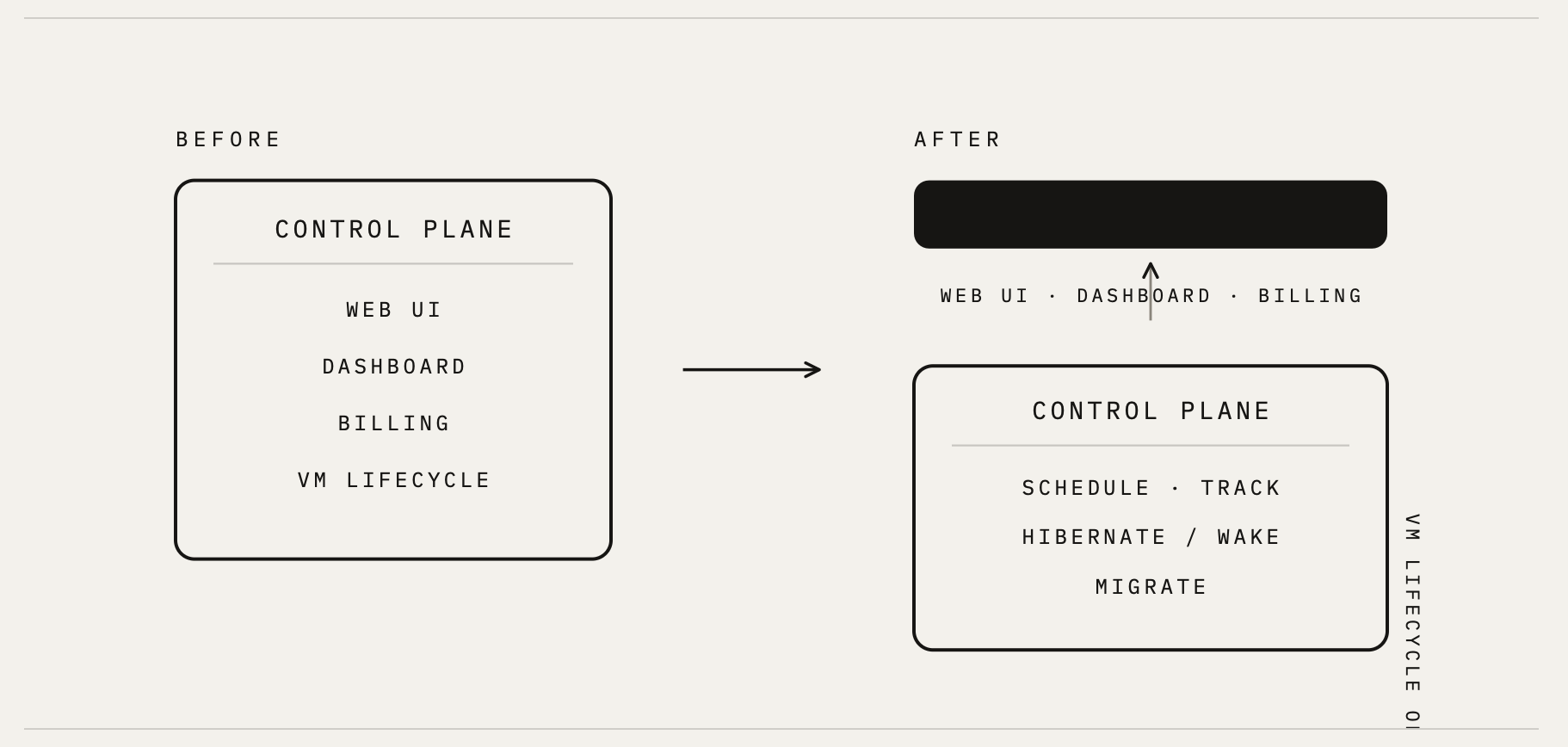
 OpenComputer 最初因架构局限于单一 Azure 区域且 CPU 配额固定,在扩展时面临困难。为克服这些限制,他们从单体系统转型为“基于单元”(cell-based)的架构,从而实现了近乎无限的扩展能力。
这种重构将系统拆分为称为“单元”的独立单元。每个单元在特定的云区域内处理完整的虚拟机生命周期,并可跨 AWS、Azure、GCP 或 OCI 进行统一部署。这使得容量扩展成为标准部署步骤,而非复杂的迁移过程。
为了管理这些分布式单元,OpenComputer 使用 Cloudflare Workers 和 D1 在边缘实现了全局注册表。当用户请求沙盒时,注册表会根据当前容量选择最优单元。一旦创建,单元便会自行管理其沙盒,同时通过每秒一次的心跳流确保准确的计费和实时状态更新。
通过将调度任务卸载到边缘并将虚拟机管理本地化到各个单元,OpenComputer 将启动时间缩短至一秒以内,并从受单区域约束的状态,转型为一个支持多云、可承载百万级 CPU 的平台,无论用户身处何地,都能保持高效性能。
OpenComputer 最初因架构局限于单一 Azure 区域且 CPU 配额固定,在扩展时面临困难。为克服这些限制,他们从单体系统转型为“基于单元”(cell-based)的架构,从而实现了近乎无限的扩展能力。
这种重构将系统拆分为称为“单元”的独立单元。每个单元在特定的云区域内处理完整的虚拟机生命周期,并可跨 AWS、Azure、GCP 或 OCI 进行统一部署。这使得容量扩展成为标准部署步骤,而非复杂的迁移过程。
为了管理这些分布式单元,OpenComputer 使用 Cloudflare Workers 和 D1 在边缘实现了全局注册表。当用户请求沙盒时,注册表会根据当前容量选择最优单元。一旦创建,单元便会自行管理其沙盒,同时通过每秒一次的心跳流确保准确的计费和实时状态更新。
通过将调度任务卸载到边缘并将虚拟机管理本地化到各个单元,OpenComputer 将启动时间缩短至一秒以内,并从受单区域约束的状态,转型为一个支持多云、可承载百万级 CPU 的平台,无论用户身处何地,都能保持高效性能。
每日HackerNews RSS
抱歉。
 © Valve Corporation。保留所有权利。所有商标均为其在美国及其他国家/地区的各自所有者所有。隐私政策 | 法律信息 | 无障碍访问 | Steam 订户协议 | 退款 | Cookie
© Valve Corporation。保留所有权利。所有商标均为其在美国及其他国家/地区的各自所有者所有。隐私政策 | 法律信息 | 无障碍访问 | Steam 订户协议 | 退款 | Cookie
抱歉。
请启用 JavaScript 和 Cookie 以继续。
抱歉。
本网站使用“Anubis”作为一项临时安全措施,旨在保护服务器免受大规模 AI 抓取。Anubis 采用了工作量证明(Proof-of-Work)机制——类似于用于对抗垃圾邮件的系统,它使得大规模抓取的计算成本变得非常高昂,而对普通人类用户的影响则微乎其微。 管理员计划最终过渡到更先进的指纹识别技术(例如分析浏览器特定的字体渲染方式),以便在不要求合法访客进行手动验证的情况下识别并拦截自动化机器人。 **注意:** Anubis 依赖于现代 JavaScript 功能。如果您使用了如 JShelter 等禁用了此类功能的浏览器安全扩展,则必须针对本域名将其关闭,方可访问本网站。
PII GUI 是一款基于 Tauri 2 (React/Rust) 构建的本地优先、开源桌面应用程序,旨在检测并遮盖 PDF、Markdown 及纯文本文件中的敏感信息。通过在设备本地处理数据,确保文档内容不会离开您的机器。
**主要功能:**
* **灵活的检测:** 使用可自定义的正则表达式规则或本地 ONNX 模型(可选,需一次性下载),识别电子邮件、地址和账号等个人身份信息(PII)。
* **工作流程:** 支持“先审查后遮盖”的流程,用户可通过图形界面手动切换和确认每一处匹配项。
* **安全导出:** 对于 PDF 文件,通过在敏感数据上方覆盖不透明矩形来实现“彻底遮盖”,确保底层文本无法被还原。
* **高级处理:** 具备针对长文档的页面感知分块功能、通过本地 SQLite 数据库保存的任务历史记录,以及多语言支持(英语、韩语、日语)。
* **注重隐私:** 架构将检测过程和文件输入输出限制在沙箱应用目录内,为处理敏感文档提供了一个安全环境。
PII GUI 适用于 macOS、Windows 和 Linux,采用 AGPL v3.0 许可证,欢迎社区贡献以改进其隐私分类检测模型。
抱歉。
欢迎参加 NimConf 2026!请记住日期和时间:2026 年 6 月 20 日,星期六,协调世界时(UTC)上午 11 点。NimConf 2026 是一场在线会议,将于 6 月 20 日举行。会议将免费直播,无需差旅——你可以在家参与,无需任何差旅和住宿费用。作为观众参与:所有演讲都将进行直播并录制以供日后观看。观看实时演讲可以让你向演讲者提问,并与其他观众和演讲者进行交流。每场演讲都将作为 NimConf 2026 播放列表的一部分在我们的 YouTube 频道首播。在等待会议期间,你可以观看过去四届的所有演讲,链接如下:2020 年、2021 年、2022 年和 2024 年。
抱歉。
 本摘要反映了作者作为软件创始人,将本地 AI 模型(特别是 Qwen 27B)集成到生产业务环境中的经验。
**主要结论:**
* **“本地与云端”的现实:** 尽管有人声称本地模型已达到“接近 Opus 的水平”,但它们仍是截然不同的工具。它们缺乏前沿模型的推理能力和自主性,不适合处理长周期的无监督编码任务。
* **最佳应用场景:** 本地模型擅长处理定义明确、边界清晰的任务,例如分析遥测数据、处理支持工单的诊断数据以及总结代码库。这些任务能带来切实的投资回报(例如挽回未结清的收入),同时确保数据主权。
* **技术挑战:** 大规模运行本地模型是一个运维问题。它需要专业的硬件(如 RTX 6000 Pro)、严格的量化管理和细致的调优。如果调优不当或过度使用模型,会导致“无限循环”和幻觉。
* **可靠性:** 作者强调本地模型需要人工监督。它们并非 Claude 或 ChatGPT 的“一劳永逸”型替代品,但能够提供抵御供应商风险和云端隐私担忧的重要保障。
总之,本地 AI 是一种功能强大的专业化工具,需要精细的管理、“磨合”和务实的期望,而非直接替代前沿智能。
本摘要反映了作者作为软件创始人,将本地 AI 模型(特别是 Qwen 27B)集成到生产业务环境中的经验。
**主要结论:**
* **“本地与云端”的现实:** 尽管有人声称本地模型已达到“接近 Opus 的水平”,但它们仍是截然不同的工具。它们缺乏前沿模型的推理能力和自主性,不适合处理长周期的无监督编码任务。
* **最佳应用场景:** 本地模型擅长处理定义明确、边界清晰的任务,例如分析遥测数据、处理支持工单的诊断数据以及总结代码库。这些任务能带来切实的投资回报(例如挽回未结清的收入),同时确保数据主权。
* **技术挑战:** 大规模运行本地模型是一个运维问题。它需要专业的硬件(如 RTX 6000 Pro)、严格的量化管理和细致的调优。如果调优不当或过度使用模型,会导致“无限循环”和幻觉。
* **可靠性:** 作者强调本地模型需要人工监督。它们并非 Claude 或 ChatGPT 的“一劳永逸”型替代品,但能够提供抵御供应商风险和云端隐私担忧的重要保障。
总之,本地 AI 是一种功能强大的专业化工具,需要精细的管理、“磨合”和务实的期望,而非直接替代前沿智能。
本摘要研究了在 2016 年款至强(Xeon)CPU 上运行 Gemma 4-26B 模型时,使用 25 个配置参数的实际效果。通过严格的“消融”测试——即逐一关闭各项参数并测量性能——作者发现,许多常用的参数要么是冗余的,要么受工作负载限制,甚至会被系统直接忽略。 **主要结论包括:** * **Flash Attention** 是最关键的因素,能将性能提升约一倍。 * **投机采样(Speculative Decoding,即草稿模型)** 对工作负载高度敏感:它能加速代码生成,但会显著拖慢摘要生成任务。此外,使用**固定的草稿长度**始终优于默认的“自动调优”设置。 * **线程数**应与物理核心数匹配(该 CPU 为 8 个);使用超线程会引入额外开销,反而降低速度。 * **许多参数属于“迷信式配置”**:某些参数(如 `--mla-use`)在此模型中并未实现,而另一些参数(如 `mlock`)则需要特定的宿主机配置才能生效。 作者建议,用户应通过系统日志核实各项参数,而非盲目照搬配置。未来的优化重点应在于通过调整模型量化来优化内存带宽,而非依赖复杂的命令行参数。
本文件定义了用于加速计算任务的 x86 扩展,最初重点关注机器学习工作负载中重要的矩阵乘法内核和低精度数据格式。ACE 扩展定义了矩阵乘法原语,通过以下新增功能增强了 AVX 和标量代码:包含 Tile 寄存器和 Block Scale 寄存器的 ACE 寄存器状态;消耗 AVX 寄存器输入并对 Tile 寄存器状态进行操作的数据处理指令;在 ACE 寄存器状态与 AVX 寄存器之间移动数据的指令;以及用于系统管理的各种状态和操作。ACE 提供了 AVX 向量与 ACE Tile 寄存器之间的紧密集成,将高计算密度的 Tile 处理操作与 AVX 全面的数据处理功能相结合。除了矩阵加速外,AVX10 框架下还提供了一系列专用的格式转换操作。
抱歉。
BlitzGraph 是一款高性能图数据库,旨在统一数据存储、搜索和业务逻辑。它通过几项核心创新简化了应用程序开发: * **灵活的数据建模:** 使用“多类(multi-kind)”实体,实体可以通过增加或减少类型进行演变,无需繁琐的角色表或数据迁移。 * **高效的遍历:** 提供 O(1) 复杂度的双向关系,消除了对反向查找表的需求。 * **统一查询:** 使用类型化 JSON (BQL) 在单个请求中处理复杂的嵌套展开、投影和过滤,从而避免了 N+1 开销。 * **集成功能:** 内置 BM25 全文搜索、丰富的数据类型(JSON、URL 等),并在引擎层面强制执行严格的参照完整性。 * **事务可靠性:** 使用智能且经过拓扑排序的事务,对整个状态进行验证而非逐行处理,确保复杂操作的一致性。 * **逻辑整合:** 将业务规则、验证和计算字段直接置入数据库模式中,减少了对分散中间件的需求。 通过将逻辑和搜索直接嵌入图引擎,BlitzGraph 在简化架构的同时,确保了数据完整性和开发人员的生产力。