 客户端挑战:您的浏览器已禁用 JavaScript。请启用 JavaScript 以继续。本站所需的某个组件无法加载。这可能是由浏览器插件、网络问题或浏览器设置引起的。请检查您的网络连接,禁用广告拦截器,或尝试使用其他浏览器。
客户端挑战:您的浏览器已禁用 JavaScript。请启用 JavaScript 以继续。本站所需的某个组件无法加载。这可能是由浏览器插件、网络问题或浏览器设置引起的。请检查您的网络连接,禁用广告拦截器,或尝试使用其他浏览器。
每日HackerNews RSS
抱歉。
 Valhalla 项目是旨在现代化 Java 内存模型的长期计划,现已正式达成一个里程碑:**JEP 401:值类与对象(Value Classes and Objects)** 即将作为预览功能进入 JDK 28 的 OpenJDK 仓库。
Valhalla 的核心目标是弥合易于阅读的代码与机器性能之间的差距。Java 长期以来依赖于基于标识(Identity)的对象——即每个变量都是指向堆分配对象及其元数据头的指针——这种方式对于现代硬件而言效率低下,因为现代硬件更偏好紧凑且对缓存友好的数据布局。
**关键点:** 开发人员现在可以使用 `value` 修饰符来定义不具备标识的类。这些“值对象”可以被 JVM 进行标量替换或平铺处理,从而显著降低堆开销并改善缓存局部性,同时仍允许开发人员使用熟悉的类结构、构造函数和验证逻辑。
**JDK 28 预览版的重要限制:**
* **尚未完全完备:** 这是第一阶段;特化泛型(Specialized Generics)和非空类型计划在后续版本中推出。
* **行为变化:** `==` 现在检查的是值可替代性而非对象标识;在值类上使用 `synchronized` 将会报错。
* **实验性功能:** 作为预览功能,它默认处于禁用状态,需要通过 `--enable-preview` 参数开启。
Valhalla 项目是旨在现代化 Java 内存模型的长期计划,现已正式达成一个里程碑:**JEP 401:值类与对象(Value Classes and Objects)** 即将作为预览功能进入 JDK 28 的 OpenJDK 仓库。
Valhalla 的核心目标是弥合易于阅读的代码与机器性能之间的差距。Java 长期以来依赖于基于标识(Identity)的对象——即每个变量都是指向堆分配对象及其元数据头的指针——这种方式对于现代硬件而言效率低下,因为现代硬件更偏好紧凑且对缓存友好的数据布局。
**关键点:** 开发人员现在可以使用 `value` 修饰符来定义不具备标识的类。这些“值对象”可以被 JVM 进行标量替换或平铺处理,从而显著降低堆开销并改善缓存局部性,同时仍允许开发人员使用熟悉的类结构、构造函数和验证逻辑。
**JDK 28 预览版的重要限制:**
* **尚未完全完备:** 这是第一阶段;特化泛型(Specialized Generics)和非空类型计划在后续版本中推出。
* **行为变化:** `==` 现在检查的是值可替代性而非对象标识;在值类上使用 `synchronized` 将会报错。
* **实验性功能:** 作为预览功能,它默认处于禁用状态,需要通过 `--enable-preview` 参数开启。
Project Valhalla 备受期待,它有望为 JVM 引入值类型。如今,该项目终于通过 JEP 401 在 JDK 28 中落地。这次重大的更新包含超过 19.7 万行代码,旨在通过允许对象“去标识化”来使 Java 实现现代化,从而使其像原生类型一样运行,实现紧凑的内存布局并减少指针间接寻址。
然而,Hacker News 社区对这一实现方案仍存在巨大分歧。支持者称赞其“循序渐进”的交付方式以及对向后兼容性的承诺,而批评者则认为该项目“为时已晚,力度不足”。怀疑论者指出,当前的实现因必须维持向后兼容性而受到严重限制,导致其优化措施较为“脆弱”,仅对极小的数据类型有效。
这场讨论凸显了一个根本性的矛盾:Oracle 设计团队优先考虑避免其他生态系统中那种“大爆炸式”的破坏性变更;而批评者则认为,Java 十年来的“追赶”导致其设计依然滞后于 C# 或 Rust 等语言。这一初步交付成果能否带来预期的性能提升仍存在激烈争论,许多人质疑为了这些收益而增加 JVM 的复杂性是否值得。
01 / 什么是 Akse? Akse 的含义是“轴”——即 X、Y 和 Z 轴。这就是核心理念:一款让儿童和青少年学习三维思考,而又不会迷失在复杂菜单中的工具。你可以通过放置和调整基础形状,或者绘制自己的轮廓来构建模型。所有测量单位均为真实的毫米,因此屏幕上看到的内容即是打印后手中所持的实物。Akse 由面向青少年儿童的创客空间 Skaperiet 开发,用于各类课程与工作坊,旨在让从构思到完成 3D 打印的路径尽可能缩短。一切功能均直接在浏览器中运行,无需安装任何程序。 🧒 面向儿童与青少年 简洁的工具、清晰的用词与大尺寸按钮。专为好奇的双手设计,适用于电脑和平板设备。 📏 真实毫米单位 所有测量单位均为毫米。孩子们绘制的内容与 3D 打印机输出的结果完全匹配。 🖨️ 随时打印 一键即可将整个项目导出为 STL 文件——这是所有 3D 打印机都能识别的格式。
抱歉。
在争夺人工智能基础设施主导权的竞赛中,关于 x86 和 Arm 架构孰优孰劣的争论在很大程度上被夸大了。虽然 x86 在历史上一直占据服务器市场的主导地位,但在围绕 GPU 的最关键插槽中,指令集架构(ISA)的选择正变得日益无关紧要。 在高价值的“一致性主机”(coherent host)插槽中,主要的“护城河”并非 ISA,而是允许 CPU 与 GPU 共享内存空间的高带宽专用互连技术(如 NVLink 或 Infinity Fabric)。英伟达即将推出的“NVLink Fusion”计划进一步印证了这一点,该计划旨在向包括 x86、Arm 以及未来的 RISC-V 在内的多种架构开放这一插槽。 同样,在负责为 GPU 提供数据的“标准主机”插槽中,超大规模数据中心运营商已经在向定制的 Arm 芯片迁移,且并未出现性能问题。ISA 仅在传统的企业环境中仍是一个重要因素,因为这些环境下的主机 CPU 必须执行“双重任务”,既要处理 GPU 端的任务,又要处理传统的应用层工作负载。归根结底,ISA 正日益成为由所选加速器平台决定的次要细节,而非一个独立的战略优势。
抱歉。
作者对 Replit 等 AI 编程初创公司提出了批评,认为它们在 TikTok 上进行的激进网红营销具有掠夺性。这些公司利用经济不稳定时期的 Z 世代作为目标群体,其操纵手段与多层次营销(MLM)骗局及加密货币泡沫如出一辙。 该批评主要集中在以下三点: 1. **“情绪编程”(Vibe-Coding)的迷思:** 这些广告暗示非编程人员可以轻松构建盈利软件,却忽略了软件开发中涉及的巨大技术、安全和法律复杂性(例如 GDPR 责任)。 2. **隐性财务风险:** 与传统业务不同,AI 开发成本不可预测。用户在尝试构建项目时,可能会产生高额且无上限的计算代币费用,而这些项目的成功概率在统计学上极低。 3. **不道德的剥削:** 作者认为,向渴望经济保障的人兜售“副业”梦想本质上是不诚实的。Replit 及其推介的网红未披露高成本和低成功率,正利用一代人对现代职场的疏离感和焦虑获利。最终,作者认为这是一种玩世不恭且不可持续的骗局,剥削了弱势用户。
抱歉。
Lift Challenge
4 天前
抱歉。
 作为知名 URI 注册中心的指定专家,作者就何时以及如何实施这些 URI 提供了指导。
**何时使用:** 知名 URI 最适合客户端了解某个站点,并需要发现全站策略或与整个站点进行交互(例如 `robots.txt` 或密码管理)的情况。
**误用情况:** 不应将其用作合法性的捷径、试图获得“官方”地位的手段或缩短网址的工具。强行在站点和服务之间建立一对一的关系会造成不必要的架构僵化。如果可以使用完整 URL,通常应优先选择完整 URL。
**关键考量:** 设计者必须处理有关发现机制的复杂性,因为用户的交互范围可能与站点的根目录不一致。此外,对于多用户平台而言,将知名位置用于内容元数据可能会产生问题,且往往需要复杂的底层架构。最后,设计者必须明确定义 URI 方案,为现有的旧位置制定迁移计划,并确保 URI 始终经过正式注册。归根结底,知名 URI 是用于解决特定问题的特定工具,不应将其作为默认选择。
作为知名 URI 注册中心的指定专家,作者就何时以及如何实施这些 URI 提供了指导。
**何时使用:** 知名 URI 最适合客户端了解某个站点,并需要发现全站策略或与整个站点进行交互(例如 `robots.txt` 或密码管理)的情况。
**误用情况:** 不应将其用作合法性的捷径、试图获得“官方”地位的手段或缩短网址的工具。强行在站点和服务之间建立一对一的关系会造成不必要的架构僵化。如果可以使用完整 URL,通常应优先选择完整 URL。
**关键考量:** 设计者必须处理有关发现机制的复杂性,因为用户的交互范围可能与站点的根目录不一致。此外,对于多用户平台而言,将知名位置用于内容元数据可能会产生问题,且往往需要复杂的底层架构。最后,设计者必须明确定义 URI 方案,为现有的旧位置制定迁移计划,并确保 URI 始终经过正式注册。归根结底,知名 URI 是用于解决特定问题的特定工具,不应将其作为默认选择。
要成为一名成功的 AI 研究员,你必须在**阅读文献与动手实践**之间取得平衡。研究不在于追逐潮流,而在于掌握交叉熵(cross-entropy)和奇异值分解(SVD)等基本概念。不要沉迷于基准测试,而应专注于深入理解,并培养构建能够测试新能力的数据集的能力。 这一过程需要的不仅是天赋,更是一种特定的**心境**: * **持之以恒与处变不惊**:洞察力往往源于偶然。将实验的成败都视为有价值的数据,并对“好得令人难以置信”的结果保持怀疑。 * **严谨细致**:保持“健康的偏执”。复杂的深度学习栈中常有漏洞;切勿将理解过程外包给 AI 工具,微小且未被察觉的错误可能导致科学结论失效。 * **工作流**:优先考虑快速迭代周期和高效的人机交互工作流,以减少任务切换。 * **视角**:离开键盘——伟大的想法往往在散步时涌现。摒弃自我与竞争,专注于提升自身的认知深度。 归根结底,研究就是“砍柴挑水”。这是一场关于纪律与严谨工作的长期修行。保持好奇,保持谦逊,并随着领域的发展不断更新你的思维模型。
关于“禅与机器学习研究的艺术”的 Hacker News 讨论,探讨了专业研究与哲学实践之间的交集。
评论者观察到在对“禅”的解读上存在明显的文化鸿沟。西方人通常将其视为增强个人能力、专注力或提高生产力的工具,而来自东亚背景的参与者则强调“禅”和道教的传统概念:无目的、无执着以及对自我的摒弃。
讨论强调,机器学习研究正如禅修实践一样,往往需要通过“静坐”来面对不确定性,并抵制强求结果的冲动。参与者认为,该领域对指标和发表数量的过度关注可能会适得其反,使研究从一种实验性的技艺变成一场“有毒”的争夺。归根结底,讨论指出,成功的科研需要平衡好奇心、耐心以及拥抱失败的能力——而这些品质往往被现代高压环境下对持续“获胜”的追求所掩盖。该讨论帖最终得出结论:科研的成功很少是纯粹智力驱动的线性路径,而是技巧、坚持以及偶尔闪现的直觉洞察力的综合体现。
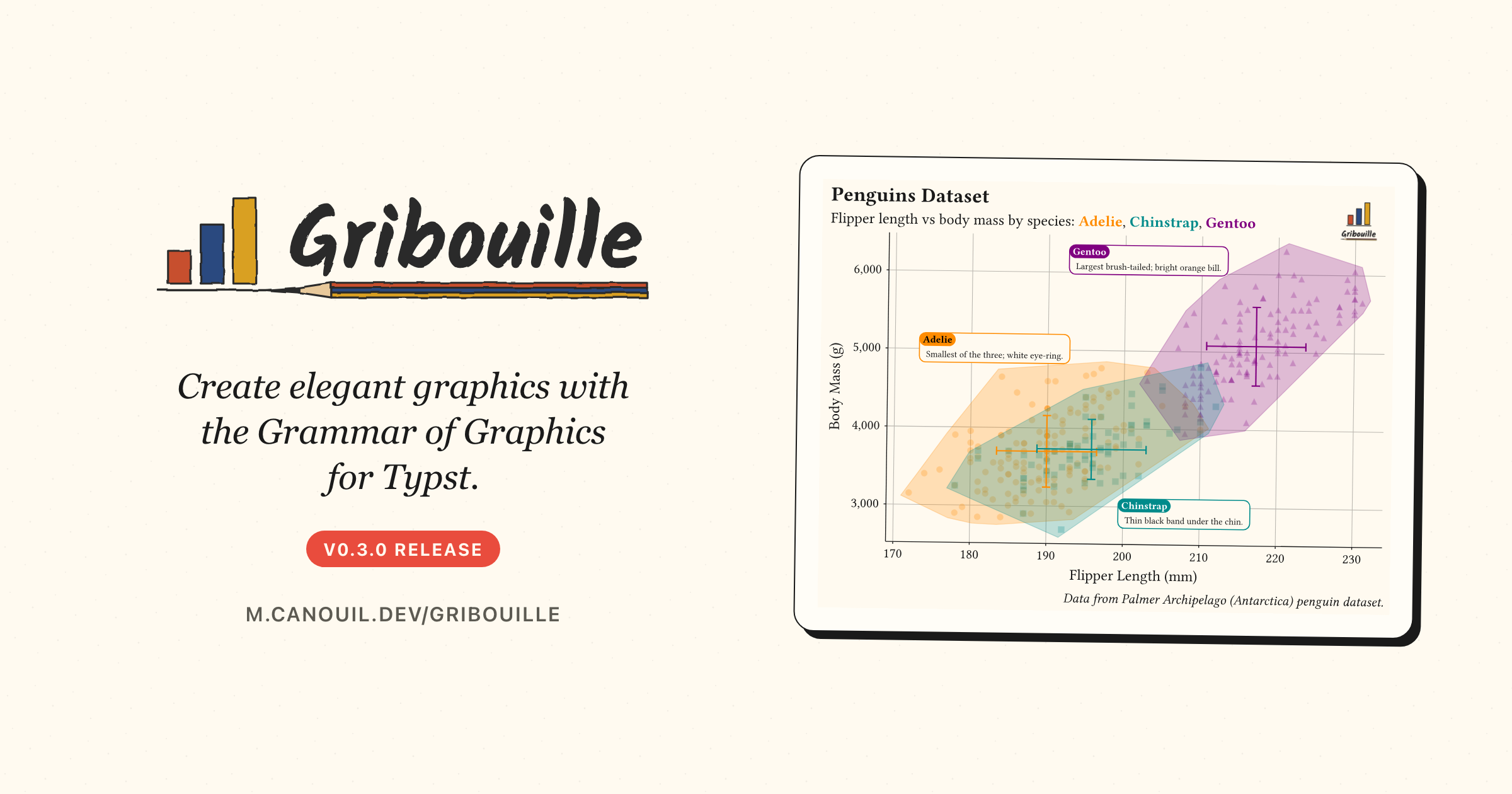 Gribouille 0.3.0 在 Typst 的绘图控制和易用性方面带来了显著改进。最值得注意的更新是增强了 `guides()` 函数,现在无需进行复杂的主题调整,即可直接控制坐标轴刻度、标签和图例。
**主要更新包括:**
* **改进的控制功能:** `guides()` 现在可以隐藏特定的坐标轴(如 `guides(x: none)`)或所有图例(如 `guides(default: none)`)。此功能同样适用于极坐标。
* **组合与主题:** `compose()` 现在支持 `theme` 参数,该参数可级联应用于所有面板。此外,`plot(..., defer: true)` 已被更简洁的 `defer(plot, ...)` 语法所取代。
* **几何图形与注释:** `geom-area()` 现在默认为堆叠排列,并针对不匹配的数据提供自动重采样。`annotate()` 增加了 `clip: false` 选项,允许标记延伸到面板边界之外。
* **优化:** 本次更新包括针对图例布局的各种错误修复、改进了二维分箱(2D bins)的统计功能,并通过对 Tinymist 友好的文档字符串增强了对 IDE 的支持。
此版本强调了管理绘图元素时更直观的 API,在保持主题简洁且易于维护的同时,更容易实现复杂的布局。
Gribouille 0.3.0 在 Typst 的绘图控制和易用性方面带来了显著改进。最值得注意的更新是增强了 `guides()` 函数,现在无需进行复杂的主题调整,即可直接控制坐标轴刻度、标签和图例。
**主要更新包括:**
* **改进的控制功能:** `guides()` 现在可以隐藏特定的坐标轴(如 `guides(x: none)`)或所有图例(如 `guides(default: none)`)。此功能同样适用于极坐标。
* **组合与主题:** `compose()` 现在支持 `theme` 参数,该参数可级联应用于所有面板。此外,`plot(..., defer: true)` 已被更简洁的 `defer(plot, ...)` 语法所取代。
* **几何图形与注释:** `geom-area()` 现在默认为堆叠排列,并针对不匹配的数据提供自动重采样。`annotate()` 增加了 `clip: false` 选项,允许标记延伸到面板边界之外。
* **优化:** 本次更新包括针对图例布局的各种错误修复、改进了二维分箱(2D bins)的统计功能,并通过对 Tinymist 友好的文档字符串增强了对 IDE 的支持。
此版本强调了管理绘图元素时更直观的 API,在保持主题简洁且易于维护的同时,更容易实现复杂的布局。
 DuckDB 通过重构 SQL 引擎的运作方式,已迅速成为领先的分析型数据库。与传统的服务器架构数据库(如 Snowflake、PostgreSQL)不同,DuckDB 是一个进程内库,消除了网络延迟和数据序列化的开销。它与 Python 和 Arrow 等工具的“零拷贝”集成使其能够直接在内存中处理数据,从而实现极高的运行速度。
其性能得益于以下架构设计:
* **列式存储**:高效处理特定列而非整行数据。
* **向量化执行**:以小批量方式处理数据,最大化 CPU 利用率。
* **基于数据块(Morsel)的并行处理**:无需复杂的中央协调即可在 CPU 核心间高效分配任务。
* **智能优化器**:利用谓词下推、子查询去嵌套和动态连接顺序优化等技术。
DuckDB 还具有极高的多功能性,可作为处理 Parquet、JSON 和 CSV 等本地文件的强大引擎。它能智能地利用元数据(如 Parquet 的最大/最小值统计信息)来裁剪数据,从而以媲美原生数据库的速度对原始文件执行分析查询。这种易用性、高性能以及与现代数据技术栈的深度集成,使其成为现代数据生态系统的基石。
DuckDB 通过重构 SQL 引擎的运作方式,已迅速成为领先的分析型数据库。与传统的服务器架构数据库(如 Snowflake、PostgreSQL)不同,DuckDB 是一个进程内库,消除了网络延迟和数据序列化的开销。它与 Python 和 Arrow 等工具的“零拷贝”集成使其能够直接在内存中处理数据,从而实现极高的运行速度。
其性能得益于以下架构设计:
* **列式存储**:高效处理特定列而非整行数据。
* **向量化执行**:以小批量方式处理数据,最大化 CPU 利用率。
* **基于数据块(Morsel)的并行处理**:无需复杂的中央协调即可在 CPU 核心间高效分配任务。
* **智能优化器**:利用谓词下推、子查询去嵌套和动态连接顺序优化等技术。
DuckDB 还具有极高的多功能性,可作为处理 Parquet、JSON 和 CSV 等本地文件的强大引擎。它能智能地利用元数据(如 Parquet 的最大/最小值统计信息)来裁剪数据,从而以媲美原生数据库的速度对原始文件执行分析查询。这种易用性、高性能以及与现代数据技术栈的深度集成,使其成为现代数据生态系统的基石。
最近的 Hacker News 讨论强调了 DuckDB 作为数据分析“超级工具”的崛起,特别是在处理中小型数据集(最高可达几 TB)时。
用户常将 DuckDB 描述为分析任务的颠覆者,它通常能以更快速、更易读的 SQL 取代繁琐的 Python/Pandas 工作流程。其主要优势包括:
* **高效性:** 作为一种使用列式存储和向量化执行的 OLAP 数据库,它在扫描、过滤和聚合大型数据集时,比传统方法快得多。
* **易用性:** 作为一个进程内、零依赖的库,它消除了管理独立数据库服务器的开销。它可以无缝集成到现有工作流程中,包括 Jupyter Notebook 和由大语言模型(LLM)驱动的开发环境。
* **多功能性:** 它充当了“数据强力胶”,允许用户在单个 SQL 语句中查询不同的数据源,如 CSV、JSON、Parquet,甚至是 SQLite 或 Postgres。
尽管一些评论者警告不要将其视为 SQLite(针对 OLTP/事务性工作负载优化)的直接替代品,但许多开发者会将二者结合使用。总而言之,DuckDB 因其良好的人机工程学设计以及能让普通笔记本电脑处理“大数据”问题的能力而备受赞誉。