在1960年发表的开创性论文中,J.C.R. 利克莱德(J.C.R. Licklider)提出了“人机共生”的概念,这是一种变革性的伙伴关系,旨在实现人类与计算机之间密切的实时协作。利克莱德并不主张用自动化取代人类,也不仅仅将计算机视为执行预设任务的工具,他所设想的系统是由计算机处理技术工作中琐碎且程序化的部分,从而将人类解放出来,专注于构思、目标设定和决策。 利克莱德认为,人类与计算机拥有互补的优势:人类具备灵活性和直觉,而计算机拥有速度和精度。为了弥合当前两者交互中的差距,他确定了几个关键需求,包括分时系统的进步、先进的内存组织(如“字典树”结构),以及交互式显示屏和语音识别等直观的输入/输出设备。 通过整合这些技术,利克莱德预见了一个未来:人类大脑与计算机将作为一个统一且高效的智能主体共同运作。他预计在人工智能成熟之前,将会有一个过渡时期,届时这种共生关系将推动人类历史上最具创造力和生产力的时代,使我们能够解决目前单靠任何一方都无法处理的复杂问题。
每日HackerNews RSS

在一个充满地理、社会和政治差异的世界里,“同一个世界旗帜”(One World Flag)提醒我们:我们都生活在同一个星球上,拥有共同的未来。旗帜通常象征着国家、地区或群体,即代表着差异。而“同一个世界旗帜”向人类传递了这样一个信息:团结我们的因素远多于分裂我们的因素。这面旗帜并不打算取代其他旗帜,而是为了表明在差异之外,还存在着统一。“同一个世界旗帜”的中心是一个蓝色球体,象征着我们共同的家园——蓝色星球。旗帜的背景由透明材料制成,这意味着它能随时适应周围的环境。
最近一篇出现在 Hacker News 上的帖子引发了用户间广泛而激烈的讨论。帖子主角是一个“世界旗”设计,其图案仅为透明背景上的一个蓝色圆点。
讨论的焦点在于这一全球标志的实用性与象征意义。批评者常将其与日本国旗作比较,指责其缺乏原创性;另一些人则讨论了在实体旗帜上使用透明材质所面临的技术挑战。评论区很快演变成了更深层次的哲学争论,涉及民族国家的优劣、世界政府的可行性,以及旗帜作为团结象征与作为分裂和战争工具的本质。
许多用户指出了现有的替代方案,例如著名的地球日旗帜或《飞出个未来》等流行文化中的虚构设计。该讨论帖最终凸显了人类在追求全球合作的理想与国家及政治身份认同所带来的现实对抗之间深层的矛盾。正如一位用户所言,这个项目完美地体现了人性:“有人制作了一面旗帜来表达团结,而我们大家聚在这里却只是为了争吵。”
本项目是一款达到生产级别的本地应用,可将剧本转化为完整的短片,并自动生成同步的视频、音频、对白、配乐和字幕。该平台充当数字制片人(Showrunner),集成了谷歌 Veo 3.1、Gemini 2.5 Pro、Nano Banana 以及 ElevenLabs Music 等前沿人工智能技术。 为确保电影级质量与叙事连贯性,系统采用了两个自动化“预言机”(Oracles)。**质量预言机(Quality Oracle)**利用一套先进的综合指标(包括 VideoScore、ViCLIP 和 ArcFace)处理自动重绘与自适应缩放;**叙事预言机(Story Oracle)**则运用 Reagan-6 架构等成熟框架来维护叙事结构。 该应用后端基于 FastAPI 构建,前端采用 Next.js PWA,可在 iOS 上提供原生级体验。其设计注重效率,制作一部 2 分钟短片的成本约为 20 美元。安装过程简便,后端需配置 Python 虚拟环境,前端使用标准 Node 包管理工具;此外,系统还提供可选支持,用于处理基于机器学习的高负荷质量监控任务。
抱歉。
德州电网发出警示:数据中心与加密货币站点未能通过电压测试 Texas grid flags risks as data centers, crypto sites fail voltage tests
24 天前
请启用 JavaScript 并关闭广告拦截器
抱歉。
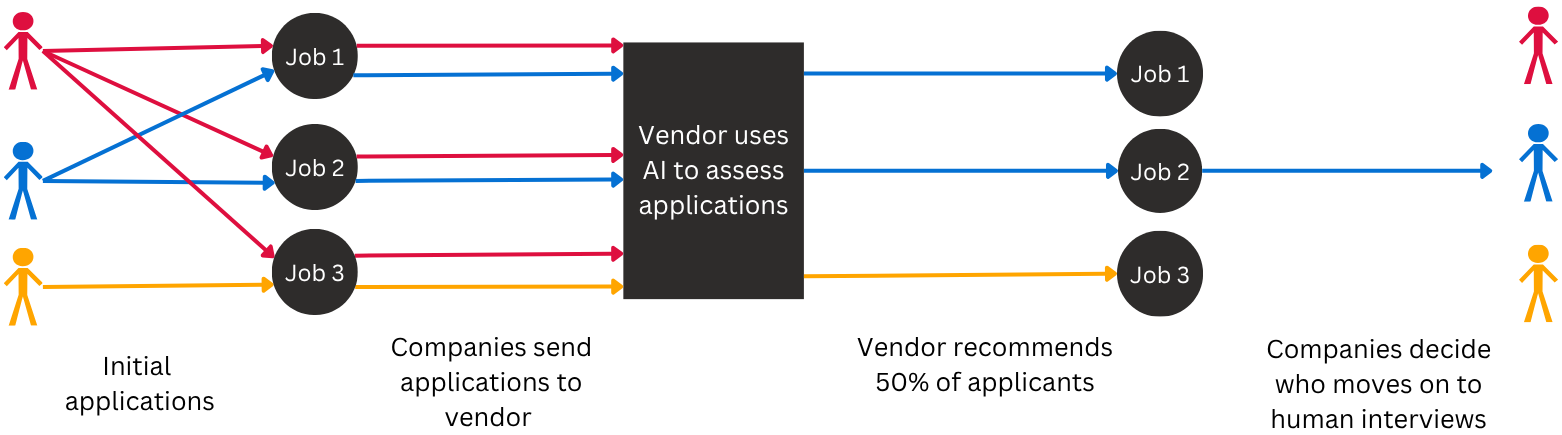 一项针对 340 万求职者的大规模研究表明,“算法单一文化”——即广泛依赖少数几家相同的 AI 招聘供应商——正在造成系统性的就业障碍。研究人员通过分析 156 家雇主的 400 万份申请发现,这些算法产生了显著的种族差异,而这种差异往往被传统的汇总数据分析所掩盖。
主要发现包括:
* **隐性负面影响:** 按照美国《民权法案》第七章的要求,在对单个职位进行分析时,可以发现明显的歧视模式,尤其是针对黑人和亚裔申请人。
* **系统性拒绝:** 对单一供应商的依赖导致了“系统性拒绝”,即申请人在多个职位中被不成比例地拒绝。这种结果的高度同质化远超统计学常态,表明中心化的 AI 模型限制了就业机会。
* **研究壁垒:** 数据的不透明性阻碍了对这些高风险系统的独立监管。
作者认为,当前的法规尚显不足。他们建议决策者强制要求进行职位层面的负面影响审计,监督算法依赖风险,并改善独立研究人员的数据访问权限,以确保自动化招聘过程中的问责制。
一项针对 340 万求职者的大规模研究表明,“算法单一文化”——即广泛依赖少数几家相同的 AI 招聘供应商——正在造成系统性的就业障碍。研究人员通过分析 156 家雇主的 400 万份申请发现,这些算法产生了显著的种族差异,而这种差异往往被传统的汇总数据分析所掩盖。
主要发现包括:
* **隐性负面影响:** 按照美国《民权法案》第七章的要求,在对单个职位进行分析时,可以发现明显的歧视模式,尤其是针对黑人和亚裔申请人。
* **系统性拒绝:** 对单一供应商的依赖导致了“系统性拒绝”,即申请人在多个职位中被不成比例地拒绝。这种结果的高度同质化远超统计学常态,表明中心化的 AI 模型限制了就业机会。
* **研究壁垒:** 数据的不透明性阻碍了对这些高风险系统的独立监管。
作者认为,当前的法规尚显不足。他们建议决策者强制要求进行职位层面的负面影响审计,监督算法依赖风险,并改善独立研究人员的数据访问权限,以确保自动化招聘过程中的问责制。
对不起。
请启用 JavaScript 和 Cookie 以继续。
抱歉。
 软件系统很少在一开始就变得复杂而混乱。它们是随着时间推移,通过一次次增量变更而逐渐演变成这样的。起初简单的功能(如用户注册或订单处理),不可避免地会演变成一系列相互关联的任务,涉及队列、后台作业、第三方集成和条件逻辑。
虽然这些单独的改动通常是合理的,但它们最终会累积成“隐藏的工作流”。当这些流程埋没在分散的代码中时,系统将变得难以维护。团队会因此陷入困境,因为改动往往伴随着不可预见的风险,调试时需要拼凑多个服务的日志,而组织内部的经验往往取代了清晰的文档。这削弱了开发者的信心,并使系统显得脆弱不堪。
解决之道并非消除复杂性,而是使其“可见”。通过承认系统正在运行编排流程,你可以将这些协调逻辑从零散的处理程序中剥离出来,转入集中且明确的工作流中。像 Unmeshed 这类工具允许团队在一个地方定义这些序列,从而更易于监控、调试和演进。归根结底,工作流是增长的自然产物;我们的目标是不再将其隐藏在“粘合代码”中,而是将其作为架构中的核心要素来管理。
软件系统很少在一开始就变得复杂而混乱。它们是随着时间推移,通过一次次增量变更而逐渐演变成这样的。起初简单的功能(如用户注册或订单处理),不可避免地会演变成一系列相互关联的任务,涉及队列、后台作业、第三方集成和条件逻辑。
虽然这些单独的改动通常是合理的,但它们最终会累积成“隐藏的工作流”。当这些流程埋没在分散的代码中时,系统将变得难以维护。团队会因此陷入困境,因为改动往往伴随着不可预见的风险,调试时需要拼凑多个服务的日志,而组织内部的经验往往取代了清晰的文档。这削弱了开发者的信心,并使系统显得脆弱不堪。
解决之道并非消除复杂性,而是使其“可见”。通过承认系统正在运行编排流程,你可以将这些协调逻辑从零散的处理程序中剥离出来,转入集中且明确的工作流中。像 Unmeshed 这类工具允许团队在一个地方定义这些序列,从而更易于监控、调试和演进。归根结底,工作流是增长的自然产物;我们的目标是不再将其隐藏在“粘合代码”中,而是将其作为架构中的核心要素来管理。
请提供您需要翻译的内容。
最近一篇关于 DeepSeek V4 Pro 在精度上超越 GPT-5.5 Pro 的 Hacker News 文章引发了关于 AI 生成内容及大语言模型基准测试有效性的激烈辩论。
批评者认为该文章是“AI 生成的标题党”,并指出其仅凭四项实验的方法论非常薄弱、构建粗糙,缺乏科学比较所需的严谨性。许多用户质疑该测试使用 AI 模型(Grok)作为裁判的做法,以及缺乏多轮测试以排除模型非确定性行为的影响。
相反,支持者则强调,DeepSeek V4 Pro 及类似模型代表了向高性价比、高性能替代方案的必要转型,挑战了西方“前沿”模型的地位。用户指出,尽管 GPT-5.5 可能在“宏观”推理或处理复杂、模糊的任务上仍具优势,但 DeepSeek 极高的成本效益、出色的 Token 缓存能力,以及在配合结构化代码框架使用时的有效性,使其成为实际开发中的“游戏规则改变者”。
归根结底,这场讨论突显了日益加剧的分歧:一部分人认为 AI 基准测试已沦为充斥着垃圾信息的无效劳动,而另一部分人则将廉价、开源权重模型的崛起视为对少数高价闭源公司垄断地位的必要冲击。
周一凌晨,菲律宾南部城市桑托斯将军市附近发生7.8级地震,该地区随即发布了海啸预警。此次地震震源深度为10公里,造成了电力中断和建筑物结构受损,其中包括一栋四层办公楼的部分坍塌。 当局已向沿海居民发出紧急撤离令,警告菲律宾境内可能出现高达3米的海啸,印度尼西亚、马来西亚及西太平洋其他地区也可能出现较小的海啸。目前尚无人员伤亡报告,但该地区随后发生了多次强余震,其中一次震级为6.5级。 菲律宾位于太平洋“火环”地带,极易受到地震和火山活动的影响。紧急救援小组目前正在评估灾情,由于地震发生在凌晨,商业建筑内人员较少,因此减少了人员受伤的情况。目前,夏威夷没有受到海啸威胁。
抱歉。