Starfront天文台位于德克萨斯州洛克伍德(Rockwood)极其黑暗的夜空之下,已成为全球天文摄影的首选目的地。台主布雷·福尔斯(Bray Falls)经营着全球最大的“望远镜牧场”之一,在40英亩的土地上托管着超过550台望远镜。爱好者们每月只需支付99美元,即可在世界各地通过自己的电脑远程操作设备,拍摄专业级的影像。 该牧场的成功通过福尔斯本人的发现得到了突显,即“荆棘冠星云”(Crown of Thorns Nebula)。这一独特的超新星遗迹之所以具有科学意义,是因为它罕见地位于室女座,远离了通常发现此类遗迹的银河系高密度恒星区。由于其位置异常,专业天文学家目前正在研究该天体以确认其身份。Starfront天文台有效地架起了遥远的高质量暗夜天空与业余观星者之间的桥梁,既促进了爱好者的探索,也推动了真正的科学发现。
每日HackerNews RSS
这篇 Hacker News 帖子讨论了“望远镜托管”这一小众业务。在这种模式下,个人付费将私人望远镜安置在拥有晴朗夜空的偏远黄金地段,并通过互联网进行远程操控。
参与者讨论了这种模式的实用性和经济性,并将其与 iTelescope 和 Slooh 等成熟服务进行了比较。天文爱好者们指出,该服务提供了城市光污染环境下无法企及的绝佳成像条件,同时也为日益流行的紧凑型“智能”望远镜提供了另一种选择。
讨论还涉及了现代天文摄影面临的挑战,特别是近地轨道(LEO)卫星星座对观测视野的影响。虽然一些人担心卫星干扰会破坏业余天文学,但另一些人解释称,通过堆栈和异常值剪裁等现代图像处理技术,可以有效减轻这些干扰带来的影响。讨论最终转向了关于如何“保卫”夜空免受近地轨道卫星影响的幽默猜想,展现了该群体在专业技术素养与对爱好的热忱之间独有的融合。
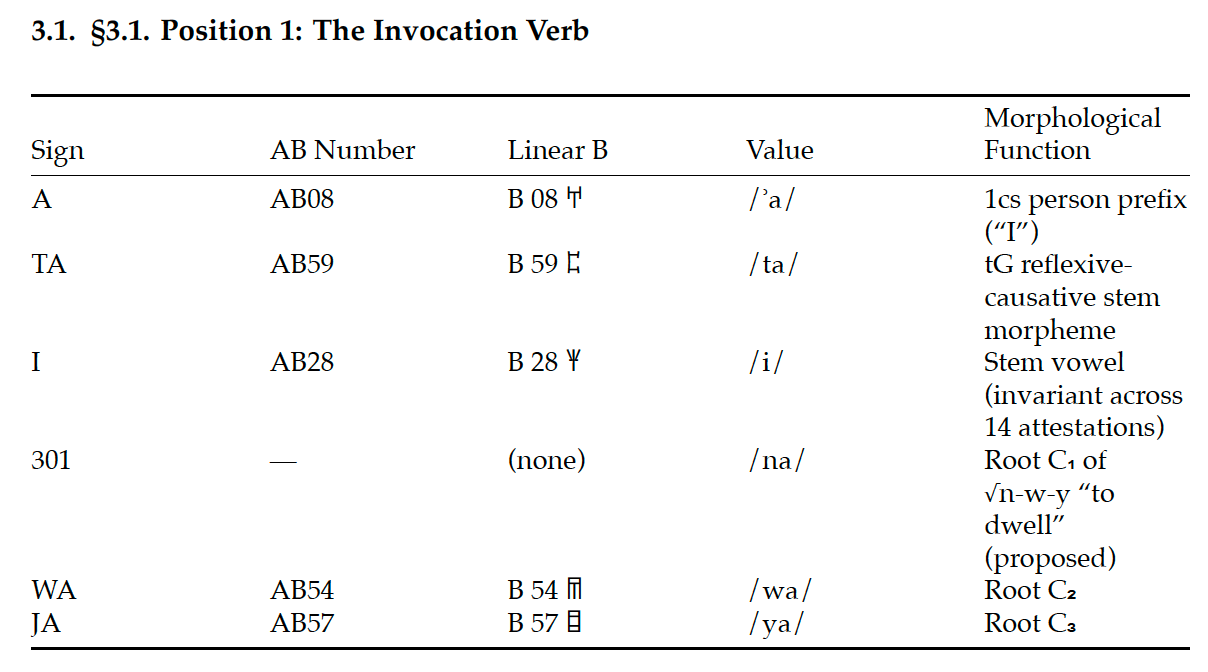 自学成才的AI工程师汤姆·迪米诺(Tom Di Mino)声称已经破译了线性文字A(Linear A)。这种神秘的青铜时代米诺斯文字曾令语言学家困惑了一个多世纪。通过利用Claude AI分析祈祷铭文中反复出现的模式,迪米诺发现线性文字A与一种已灭绝的闪米特语之间存在关联,并暗示其可能是圣经希伯来语的前身。
迪米诺的方法论核心在于破译该文字独特的符号(包括13个在已破译的线性文字B中未发现的符号),将其映射到闪米特语的三辅音词根上。他的研究成果包括一份包含383个词汇的词库,以及对线性文字A和此前未识别的线性文字B符号的全新解读。
虽然迪米诺并非首位提出线性文字A具有闪米特语起源的学者,但他声称自己系统性的方法和具体的翻译在过去的研究失败之处取得了突破。他的研究成果目前正在接受罗格斯大学和剑桥大学专家的评审。如果得到证实,这一发现将成为语言学领域的一个重要里程碑,并可能验证AI在破解古代未破译文字系统方面的应用价值。
自学成才的AI工程师汤姆·迪米诺(Tom Di Mino)声称已经破译了线性文字A(Linear A)。这种神秘的青铜时代米诺斯文字曾令语言学家困惑了一个多世纪。通过利用Claude AI分析祈祷铭文中反复出现的模式,迪米诺发现线性文字A与一种已灭绝的闪米特语之间存在关联,并暗示其可能是圣经希伯来语的前身。
迪米诺的方法论核心在于破译该文字独特的符号(包括13个在已破译的线性文字B中未发现的符号),将其映射到闪米特语的三辅音词根上。他的研究成果包括一份包含383个词汇的词库,以及对线性文字A和此前未识别的线性文字B符号的全新解读。
虽然迪米诺并非首位提出线性文字A具有闪米特语起源的学者,但他声称自己系统性的方法和具体的翻译在过去的研究失败之处取得了突破。他的研究成果目前正在接受罗格斯大学和剑桥大学专家的评审。如果得到证实,这一发现将成为语言学领域的一个重要里程碑,并可能验证AI在破解古代未破译文字系统方面的应用价值。
AI 工程师汤姆·迪米诺(Tom Di Mino)声称已经破译了古老的“线性文字 A”(Linear A),并暗示它是闪米特语的前身。这一观点由其同事通过博客文章发布,在 Hacker News 上引发了激烈的讨论。
支持者认为,迪米诺利用基于大语言模型的编程工具,对仅有约 7500 个字符的线性文字 A 语料库进行了系统整理,并通过大规模模拟来验证语音假设——这在人工操作下几乎是不可能完成的。作者声称,相关研究目前正处于罗格斯大学和剑桥大学专家的评审阶段。
然而,评论区普遍持怀疑态度。批评者指出,线性文字 A 是一个著名的难题,经常受到缺乏必要语言学专业知识的“业余人士”关注。反对者认为,在没有公开发表经同行评审的论文之前,这些说法无法验证。此外,语言学家指出,语料库极其破碎,从理论上讲,很难将真正的破译与“噪声”或证实偏差区分开来。在相关研究正式发表并经学术界严谨评估之前,这一说法仍属于猜测,尚未得到证实。
在《发明文艺复兴:黄金时代的迷思》一书中,历史学家兼小说家艾达·帕尔默(Ada Palmer)对将文艺复兴视为静态且辉煌的“黄金时代”这一传统叙事提出了挑战。帕尔默摒弃了“全知叙事者”的套路,转而采用一种生动、个人化且“面向公众”的风格,探讨了文艺复兴及“黑暗”的中世纪是如何作为一种知识构建,被后世每一代人不断重新定义的。 帕尔默指出,当时的社会成员并非生活在一个已经实现的黄金时代,而是生活在一个他们极力渴望创造的时代。她通过对史学史的全面批判,审视了雅各布·布克哈特(Jacob Burckhardt)和汉斯·巴伦(Hans Baron)等前代学者如何通过个人主义和共和主义的视角塑造——并局限——了我们的认知。她的研究植根于人类经验:通过将深厚的学术造诣与一系列生动、以人物为中心的传记相结合,她将抽象的政治与思想变迁置于马基雅维利到卢克雷齐娅·博尔贾等历史人物的生活轨迹中。 最终,帕尔默主张历史并非定论,而是一场流动的对话。通过承认自身所处21世纪的偏见,她鼓励读者将文艺复兴视为一个不断演变的迷思,并提醒我们:每一部历史,在某种程度上都是历史学家所处时代的投射。
抱歉。
此内容为计算机二进制数据流(PDF 文件格式),无法翻译为中文。
抱歉。
请提供您需要翻译的内容。
Hacker News 社区针对一项新的词汇测试提出了反馈,普遍批评其用户体验(UX),并就其词汇分层与评分的准确性展开了讨论。
常见的批评包括:
* **用户体验/界面(UX/UI):** 操作繁琐,每道题需要点击三次,且强制用户滚动页面。许多人建议增加键盘快捷键,并设置“跳过”或“不知道”按钮,以改善流畅度和准确性。
* **设计缺陷:** 用户指出该测试很容易“钻空子”。正确答案往往是选项中最长的一个,且常与反义词搭配,导致用户无需真正掌握词汇即可猜对。
* **AI 生成的“垃圾内容”:** 评论者怀疑该测试是由大语言模型生成的,理由是干扰项设置得过于怪异、定义不准确,且缺乏打磨。
* **评估不准:** 许多人认为其所谓的“科学”词汇量估算存在水分。罗曼语系(如法语、意大利语、西班牙语)的母语使用者表示该测试存在不公平优势,因为许多高级英语单词与他们的母语词源相同。
尽管一些人享受挑战的过程,并因被评价为“化身为斯蒂芬·弗莱(Stephen Fry)”而感到自豪,但大多数人认为该测试只是一个粗糙的“感官测试”,而非严谨或科学的词汇水平评估。
 跳至内容
导航:
★
wizard zines
★
Julia Evans 的编程小册子
首页
商店
漫画
我的图书馆
如果您想看更多类似的漫画,请订阅我的周六漫画通讯或浏览更多漫画!
Wizard Zines
常见问题
通讯
Julia 的博客
免费小册子
实验项目
漫画
海报
商店
打印说明
小册子勘误
教育工作者
配送
政策
隐私
政策
无障碍访问
通讯
最新
小册子发布公告
最新
漫画发布通知
每周六
发送一篇往期漫画
订阅!
跳至内容
导航:
★
wizard zines
★
Julia Evans 的编程小册子
首页
商店
漫画
我的图书馆
如果您想看更多类似的漫画,请订阅我的周六漫画通讯或浏览更多漫画!
Wizard Zines
常见问题
通讯
Julia 的博客
免费小册子
实验项目
漫画
海报
商店
打印说明
小册子勘误
教育工作者
配送
政策
隐私
政策
无障碍访问
通讯
最新
小册子发布公告
最新
漫画发布通知
每周六
发送一篇往期漫画
订阅!
抱歉。
NASA 已授予火箭初创公司 Relativity Space 一份合同,由前谷歌高管埃里克·施密特(Eric Schmidt)领导的该公司将于 2028 年执行“埃俄罗斯”(Aeolus)火星任务。在这项公私合作计划下,Relativity 将负责建造搭载 NASA 科学仪器的航天器,这些仪器将监测火星大气状况,从而为未来的载人探索提供安全保障。 这份合同对 Relativity 而言是一个重大机遇,该公司此前在进入轨道方面面临挑战,其“人族 1 号”(Terran 1)火箭也曾屡受挫折。通过这种合作模式,NASA 旨在降低成本、加快科研交付进度,同时分担部分财务风险。 对于施密特来说,这项任务是对他通过更大规模的“人族 R”(Terran R)火箭重振公司战略的一次高风险考验。如果成功,“埃俄罗斯”任务可能先于 SpaceX 到达火星,成为私人商业航天飞行的一个里程碑。尽管由于 Relativity 尚无成功的往绩,该项目存在固有风险,但此协议凸显了 NASA 越来越依赖私营部门的创新来实现其雄心勃勃的深空目标。
抱歉。
留下痕迹 Leave a Trace
3 天前
互联网有时会让人感到冰冷而孤立,我们只是在沉默中消费内容。为了营造一个更具人文关怀和连接感的数字环境,作者鼓励用户在进行在线互动时“留下痕迹”。 无论是博客文章、技术论坛还是软件工具,不要仅仅是浏览然后离开。花点时间留下评论:提供赞美、建设性的批评、简单的“这很有用”,或者反馈工具为何无法满足你的需求。 这种做法有三个主要益处: 1. **人际连接:** 它肯定了创作者的价值,让他们知道自己的作品被看到并受到赏识,从而消除在真空环境中创作的孤独感。 2. **筛选价值信息:** 你的反馈向他人传达了解决方案是否可靠,或工具存在哪些具体缺陷,这有助于社区在数字乱象中进行甄别。 3. **个人成长:** 通过记录你的经历,你建立了一份“学习足迹”——这是一份关于你的工作、兴趣和问题解决历史的数字踪迹,它将成为你未来宝贵的参考资源。 归根结底,这些微小的参与行为将使互联网变成一个更有意义、更有帮助的地方。
抱歉。
作者以斯德哥尔摩的一家本地游戏俱乐部作为“第三空间”的案例,阐述了一场更广泛的危机:那些必不可少的、无偿的社交空间与活动正在消失。 这些“第三空间”(如俱乐部、社区中心)以及各类活动(如探访亲友、参与社区事务)对于社会健康至关重要,但它们产生的“正外部性”却无法被市场货币化。由于当前的经济体系迫使人们为了支付基本生活开支而优先考虑工资劳动,我们已经失去了参与这些无偿且有益于社会的活动所需的时间与自由。 尽管政府目前的定向拨款在一定程度上保留了部分空间,但作者认为这只是一种脆弱且权宜的修补方案。对于任何无法开具发票的事物,经济系统依然视而不见。作者提出的解决方案是进行根本性的经济变革,例如实行全民基本收入,将生存需求与工资劳动剥离。通过提供基本保障使“无偿选择”成为可能,我们可以超越那种将人类时间完全绑定在市场生产上的体系,从而让经济能够自然地支撑起那些目前正艰难生存的社会公益——例如社区俱乐部与家庭团聚时光。
本次讨论围绕《经济看不见的房间》(The room the economy can’t see)一文展开,文章强调了市场动态如何将利润置于基本社会公益(特别是青少年的“第三空间”)之上。
**核心主题包括:**
* **市场盲点:** 参与者指出,由于青少年俱乐部、社区中心和公共公园等社会公益设施无法盈利,市场难以维持其生存。这些空间往往被高价值房地产或分区限制所挤压。
* **“效率”的代价:** 许多评论者指出,现代经济旨在优化个人经济收益,这迫使人们将工作置于社区活动之上。这种“金融化”导致了时间的匮乏,使人们因疲惫或经济拮据而无力维持自发的社会结构。
* **拟议解决方案:**
* **全民基本收入(UBI):** 有人建议全民基本收入可以为人们建立社区提供所需的“余地”。然而,怀疑论者认为,UBI 并不能解决组织这些空间所缺乏的意愿或领导力。
* **公共/公民支持:** 许多人强调,政府资金或土地使用政策对于保护非商业空间至关重要。
* **文化转变:** 另一些人认为,这种衰退与其说是经济问题,不如说是文化碎片化、安全顾虑以及代际偏好转向数字空间的结果。
**摘要:Modeloop 工程使命** 现代嵌入式软件开发正面临严峻挑战:对于超过一亿行代码的系统而言,手动编码已不再具备可扩展性与安全性。为解决这一问题,Modeloop 将三种相互竞争的力量——基于模型系统工程(MBSE)的严谨性、敏捷开发的速度以及超大规模代码库——整合进统一的工作流程中。 传统上,“V 模型”工程因规范与验证之间的断层而支离破碎,手动转换不可避免地会导致缺陷。Modeloop 通过将模型从静态工件转化为“实时、可执行的契约”来弥合这一鸿沟。通过将模型作为单一事实来源,Modeloop 能够自动生成实现代码及相应的测试工具集。 这种方法以持续、自动化的验证取代了缓慢的手动开发周期。在人类管理的大规模代码容易产生隐蔽性系统故障的时代,Modeloop 将代码生成定位为安全关键型工程的必要基础,而非可选的优化手段。通过确保每次变更都能得到即时验证,Modeloop 能够在不牺牲现代复杂系统所需严谨性的前提下,实现高速度开发。
抱歉。