**Music Decoy** 可以防止系统“音乐”应用在按下播放键、使用蓝牙耳机或结束通话时自动启动。macOS 的 `rcd` 守护进程会在没有其他媒体活动时,一旦收到播放指令便会触发“音乐”应用;而 Music Decoy 会拦截这一进程。 **自定义:** 自 v1.1 版本起,你可以配置该应用以启动指定的播放器(如 Spotify)来替代“音乐”。请在终端(Terminal)中运行以下命令: `defaults write com.lowtechguys.MusicDecoy mediaAppPath /Applications/Spotify.app` 如需重置,请使用: `defaults delete com.lowtechguys.MusicDecoy mediaAppPath` **应用管理:** 由于 Music Decoy 在后台运行且没有 Dock 图标或菜单栏图标,你必须通过“活动监视器”或在终端中运行 `killall 'Music Decoy'` 来关闭它。 **为什么选择它?** 与禁用 `rcd` 守护进程(会导致媒体快捷键完全失效)或使用 *noTunes* 等工具(在“音乐”应用启动后将其杀掉)不同,Music Decoy 会主动将播放指令引导至你偏好的应用程序,从而提供更流畅、更节省资源的使用体验。
每日HackerNews RSS
Hacker News 上的这篇讨论探讨了一种防止 Apple Music 在 macOS 上自动启动的巧妙解决方案,该问题通常由意外触碰耳机或键盘上的“播放”键触发。
文中提到的方案“Music Decoy”是一个轻量级实用程序,它通过模拟与官方 Music 应用相同的 bundle identifier(包标识符)来运行进程,从而产生冲突,阻止真实应用启动。用户称赞这是一种优雅且低代码的工程方案,与那种通过循环强制杀死进程的暴力脚本形成了鲜明对比。
讨论凸显了用户对苹果“排斥用户”设计的普遍不满,特别是无法卸载 Apple Music 或将媒体键重映射到 Spotify 或 VLC 等首选替代应用。许多贡献者认为这种强制集成是一种“服务加售”策略。虽然一些用户提到了 *noTunes* 等长期存在的替代方案,但也有人表达了通过“氛围编码”(vibe code)自行开发工具以夺回本地媒体库控制权的强烈愿望。这些对话反映出一种更广泛的观点:苹果已从提供以用户为中心的优质操作系统,转向优先考虑服务订阅和激进的生态锁定的模式。
此页面为 2026 年 6 月 8 日举办的苹果主题演讲官方活动门户。页面确认直播已结束,演示视频回放将很快发布。页面提供了观看美国手语(ASL)及非手语版本活动的链接,并包含在各类苹果及非苹果设备上实现最佳观看效果的技术要求。此外,该页面也作为 Apple.com 的综合网站地图,提供产品类别(Mac、iPhone、Vision 等)、服务(Apple Music、TV+、Wallet)、支持资源、商务与教育门户,以及有关苹果价值观和投资者关系的企业信息等详尽的导航菜单。
抱歉。
 研究人员日益担忧全球 50 岁以下成年人癌症发病率上升的问题。虽然专家们提出了各种潜在原因,包括超加工食品、肥胖和农用化学品,但目前仍未找到明确的解释。
数据表明,这并非单一现象,而是几种截然不同的趋势。部分增长与临床定义的改变和检测方法的改进有关,例如胰腺癌。然而,其他癌症(尤其是结直肠癌、子宫癌和肝癌)的发病率确实出现了激增,尤其是在较年轻的“出生队列”中。
专家警告称,随着这一群体年龄增长,这种上升趋势可能预示着一场更广泛的公共卫生危机。尽管肥胖是多种癌症的已知风险因素,但临床医生指出,许多年轻患者身体健康,并不符合传统的风险特征。因此,研究人员正将重点转向识别可能对年轻一代产生独特影响的新型环境暴露和生物触发因素。了解这些因素至关重要,因为今天早发的诊断可能预示着这一代人在步入中老年时,癌症负担将大幅增加。
研究人员日益担忧全球 50 岁以下成年人癌症发病率上升的问题。虽然专家们提出了各种潜在原因,包括超加工食品、肥胖和农用化学品,但目前仍未找到明确的解释。
数据表明,这并非单一现象,而是几种截然不同的趋势。部分增长与临床定义的改变和检测方法的改进有关,例如胰腺癌。然而,其他癌症(尤其是结直肠癌、子宫癌和肝癌)的发病率确实出现了激增,尤其是在较年轻的“出生队列”中。
专家警告称,随着这一群体年龄增长,这种上升趋势可能预示着一场更广泛的公共卫生危机。尽管肥胖是多种癌症的已知风险因素,但临床医生指出,许多年轻患者身体健康,并不符合传统的风险特征。因此,研究人员正将重点转向识别可能对年轻一代产生独特影响的新型环境暴露和生物触发因素。了解这些因素至关重要,因为今天早发的诊断可能预示着这一代人在步入中老年时,癌症负担将大幅增加。
这篇 Hacker News 讨论探讨了 50 岁以下人群癌症发病率上升的现象,专家认为这一趋势十分复杂,且很可能是多种因素共同作用的结果。
参与者提出了诸多理论,反映出目前对于主要成因尚未达成共识。主要的担忧领域包括:
* **饮食与代谢:** 超加工食品、肥胖和胰岛素抵抗的增加是关注焦点。一些人认为,现代饮食中膳食纤维摄入不足和营养匮乏是重要原因。
* **环境因素:** 许多评论者指向了普遍存在的毒素,包括 PFAS(“永久性化学物质”)、微塑料、杀虫剂、除草剂和室内空气污染。
* **生活方式的改变:** 现代生活中的诸多变化,如长期的心理压力、睡眠不足和久坐行为,常被认为是导致全身性炎症的潜在因素。
* **传染性疾病:** 一些用户指出,HPV(尤其是其在结直肠癌和口咽癌发病率上升中的作用)是一个关键因素。
许多参与者对缺乏明确答案表示沮丧,而另一些人则告诫不要陷入“单一成因”的思维误区,并指出癌症是一种多因素疾病。这场辩论突显了公共卫生数据、个人观察以及对食品和制药行业企业资助研究的怀疑态度之间的张力。
 作者认为,生成式人工智能行业是一个建立在炒作、欺诈和不可持续的算力承诺之上的经济泡沫,在商业上并不可行。OpenAI 和 Anthropic 等公司正在烧掉数十亿美元,它们需要极大规模的未来收入增长来证明由云巨头和英伟达主导的万亿美元基础设施建设是合理的,而作者认为这种增长是不可能的。
文章指出,企业正日益意识到人工智能工具的投资回报率较低,这些工具往往以高昂的成本产出“劣质软件”(slopware),且缺乏可衡量的生产力提升。随着企业转向不可预测的基于 Token 的定价模式,许多公司正遭遇“账单冲击”并限制使用。作者认为,整个生态系统是一个循环的金融陷阱:人工智能实验室需要持续的资金来支付给云巨头,而云巨头反过来又对实验室进行再投资,所有这些都是为了维持英伟达估值的增长假象。
作者否认了有关其仅仅是“末日论者”或受空头头寸驱动的指控,并将自己的批评定性为对该行业及其受虐待员工的维护,以抵制那些“商业白痴”式的领导层。文章最后预告了一篇即将发表的深度调查,承诺将揭露足以刺破人工智能泡沫的信息。
作者认为,生成式人工智能行业是一个建立在炒作、欺诈和不可持续的算力承诺之上的经济泡沫,在商业上并不可行。OpenAI 和 Anthropic 等公司正在烧掉数十亿美元,它们需要极大规模的未来收入增长来证明由云巨头和英伟达主导的万亿美元基础设施建设是合理的,而作者认为这种增长是不可能的。
文章指出,企业正日益意识到人工智能工具的投资回报率较低,这些工具往往以高昂的成本产出“劣质软件”(slopware),且缺乏可衡量的生产力提升。随着企业转向不可预测的基于 Token 的定价模式,许多公司正遭遇“账单冲击”并限制使用。作者认为,整个生态系统是一个循环的金融陷阱:人工智能实验室需要持续的资金来支付给云巨头,而云巨头反过来又对实验室进行再投资,所有这些都是为了维持英伟达估值的增长假象。
作者否认了有关其仅仅是“末日论者”或受空头头寸驱动的指控,并将自己的批评定性为对该行业及其受虐待员工的维护,以抵制那些“商业白痴”式的领导层。文章最后预告了一篇即将发表的深度调查,承诺将揭露足以刺破人工智能泡沫的信息。
这篇 Hacker News 帖子讨论了 Ed Zitron 最近的一篇文章,他认为人工智能行业正在放缓并走向崩溃。
评论者们意见分歧严重。文章的支持者认为,Zitron 正确指出了一个重大的财务风险:维持人工智能模型所需的巨额基础设施成本,而这些模型目前缺乏明确的盈利途径。他们还指出了来自低成本中国模型的竞争日益加剧,以及本地离线人工智能使该技术商品化的潜力。
相反,许多用户将 Zitron 斥为“AI 末日论者”,认为他那种悲观的风格更多是基于个人形象而非客观分析。批评者强调了他过去预测不准确的历史,并指出他的作品对于那些无法适应快速技术变革的人来说是一个回声室。他们将他的论点与过去针对优步(Uber)等公司的“末日”言论进行了比较,而那些公司最终都实现了盈利。
总的来说,这场对话反映了一种更广泛的矛盾:尽管一些用户赞赏人工智能带来的不可否认的生产力提升,但另一些人对当前的商业模式是否具备财务可持续性,或者该行业的炒作是否已与其长期的实际价值脱节,仍持深度怀疑态度。
 本指南旨在提供 **Dune** 的实用入门介绍,它是 OCaml 生态系统中不可或缺的构建系统。本指南专为初学者设计,介绍了如何高效地组织、构建、测试及记录 OCaml 项目。
**核心组件:**
* **`dune-project`**:项目的根元数据文件,用于定义 Opam 等工具所需的配置和依赖项。
* **`dune` 文件**:位于子目录中的构建说明文件,用于定义“节”(stanzas)——即配置库、可执行文件和测试的声明性模块。
* **核心命令**:
* `dune build @all`:编译整个项目。
* `dune exec`:运行已编译的可执行文件。
* `dune build @doc`:通过 `odoc` 生成 API 文档。
* `dune runtest`:执行测试,包括用于验证命令行输出的“cram”测试。
**入门指南:**
虽然手动配置有助于开发者理解 Dune 的底层运作方式,但推荐使用 `dune init` 命令来创建新项目。该命令会自动生成包含所有必要文件的标准目录结构,让开发者能立即专注于编写代码。通过掌握这些基础知识以及 Dune 与 Opam 之间的交互,开发者可以在项目规模扩大时可靠地管理其 OCaml 项目。
本指南旨在提供 **Dune** 的实用入门介绍,它是 OCaml 生态系统中不可或缺的构建系统。本指南专为初学者设计,介绍了如何高效地组织、构建、测试及记录 OCaml 项目。
**核心组件:**
* **`dune-project`**:项目的根元数据文件,用于定义 Opam 等工具所需的配置和依赖项。
* **`dune` 文件**:位于子目录中的构建说明文件,用于定义“节”(stanzas)——即配置库、可执行文件和测试的声明性模块。
* **核心命令**:
* `dune build @all`:编译整个项目。
* `dune exec`:运行已编译的可执行文件。
* `dune build @doc`:通过 `odoc` 生成 API 文档。
* `dune runtest`:执行测试,包括用于验证命令行输出的“cram”测试。
**入门指南:**
虽然手动配置有助于开发者理解 Dune 的底层运作方式,但推荐使用 `dune init` 命令来创建新项目。该命令会自动生成包含所有必要文件的标准目录结构,让开发者能立即专注于编写代码。通过掌握这些基础知识以及 Dune 与 Opam 之间的交互,开发者可以在项目规模扩大时可靠地管理其 OCaml 项目。
 “Souls Only” 是一个将字体作为解密层的工艺项目。与字符和字形一一对应的标准排版不同,该项目将两者解耦:存储的字节显示为随机噪点,而字体则充当渲染可读文本的密钥。
该系统采用同音替换法,将每个字符编码为四个 ASCII 符号,并通过字体的 GSUB 规则将其合并为平铺的半字形。由于映射存在于字体内部(通过 `cmap` 和 `GSUB`),标准复制粘贴操作或数据抓取工具只能获取无意义的乱码。
该项目包含一款静态字体和一款具备 “REVL”(显示)轴的可变字体(VF)。在默认状态下,字形扭曲到无法辨认;只有在特定轴值下,它们才会组合成可读文本。该项目旨在表达对数字隐私的关注,而非作为高安全性加密手段,因此如果遍历 “显示” 轴,仍易受到自动化 OCR 的破解。项目提供了键盘固件集成、自定义编码及网页实现的工具,所有资产均采用 SIL Open Font License 1.1 协议授权。
“Souls Only” 是一个将字体作为解密层的工艺项目。与字符和字形一一对应的标准排版不同,该项目将两者解耦:存储的字节显示为随机噪点,而字体则充当渲染可读文本的密钥。
该系统采用同音替换法,将每个字符编码为四个 ASCII 符号,并通过字体的 GSUB 规则将其合并为平铺的半字形。由于映射存在于字体内部(通过 `cmap` 和 `GSUB`),标准复制粘贴操作或数据抓取工具只能获取无意义的乱码。
该项目包含一款静态字体和一款具备 “REVL”(显示)轴的可变字体(VF)。在默认状态下,字形扭曲到无法辨认;只有在特定轴值下,它们才会组合成可读文本。该项目旨在表达对数字隐私的关注,而非作为高安全性加密手段,因此如果遍历 “显示” 轴,仍易受到自动化 OCR 的破解。项目提供了键盘固件集成、自定义编码及网页实现的工具,所有资产均采用 SIL Open Font License 1.1 协议授权。
抱歉。
1999年,德克萨斯州泰勒市的一个农户以10美元的象征性价格,将87英亩土地转让给该市,并明确要求将其作为公共公园进行维护。几十年来,这片土地一直是帕梅拉·格里芬(Pamela Griffin)等当地家庭的重要社区活动空间,几代人都在此享受休闲时光。 然而,2025年,泰勒市政府绕过最初的协议,以1000万美元的价格将该地块出售给了开发商Blueprint公司。这片曾经旨在供公众享用的土地,如今被规划为一个占地13.5万平方英尺的数据中心。该项目将把工业基础设施置于变电站和铁轨之间,距离长期居住的民宅仅500英尺。此举引发了当地居民的担忧,他们对市政府将企业利益置于旨在造福社区的长期土地使用协议之上的做法表示不满。
这场争议涉及一块 87 英亩的土地。该土地最初由克伦威尔(Cromwell)家族捐赠给一家非营利组织,作为公共公园进行信托管理。近期,得克萨斯州泰勒市(Taylor)将该土地的一部分出售给一家私人开发商,用于建设一个价值 10 亿美元的数据中心项目,并提供了巨额税收返还。
当地居民起诉以阻止该开发项目,理由是原始契约中存在限制条款,但法官以缺乏诉讼资格为由驳回了此案。这一情况引发了关于以下议题的激烈讨论:
* **财产权与公共利益:** 批评者认为,城市不应被允许无视契约限制或“死者之手”(指逝者遗愿)的规定;而另一些人则主张,土地使用限制应当设有期限,以防止过去的所有者无限期地控制未来发展。
* **问责制:** 许多评论者对政府在为企业项目推翻社区意愿时所表现出的问责缺失表示不满。
* **诉讼资格:** 该案件凸显了挑战政府土地使用决策的难度,因为无论个人对其财产价值或社区环境的受损感受如何,往往都缺乏起诉市政行为的法律资格。
该讨论帖建议,未来的土地捐赠应通过私人保护信托机构进行处理,而非交给政府实体。
已拦截。您的请求因网络策略被拦截。请尝试在此处登录或创建帐户以恢复浏览。如果您正在运行脚本或应用程序,请在此处使用您的开发者凭据进行注册或登录。此外,请确保您的 User-Agent 不为空,并具有唯一性和描述性,然后重试。如果您提供了备用的 User-Agent 字符串,请尝试改回默认值,因为有时这会导致拦截。您可以在此处阅读 Reddit 的服务条款。如果您认为我们错误地拦截了您,或者您想讨论获取所需数据的更简便方法,请在此处提交工单。联系我们时,请提供您的 Reddit 帐户以及以下代码:019ea7f9-f6ff-770e-97e3-cdcf65c9b271
对不起。
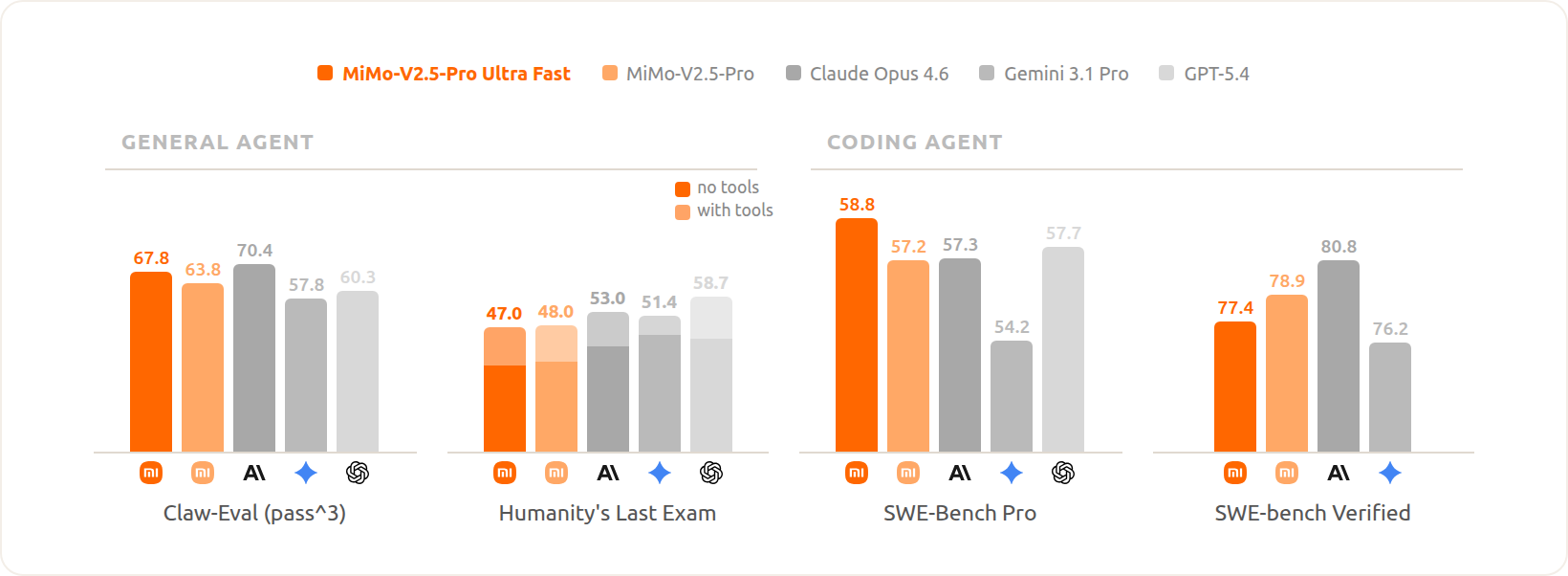 小米与 TileRT 共同发布了 **MiMo-V2.5-Pro-UltraSpeed**,这是首个解码速度超过 1000 tokens/s 的万亿参数人工智能模型。这一性能突破将 AI 从高延迟工具转变为人类认知的实时、无缝延伸,能够实现快速并行推理、高效率编程,以及在医疗和金融等时间敏感领域进行即时决策。
这一成就得益于在商用 GPU 上而非专用硬件上实现的“极限模型-系统协同设计”。主要创新包括:
* **选择性 FP4 量化**:对混合专家模型(MoE)的专家层应用 FP4 精度,同时在其他部分保持原始精度,在不牺牲推理质量的前提下减少带宽瓶颈。
* **DFlash 推测解码**:一种块级掩码并行预测方法,最大限度地减少了串行限制,使模型能够同时验证多个 Token。
* **TileRT 基础设施**:一种全新的执行模型,以持久的、微秒级的软硬件融合取代了传统的算子处理方式,确保了连续的数据流和最高的计算利用率。
该模型目前通过限时申请制 API 试用(2026 年 6 月 9 日至 23 日)开放,价格为原来的 3 倍,性能提升达 10 倍。此外,该检查点(Checkpoint)已在 HuggingFace 上开源,以鼓励社区创新。
小米与 TileRT 共同发布了 **MiMo-V2.5-Pro-UltraSpeed**,这是首个解码速度超过 1000 tokens/s 的万亿参数人工智能模型。这一性能突破将 AI 从高延迟工具转变为人类认知的实时、无缝延伸,能够实现快速并行推理、高效率编程,以及在医疗和金融等时间敏感领域进行即时决策。
这一成就得益于在商用 GPU 上而非专用硬件上实现的“极限模型-系统协同设计”。主要创新包括:
* **选择性 FP4 量化**:对混合专家模型(MoE)的专家层应用 FP4 精度,同时在其他部分保持原始精度,在不牺牲推理质量的前提下减少带宽瓶颈。
* **DFlash 推测解码**:一种块级掩码并行预测方法,最大限度地减少了串行限制,使模型能够同时验证多个 Token。
* **TileRT 基础设施**:一种全新的执行模型,以持久的、微秒级的软硬件融合取代了传统的算子处理方式,确保了连续的数据流和最高的计算利用率。
该模型目前通过限时申请制 API 试用(2026 年 6 月 9 日至 23 日)开放,价格为原来的 3 倍,性能提升达 10 倍。此外,该检查点(Checkpoint)已在 HuggingFace 上开源,以鼓励社区创新。
本帖讨论了超高速AI推理技术的兴起,特别介绍了小米 **MiMo-v2.5-Pro**,其推理速度已达到每秒 1,000 个 Token (TPS)。
**核心议题包括:**
* **工作流的转变:** 用户反馈称,近乎瞬时的 Token 生成将 AI 从“对话即等待”的工具转变为实时响应的伙伴。开发者指出,这使得“代理式”工作流成为可能,即 AI 可以实时迭代代码修复,有效消除了等待 Claude 或 GPT 等较慢模型时产生的切换任务疲劳。
* **性能与能力的权衡:** 尽管 DeepSeek 和小米 MiMo 等模型以速度和成本效益著称,但一些用户认为它们缺乏大型前沿模型所具备的“常识”和稳健的指令遵循能力,往往需要更具体的提示词才能避免在回答中出现“随意填补”导致的错误。
* **软件开发的未来:** 关于“劣质软件”的争议:批评者担心低延迟、大规模生产的代码会导致低质量、未经测试的软件泛滥。相反,支持者认为,快速迭代能促进更好的测试、重构和实验,而这些工作在以往往往因过于繁琐而难以实现。
* **地缘政治与经济背景:** 讨论涉及中国供应商(正迅速优化硬件效率)与西方实验室之间的竞争格局,并关注了审查机制、模型可用性以及当前 AI 定价模式的可持续性等问题。
请启用 JavaScript 并关闭广告拦截器
Bending Spoons 是一家以收购 AOL、Vimeo、Evernote 和 Komoot 等传统软件及数字媒体平台而闻名的意大利科技公司,目前已提交纳斯达克首次公开募股(IPO)申请。
该公司的商业模式经常受到用户和行业观察人士的批评,他们将其戏称为科技产品的“养老院”。批评者指出,该公司在收购后往往采取一致的策略:大规模裁员、激进提价,并专注于通过“平台腐烂”(enshittification)手段,从忠实用户群中榨取剩余收益。尽管管理层声称要重振停滞的软件,但许多长期用户反馈,软件界面体验下降、功能缩水,且比起实质性改进,公司更偏向于开发一些表面功夫的功能。
即将进行的 IPO 在 Hacker News 上引发了热议,许多人对该公司的高估值及其业务的可持续性表示怀疑。批评者认为,Bending Spoons 的运作方式如同 80 年代的杠杆收购公司,以牺牲产品质量和员工稳定性为代价,优先考虑股东的短期经济利益。尽管营收增长数据表现强劲,但许多科技专业人士仍对其长期前景持谨慎态度,认为这种“鲨鱼”模式必须不断收购新资产,以掩盖现有产品组合的衰退。