 Spotify 正面临一个日益严峻的挑战:在线服务和人工智能代理需要从其“数据湖”的艾字节(exabyte)级数据中,进行亚秒级的“点查询”(即查找特定用户的数据)。虽然云存储延迟已大幅降低,但像 Trino 或 BigQuery 这样的标准查询引擎主要针对分析型吞吐量进行了优化,而非单行查找。
随机访问 Parquet(Random Access Parquet,简称 RAP)通过直接在现有 Parquet 文件上实现交互式查询,填补了这一空白,且无需数据冗余或专门的键值(KV)存储。
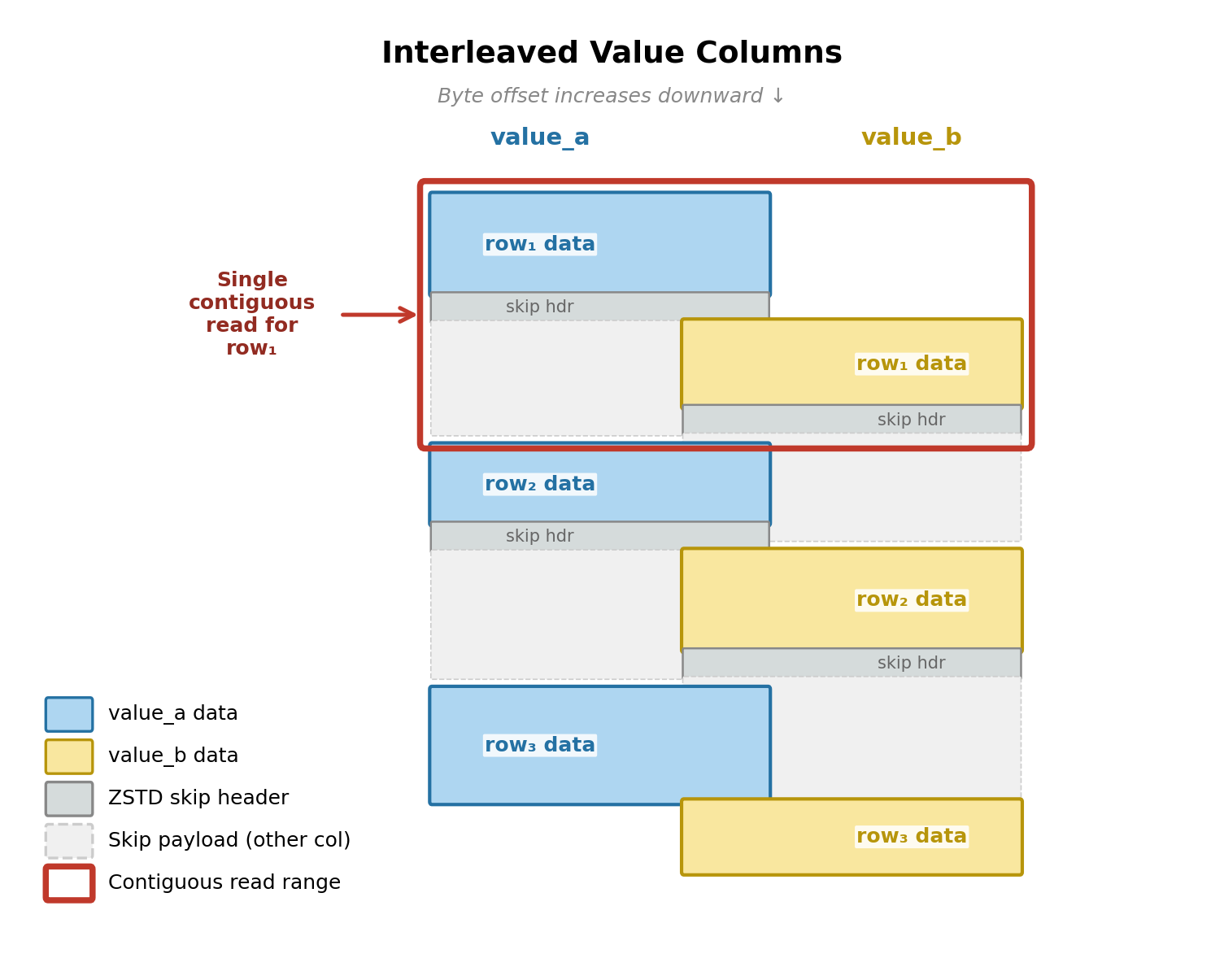
RAP 使用“外部索引”将键(如 `user_id`)直接映射到文件位置和行偏移量。这消除了标准 Parquet 文件中常见的昂贵、高延迟的扫描以及“依赖读取链”。通过优化文件布局(例如按键排序、交错列存储以及使用 ZSTD 帧重置),RAP 可以将查询简化为仅需几次千字节的并行范围读取,甚至可以通过覆盖索引完全免除存储读取。
最终,RAP 将数据湖从仅能进行批处理的系统,转变为能够提供交互式、实时 AI 上下文的系统,使企业能够以传统服务系统极低的分数成本和复杂度来查询历史数据。
Spotify 正面临一个日益严峻的挑战:在线服务和人工智能代理需要从其“数据湖”的艾字节(exabyte)级数据中,进行亚秒级的“点查询”(即查找特定用户的数据)。虽然云存储延迟已大幅降低,但像 Trino 或 BigQuery 这样的标准查询引擎主要针对分析型吞吐量进行了优化,而非单行查找。
随机访问 Parquet(Random Access Parquet,简称 RAP)通过直接在现有 Parquet 文件上实现交互式查询,填补了这一空白,且无需数据冗余或专门的键值(KV)存储。
RAP 使用“外部索引”将键(如 `user_id`)直接映射到文件位置和行偏移量。这消除了标准 Parquet 文件中常见的昂贵、高延迟的扫描以及“依赖读取链”。通过优化文件布局(例如按键排序、交错列存储以及使用 ZSTD 帧重置),RAP 可以将查询简化为仅需几次千字节的并行范围读取,甚至可以通过覆盖索引完全免除存储读取。
最终,RAP 将数据湖从仅能进行批处理的系统,转变为能够提供交互式、实时 AI 上下文的系统,使企业能够以传统服务系统极低的分数成本和复杂度来查询历史数据。
每日HackerNews RSS
 Cursor 用户对最近的一项刻意更新表示强烈不满。该更新将所有自助服务方案(包括 Teams 版)的费用追踪从美元计费方式改为仅显示 Token(令牌)用量。此前,用户可以查看每次请求、每个模型以及每日的费用详情,这对他们的预算管理、监控模型效率以及了解支出至关重要。
Cursor 代表 "kevinn" 解释称,此举是旨在简化计费并避免用户混淆“套餐内包含用量”与“按需付费”的刻意设计。尽管用户仍可在仪表板中查看总支出,但移除精细到请求层级的成本数据(甚至包括历史记录和 API 端点中的数据)引发了强烈抵制。
用户认为,仅凭 Token 数量难以进行财务规划,且透明度的降低妨碍了他们评估不同模型的性价比。许多用户呼吁提供一个切换选项以恢复美元显示方式,认为此项更改降低了工具的实用性与透明度。批评者将此举描述为“开倒车”,要求 Cursor 要么恢复成本显示字段,要么提供更稳健、透明的支出追踪方式。
Cursor 用户对最近的一项刻意更新表示强烈不满。该更新将所有自助服务方案(包括 Teams 版)的费用追踪从美元计费方式改为仅显示 Token(令牌)用量。此前,用户可以查看每次请求、每个模型以及每日的费用详情,这对他们的预算管理、监控模型效率以及了解支出至关重要。
Cursor 代表 "kevinn" 解释称,此举是旨在简化计费并避免用户混淆“套餐内包含用量”与“按需付费”的刻意设计。尽管用户仍可在仪表板中查看总支出,但移除精细到请求层级的成本数据(甚至包括历史记录和 API 端点中的数据)引发了强烈抵制。
用户认为,仅凭 Token 数量难以进行财务规划,且透明度的降低妨碍了他们评估不同模型的性价比。许多用户呼吁提供一个切换选项以恢复美元显示方式,认为此项更改降低了工具的实用性与透明度。批评者将此举描述为“开倒车”,要求 Cursor 要么恢复成本显示字段,要么提供更稳健、透明的支出追踪方式。
最近,Cursor 在其使用页面和 CSV 导出中移除了成本信息,这在 Hacker News 上引发了强烈抵制。用户认为,隐藏定价是一种具有敌意的“劣化(enshittification)”策略,旨在掩盖投资回报率并抑制用户对成本的关注。
除了定价争议之外,这场讨论还突显了“代理(agentic)”软件中的一个普遍趋势:不同编程框架在 Token 效率上存在巨大差异。用户指出,像 Claude Code 这样流行的工具往往会用过多的系统提示词和不必要的工具来“滥用”上下文窗口,导致成本激增。
工程师们正越来越多地尝试使用“极简主义”框架(例如 `smol`),这些框架依赖更精简的提示词和更少的注入工具。虽然这些轻量级代理可以显著减少 Token 消耗,但批评者警告称,它们可能会牺牲那些更复杂、“臃肿”的替代方案所具备的稳健性、编排能力和专业功能。
归根结底,这篇讨论反映出开发者日益增长的一种情绪:对 AI 辅助编程缺乏透明度感到沮丧,并转向那些能提供更强上下文管理和模型选择控制权的工具。这常常导致开发者放弃全能型 IDE,转而采用基于命令行的自定义工作流。
由于开发者兴趣转移,OpenBSD 的 `relayd(8)` 和 `httpd(8)` 的开发一度陷入停滞。作者出于对精通 C 语言的渴望,以及对“编程已被大语言模型解决”这一论调的挑战,主动承担起这些守护进程的现代化工作。 凭借实践经验和专业架构知识,作者对这些工具进行了系统性的重构。工作重点包括重构遗留的 `imsg` 代码、提升安全性、修复长期存在的错误以及增强功能。关键的安全更新包括:改用“安全”默认 TLS 密码套件、强化 HTTP 解析以防止请求走私,以及实施更严格的进程控制。 为了降低新贡献者的参与门槛,作者改进了文档,并打破了传统的仅限 CVS 的工作流,建立了易于访问的 Git 镜像(Gothub、Codeberg 和 GitHub)。这项振兴工作已经显著提升了这两个守护进程的稳定性和功能,未来还将有更多更新计划。通过拥抱 C 语言的复杂性并投身于规范的开源贡献,作者成功地焕新了这些此前面临停滞风险的关键基础设施。
Hacker News
最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
Dead Software Walking: relayd(8) 和 httpd(8) 的持续演进 (rsadowski.de)
20 分,tylerius 发布于 1 天前 | 隐藏 | 过往 | 收藏 | 1 条评论
帮助
graemep 1 天前 [–]
据我所知,OpenBSD httpd 的编写与 OpenBSD 其他项目一样,都专注于安全性?我原以为现在比以往任何时候都更需要它。relayd 也是如此。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索:
 受寻找琐事“最优解”(例如免费餐厅面包)的启发,一位软件工程师开始探寻“幂等键”(idempotency key)的起源,这是一种用于分布式系统中防止同一请求被重复处理的工具。
作者首先通过一个生动的类比阐述了这一概念:如何防止家里的狗林戈(Ringo)被不同的家庭成员重复喂食。在反驳了大型语言模型关于 Stripe 在 2011 年发明该概念的说法后,作者追溯了幂等性的演变过程,从 21 世纪初的“仅限一次 POST”(POST Once Exactly)规范和企业级传输协议,一直回溯到印加结绳记事等古老的记录方法。
将搜索范围聚焦于数字计算领域后,作者将这一谱系追溯到了施乐帕罗奥多研究中心(Xerox PARC)1984 年发表的研究论文《实现远程过程调用》(Implementing Remote Procedure Calls,作者为 Birrell 和 Nelson)。该论文描述了一种用于消除重复数据包的“调用标识符”,标志着该机制的一个基础实例。尽管作者承认要确定绝对的“首例”依然困难,但他们总结认为,对这类问题的探索凸显了人类是如何不断地重新发明解决方案,以应对分布式系统中“仅处理一次”这一持久难题的。
受寻找琐事“最优解”(例如免费餐厅面包)的启发,一位软件工程师开始探寻“幂等键”(idempotency key)的起源,这是一种用于分布式系统中防止同一请求被重复处理的工具。
作者首先通过一个生动的类比阐述了这一概念:如何防止家里的狗林戈(Ringo)被不同的家庭成员重复喂食。在反驳了大型语言模型关于 Stripe 在 2011 年发明该概念的说法后,作者追溯了幂等性的演变过程,从 21 世纪初的“仅限一次 POST”(POST Once Exactly)规范和企业级传输协议,一直回溯到印加结绳记事等古老的记录方法。
将搜索范围聚焦于数字计算领域后,作者将这一谱系追溯到了施乐帕罗奥多研究中心(Xerox PARC)1984 年发表的研究论文《实现远程过程调用》(Implementing Remote Procedure Calls,作者为 Birrell 和 Nelson)。该论文描述了一种用于消除重复数据包的“调用标识符”,标志着该机制的一个基础实例。尽管作者承认要确定绝对的“首例”依然困难,但他们总结认为,对这类问题的探索凸显了人类是如何不断地重新发明解决方案,以应对分布式系统中“仅处理一次”这一持久难题的。
这篇 Hacker News 讨论探讨了在分布式系统中实现幂等性键的复杂性与哲学方法。
参与者争论了幂等性究竟应该通过“自然”领域建模(如使用基于业务逻辑的标识符或物理占用规则)来处理,还是通过 UUID、PUT 请求和数据库级 UPSERT 等通用技术中间件来处理。一些人认为,仅依赖中间件是一种“天真”的捷径,规避了对系统底层工作流的深入理解。
讨论的很大一部分集中在现代 API 缺乏标准化语义的问题上。开发者们表示,幂等性契约往往隐藏在冗长的文档中,而非定义在如 OpenAPI 这样机器可读的规范里,这令他们感到沮丧。这种不一致性——即某些服务商仅缓存成功响应,而另一些则存储错误——为重试逻辑和中间件的实现带来了风险。
最终,该讨论强调,尽管幂等性键对于防止分布式环境中的重复效应至关重要,但其实现方式依然支离破碎,这凸显了业界四十年来在实现端到端一致性可靠性方面所面临的挑战。(讨论中还穿插了一些关于餐厅免费面包质量的幽默插曲。)
星际循环 Astro Loop
2 天前
``` CTRL 操作简单 单指操控。武器自动开火。易于上手,爱不释手。 SRC 开源 无黑箱。整个游戏在 GitHub 上开源,采用 GPLv3 协议。 OFF 离线畅玩 无需信号即可运行。整个游戏存储在您的手机中。 PRIV 无广告,无追踪 无需联网权限。不收集任何信息。数据绝不会离开您的手机。 PERM 无敏感权限 无需相机、麦克风、定位、通讯录、文件或网络权限。绝不索取任何权限。 FREE 永久免费 无价格,无应用内购买,无充值变强。完整游戏,完全免费。 ```
一场关于独立游戏《Astro Loop》(被描述为“《吸血鬼幸存者》风格的《太空大战》”)的 Hacker News 讨论,既展现了人们对该项目的热情,也反映出对人工智能生成内容日益增长的疲劳感。
支持者赞扬开发者发布了一款无广告、注重隐私且开源的项目,称其为“给人类的礼物”。该讨论帖也成为了其他人工智能辅助网页游戏(如《RoidBelt》和《Tankzone》)的展示平台。
然而,讨论很快转向了对该项目营销文案的批评。多名用户对落地页中“Claude 味”十足的语气表示不满,称其为缺乏个性的“企业心理咨询师式垃圾”。这引发了关于新兴“Claude 游戏”类型的更广泛讨论,人们质疑人工智能生成的营销便利性是否削弱了独立开源项目的真实性。尽管一些用户认为功能完善的免费软件不应因营销而受到评判,但另一些用户则对当前大语言模型生成文本中普遍存在的重复且过度诚恳的风格表达了日益强烈的反感。
耶鲁大学语言学家克莱尔·鲍恩(Claire Bowern)共同参与的一项研究显示,全球语言多样性在 1,000 到 3,000 年前达到顶峰,这一时期被认为是拥有数千种语言的“黄金时代”。与人们认为语言快速灭绝始于 500 年前欧洲殖民主义的观点不同,研究指出,语言的衰落开始得更早,且与古代国家及多民族帝国的兴起相吻合。 随着这些强大帝国的扩张,它们促进了自身语言的存续,同时取代或吸收了人口较少群体的语言。因此,现存的约 7,600 种语言只是人类原始语言遗产中一个片面的、带有历史偏见的样本。研究人员强调,理解这一长期趋势对于准确解读全球语言和文化演变的模式至关重要。
这段 Hacker News 讨论帖探讨了一项关于语言“黄金时代”的最新研究,引发了关于语言保护、演变及文化认同本质的广泛讨论。
核心议题包括:
* **语言的价值与功用:** 用户们探讨了濒危语言是具有内在价值,还是因为缺乏实用性而必然走向衰落。有人认为,要让一门语言存续,必须产生“巨著”或深厚的文学语料库;另一些人则认为,学习古语言(如梵语或赫梯语)能为理解现代相关语言的根源与逻辑提供重要洞见。
* **单一文化的迷思:** 讨论者对于“单一全球通用语”是否利大于弊存在分歧。虽然有人将其视为提高效率的途径,但许多人认为这会导致“认知多样性”的灾难性丧失,因为不同的语言塑造了独特的思维方式。
* **政治与文化力量:** 参与者指出,语言的支配地位在历史上与政治权力紧密相连(例如拉丁语、英语的传播,或从苏美尔语向阿卡德语的过渡)。他们强调,语言与政治及环境历史密不可分,语言的标准化往往需要中央权威的主动介入,有时甚至带有强制性。
本项目记录了将支持 MMU 的 Linux 成功移植到 ESP32-S31 (RV32IMAFBCNSUX) 架构的过程。由于开发期间无法获取 S31 的技术文档,该移植工作依赖于对自定义中断处理的逆向工程推测,特别是用自定义的 CLIC/SCLIC 驱动替代了标准的 PLIC。 为了适应硬件平台的局限性,内核采用了 Linux 6.12 版本,利用其 XIP(原地执行)支持,在优化设备 16MB PSRAM 使用的同时实现系统启动。 目前,基础系统运行正常,能够执行 shell 进程并运行 CoreMark 基准测试(得分约为 1058 次迭代/秒)。尽管内核可以启动且基础控制台访问已实现,但绝大多数特定于硬件的外设——包括 GPIO、以太网、I2C、SPI 和安全加速器——仍处于未测试、开发中或未实现状态。本项目代表了一项重大的“底层启动”工作,证明了 Linux 可以在 S31 上运行,但对于依赖大量外设的应用而言,尚未达到生产就绪水平。
近期一个展示在 ESP32-S31 微控制器上运行 Linux 的 GitHub 项目在 Hacker News 上引发了激烈讨论。
批评者认为该项目属于“氛围编程”(vibe-coded)——意指它很可能是由大语言模型(LLM)智能体生成的,并指出其稀缺且无用的文档是缺乏实质工程深度的证据。怀疑者质疑该移植的实用性,指出 S31 独特的内存管理单元(MMU)实现方式使得标准的 Linux 支持变得非主流,且与现有的实时操作系统(RTOS)方案相比,可能并不具备实用价值。
相反,支持者则将该项目视为一次成功的概念验证。他们强调,利用 LLM 智能体自动化底层移植是一项合法的省时技术,适用于基准测试和原型设计。尽管参与者都认同当前的实现尚处于“无法投入生产”的阶段,但许多人认为这项实验很有趣,并指出 ESP32-S31 具备真正符合 Sv32 标准的 MMU,这为在低功耗物联网硬件上运行复杂的内核开辟了新的可能性。归根结底,这场讨论突显了传统开发者与那些拥抱智能体辅助工作流以拓展嵌入式系统边界的开发者之间日益扩大的分歧。
此 Hacker News 讨论帖探讨了作家查尔斯·斯特罗斯(Charles Stross)近日发表的一篇博文,文中他拒绝在小说创作中使用人工智能。
评论区呈现出截然对立的观点。批评者认为斯特罗斯是“新卢德主义者”,他对人工智能的抵触带有针对科技行业和资本主义的个人偏见。他们认为,像大语言模型(LLM)这样的工具在情节分析、时间线管理和克服写作障碍等方面已经极具价值,并将这项技术视为人类进步的自然延伸。
相反,支持者则捍卫斯特罗斯的立场,强调人类主体性在艺术中的重要性。这一群体对“人工智能加速主义”持怀疑态度,常将围绕人工智能的热潮描述为一种世俗化的“新宗教”运动,认为其过度推崇技术驱动的“超验性”,却忽视了人类价值。
讨论还涉及了斯特罗斯博文中存在的一些技术性谬误,特别是他对生成对抗网络(GAN)和人工智能具身化的描述。一些用户认为,这些瑕疵削弱了他整体批判的力度。归根结底,这场辩论反映了更深层次的文化摩擦:一方将人工智能视为优化工作的实用工具,而另一方则担心它会将人类经验商品化,并侵蚀创作作品的“灵魂”。
Codeberg 最近封禁 AI 生成项目的举措,凸显了开源生态系统中一个关键的缺失。虽然许多人都在寻求“更好的 GitHub”,但现有的替代方案都未能复制 GitHub 最宝贵的特性:其**社交层**。 GitHub 不仅仅是一个代码仓库托管平台,它还是一个集身份认证、协作和项目发现于一体的中心化枢纽。虽然 Git 本身是去中心化的,但围绕它构建的基础设施——如 Issue、Pull Request 和社区标准——并非如此。自托管或碎片化的小众平台会造成阻碍,使习惯了 GitHub 通用惯例的贡献者望而却步。 目前的替代方案(如 GitLab、SourceHut 和 Radicle)难以弥补这一差距。它们要么受困于臃肿的商业化,要么存在非传统的工作流程,又或者技术尚未成熟。随着 GitHub 性能和可靠性的下降,业界依然缺乏一个“显而易见”的继任者。 作者认为,一个可行的替代方案需要将**社交体验作为核心产品**,而不是作为事后的补充。无论是需要一家新的、“无聊”的营利性公司,还是联邦身份验证技术的突破,挑战依然存在:要取代 GitHub,平台必须提供共享的社区和发现网络,从而实现大规模下无缝的开源协作。
讨论的核心在于替换 GitHub 的难度。用户们普遍承认虽然有很多替代方案,但并没有真正的替代品。该平台最主要的“粘性”并非来自代码存储本身(其他平台很容易处理),而是来自其**网络效应**。
辩论中的关键点包括:
* **发现与社交功能:** 许多开发者将 GitHub 作为寻找项目和了解同行开发动向的中心枢纽。批评者认为,这些“社交”功能往往被游戏化或效果不佳,有些人更倾向于通过 Hacker News 等平台获取口碑推荐。
* **“便利性”陷阱:** GitHub 提供了一套集成的 CI/CD、问题跟踪和托管套件。对于许多人,尤其是小型团队和独立开发者来说,自托管这些服务的成本和维护难度远超离开该平台所能带来的收益。
* **联邦化的需求:** 许多用户认为,解决方案在于联邦化模型(如基于 ActivityPub 的 Forgejo 或 Radicle),在这种模型下,问题(Issues)、星标(Stars)和拉取请求(PRs)可以独立于单一主机存在。
* **迁移障碍:** 问题跟踪和 PR 数据缺乏可移植性,加之免费 CI 运行器(包括 Windows/Mac)带来的便利,使得离开 GitHub 成为一项巨大的专业和财务障碍。