案表示沮丧,而另一些人则告诫不要陷入“单一成因”的思维误区,并指出癌症是一种多因素疾病。这场辩论突显了公共卫生数据、个人观察以及对食品和制药行业企业资助研究的怀疑态度之间的张力。
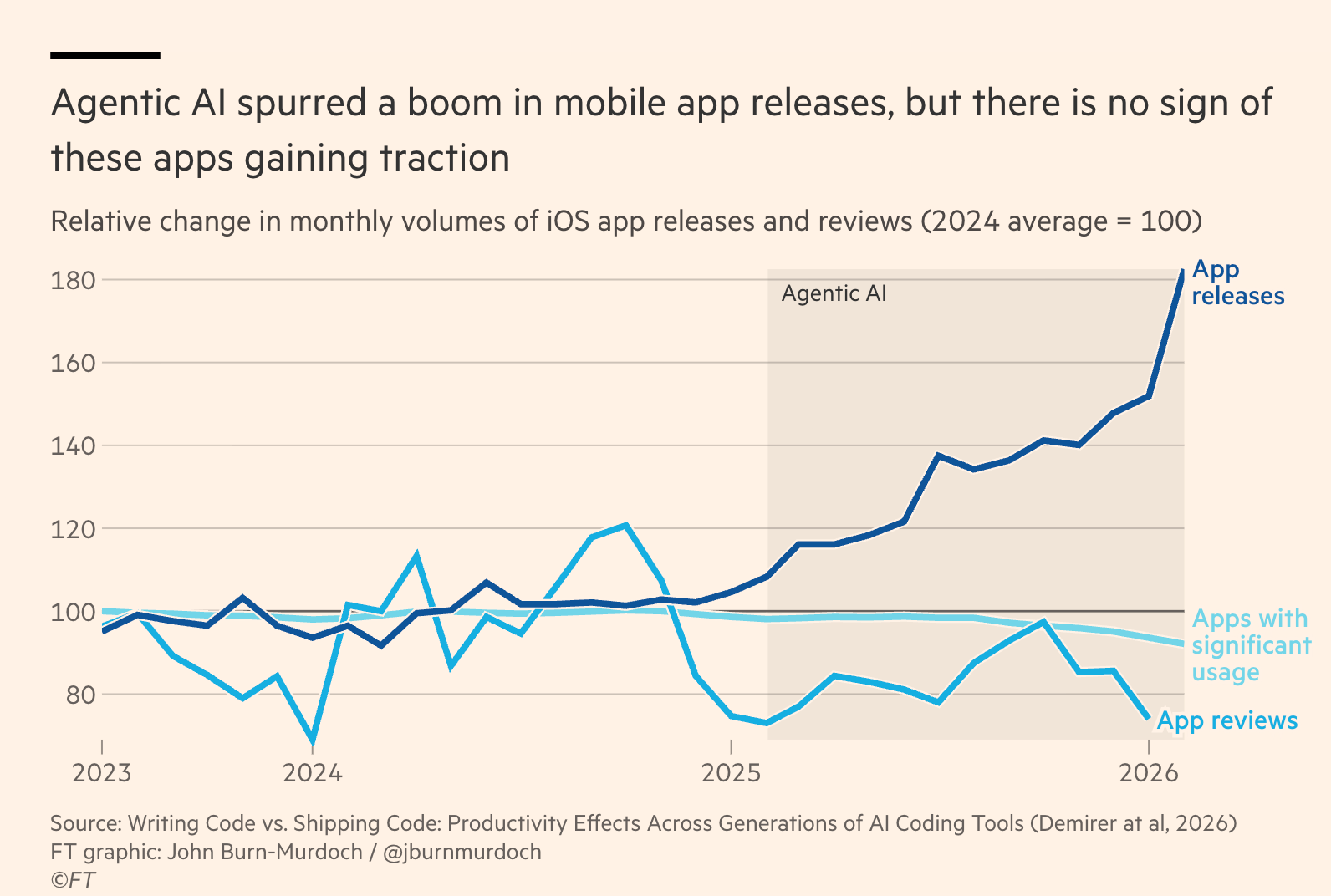 作者认为,生成式人工智能行业是一个建立在炒作、欺诈和不可持续的算力承诺之上的经济泡沫,在商业上并不可行。OpenAI 和 Anthropic 等公司正在烧掉数十亿美元,它们需要极大规模的未来收入增长来证明由云巨头和英伟达主导的万亿美元基础设施建设是合理的,而作者认为这种增长是不可能的。
文章指出,企业正日益意识到人工智能工具的投资回报率较低,这些工具往往以高昂的成本产出“劣质软件”(slopware),且缺乏可衡量的生产力提升。随着企业转向不可预测的基于 Token 的定价模式,许多公司正遭遇“账单冲击”并限制使用。作者认为,整个生态系统是一个循环的金融陷阱:人工智能实验室需要持续的资金来支付给云巨头,而云巨头反过来又对实验室进行再投资,所有这些都是为了维持英伟达估值的增长假象。
作者否认了有关其仅仅是“末日论者”或受空头头寸驱动的指控,并将自己的批评定性为对该行业及其受虐待员工的维护,以抵制那些“商业白痴”式的领导层。文章最后预告了一篇即将发表的深度调查,承诺将揭露足以刺破人工智能泡沫的信息。
作者认为,生成式人工智能行业是一个建立在炒作、欺诈和不可持续的算力承诺之上的经济泡沫,在商业上并不可行。OpenAI 和 Anthropic 等公司正在烧掉数十亿美元,它们需要极大规模的未来收入增长来证明由云巨头和英伟达主导的万亿美元基础设施建设是合理的,而作者认为这种增长是不可能的。
文章指出,企业正日益意识到人工智能工具的投资回报率较低,这些工具往往以高昂的成本产出“劣质软件”(slopware),且缺乏可衡量的生产力提升。随着企业转向不可预测的基于 Token 的定价模式,许多公司正遭遇“账单冲击”并限制使用。作者认为,整个生态系统是一个循环的金融陷阱:人工智能实验室需要持续的资金来支付给云巨头,而云巨头反过来又对实验室进行再投资,所有这些都是为了维持英伟达估值的增长假象。
作者否认了有关其仅仅是“末日论者”或受空头头寸驱动的指控,并将自己的批评定性为对该行业及其受虐待员工的维护,以抵制那些“商业白痴”式的领导层。文章最后预告了一篇即将发表的深度调查,承诺将揭露足以刺破人工智能泡沫的信息。
这篇 Hacker News 帖子讨论了 Ed Zitron 最近的一篇文章,他认为人工智能行业正在放缓并走向崩溃。
评论者们意见分歧严重。文章的支持者认为,Zitron 正确指出了一个重大的财务风险:维持人工智能模型所需的巨额基础设施成本,而这些模型目前缺乏明确的盈利途径。他们还指出了来自低成本中国模型的竞争日益加剧,以及本地离线人工智能使该技术商品化的潜力。
相反,许多用户将 Zitron 斥为“AI 末日论者”,认为他那种悲观的风格更多是基于个人形象而非客观分析。批评者强调了他过去预测不准确的历史,并指出他的作品对于那些无法适应快速技术变革的人来说是一个回声室。他们将他的论点与过去针对优步(Uber)等公司的“末日”言论进行了比较,而那些公司最终都实现了盈利。
总的来说,这场对话反映了一种更广泛的矛盾:尽管一些用户赞赏人工智能带来的不可否认的生产力提升,但另一些人对当前的商业模式是否具备财务可持续性,或者该行业的炒作是否已与其长期的实际价值脱节,仍持深度怀疑态度。
 本指南旨在提供 **Dune** 的实用入门介绍,它是 OCaml 生态系统中不可或缺的构建系统。本指南专为初学者设计,介绍了如何高效地组织、构建、测试及记录 OCaml 项目。
**核心组件:**
* **`dune-project`**:项目的根元数据文件,用于定义 Opam 等工具所需的配置和依赖项。
* **`dune` 文件**:位于子目录中的构建说明文件,用于定义“节”(stanzas)——即配置库、可执行文件和测试的声明性模块。
* **核心命令**:
* `dune build @all`:编译整个项目。
* `dune exec`:运行已编译的可执行文件。
* `dune build @doc`:通过 `odoc` 生成 API 文档。
* `dune runtest`:执行测试,包括用于验证命令行输出的“cram”测试。
**入门指南:**
虽然手动配置有助于开发者理解 Dune 的底层运作方式,但推荐使用 `dune init` 命令来创建新项目。该命令会自动生成包含所有必要文件的标准目录结构,让开发者能立即专注于编写代码。通过掌握这些基础知识以及 Dune 与 Opam 之间的交互,开发者可以在项目规模扩大时可靠地管理其 OCaml 项目。
本指南旨在提供 **Dune** 的实用入门介绍,它是 OCaml 生态系统中不可或缺的构建系统。本指南专为初学者设计,介绍了如何高效地组织、构建、测试及记录 OCaml 项目。
**核心组件:**
* **`dune-project`**:项目的根元数据文件,用于定义 Opam 等工具所需的配置和依赖项。
* **`dune` 文件**:位于子目录中的构建说明文件,用于定义“节”(stanzas)——即配置库、可执行文件和测试的声明性模块。
* **核心命令**:
* `dune build @all`:编译整个项目。
* `dune exec`:运行已编译的可执行文件。
* `dune build @doc`:通过 `odoc` 生成 API 文档。
* `dune runtest`:执行测试,包括用于验证命令行输出的“cram”测试。
**入门指南:**
虽然手动配置有助于开发者理解 Dune 的底层运作方式,但推荐使用 `dune init` 命令来创建新项目。该命令会自动生成包含所有必要文件的标准目录结构,让开发者能立即专注于编写代码。通过掌握这些基础知识以及 Dune 与 Opam 之间的交互,开发者可以在项目规模扩大时可靠地管理其 OCaml 项目。