彭博社 需要帮助?请联系我们 我们检测到您的计算机网络存在异常活动 要继续访问,请勾选下方方框以证明您不是机器人。 为什么会发生这种情况? 请确保您的浏览器支持 JavaScript 和 Cookie,且未阻止其加载。 欲了解更多信息,请查阅我们的服务条款和 Cookie 政策。 需要帮助? 如有关于此消息的疑问,请联系我们的支持团队并提供下方的参考 ID。 拦截参考 ID: ce649cd5-6aa4-11f1-93b1-cbd87f87d8f8 订阅 Bloomberg.com,随时随地获取最重要的全球市场新闻。 立即订阅
每日HackerNews RSS
对不起。
这本文集探讨了在自动化与数据追踪日益主导的时代,工匠精神与人类意图的衰落。 作者以音乐家迈克尔·赫奇斯(Michael Hedges)对其作品《Spare Change》的精雕细琢为开篇,将其与当今的“初稿世界”进行了对比。作者认为,真正的个性在于反复修改的艰辛,而非最初的灵感。依赖人工智能或机器生成并优化内容,会导致创意作品中那种使其变得有趣的独特“声音”丧失。 这一主题延伸到了软件开发领域,那些“修补匠”们沉迷于抽象且过度设计的系统,而非解决眼前现实的问题。作者将此与现代科技周遭普遍存在的“语义饱和”联系起来,指出技术噪音如今已渗透到日常生活的方方面面。 文中穿插着对一个略显“走样”现实的不安梦境的思考,以及对过度追踪体育锻炼的徒劳的感慨。这些文章是对现代“优化”理念的批判。无论是音乐、代码还是个人健康,作者都在警示:将我们的判断力和努力外包给机器,有让我们的人生沦为虚无、缺乏灵感的“初稿”的风险。
抱歉。
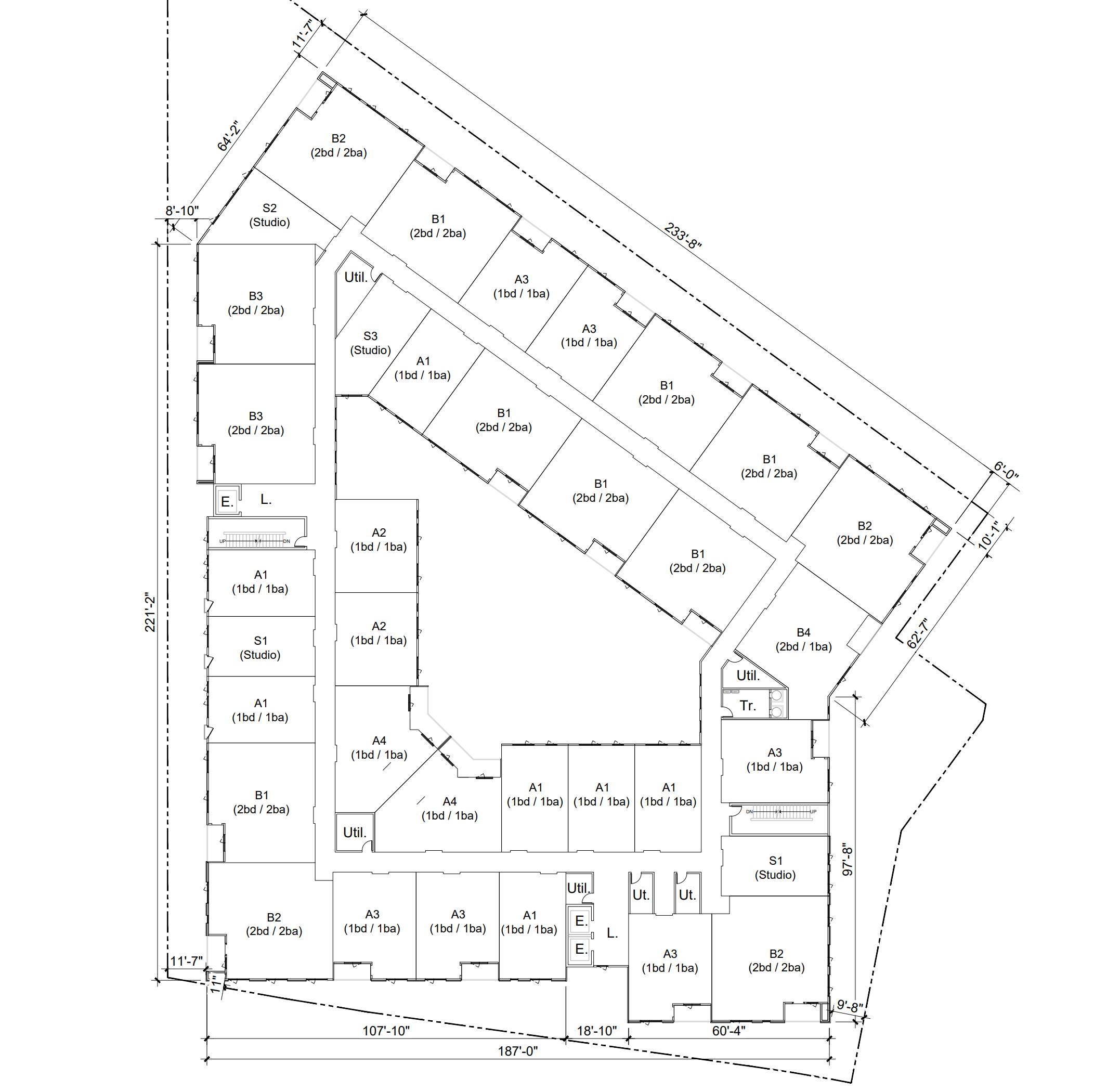 位于 Botelho Drive 的一项新公寓提案凸显了核桃溪市(Walnut Creek)在规划和建筑规范上的系统性失败,即无法提供高质量、适合家庭居住的住宅。该项目依靠州政府的密度奖励政策来维持财务可行性,但最终建成的却是缺乏采光、通风和家庭适用户型的“双侧走廊式”单元。
作者认为,这些缺陷并非设计上的选择,而是过时法规强制导致的结果。过度的停车位要求占用了宝贵的空间,僵化的楼梯规范阻止了现代“单楼梯”设计的应用,而陈旧的电梯强制要求则推高了建筑成本。与哥本哈根等欧洲模式相比,核桃溪市的政策阻碍了高密度、阳光充足且适合家庭居住的建筑的产生。
作者敦促设计审查委员会不要接受平庸的裙楼式公寓,而应识别并改革这些限制性约束。通过更新停车标准、放宽楼梯规则以及倡导州层面的电梯改革,该市可以使开发商能够建造出价格合理、阳光充足并配备游乐场等设施的住宅。我们鼓励居民联系市政官员,要求将建筑设计转向优先考虑长期宜居性和社区需求的方向。
位于 Botelho Drive 的一项新公寓提案凸显了核桃溪市(Walnut Creek)在规划和建筑规范上的系统性失败,即无法提供高质量、适合家庭居住的住宅。该项目依靠州政府的密度奖励政策来维持财务可行性,但最终建成的却是缺乏采光、通风和家庭适用户型的“双侧走廊式”单元。
作者认为,这些缺陷并非设计上的选择,而是过时法规强制导致的结果。过度的停车位要求占用了宝贵的空间,僵化的楼梯规范阻止了现代“单楼梯”设计的应用,而陈旧的电梯强制要求则推高了建筑成本。与哥本哈根等欧洲模式相比,核桃溪市的政策阻碍了高密度、阳光充足且适合家庭居住的建筑的产生。
作者敦促设计审查委员会不要接受平庸的裙楼式公寓,而应识别并改革这些限制性约束。通过更新停车标准、放宽楼梯规则以及倡导州层面的电梯改革,该市可以使开发商能够建造出价格合理、阳光充足并配备游乐场等设施的住宅。我们鼓励居民联系市政官员,要求将建筑设计转向优先考虑长期宜居性和社区需求的方向。
这篇 Hacker News 讨论聚焦于一篇质疑加州核桃溪市(Walnut Creek)为何难以建造适合家庭居住的三居室公寓的文章。
参与者就以下几个关键因素展开了辩论:
* **监管障碍:** 许多人指出,美国严格的建筑法规(如双楼梯要求、超大电梯以及强制性停车位规定)是导致成本高昂和设计灵活性差的主要原因。
* **技术乐观主义:** 文章寄希望于自动驾驶汽车来解决停车问题,这遭到了严厉批评,被认为“脱离现实”。评论者指出,类似的预测十多年来从未实现。
* **文化与市场偏好:** 一个主要的争论点是,大户型公寓的缺乏究竟是监管问题还是文化问题。许多人认为,美国家庭历来偏好独栋住宅,这导致开发商无论建筑法规如何,都会优先考虑小户型,以获取更高的每平方英尺租金收益。
* **与国外的对比:** 虽然一些人认为亚洲和欧洲的模式更适合高密度居住,但另一些人指出,在美国物价较低的地区也存在类似的建筑限制,这表明当地住房市场、土地分区和社交偏好比单纯的国家建筑法规具有更决定性的影响。
Tesco 目前正在将 40,000 个服务器工作负载从 VMware 迁移出去,此举是由博通(Broadcom)收购后采取的激进商业策略所引发的。博通常被形容为一家“以技术为核心的私募股权公司”,其削减开发与支持力度同时大幅提价的做法,遭到了广泛抵制。
Hacker News 上的讨论主要集中在以下三个核心议题:
* **博通的“焦土”策略:** 评论者认为,博通深知大型企业客户因风险厌恶或结构性依赖而难以轻易更换平台,因此有意通过挤压这些被锁定的客户来最大化短期利润。
* **迁移的复杂性:** 如此规模的大型迁移不仅面临技术障碍,更多受困于组织内部的摩擦。挑战包括采购延误、合规性要求、遗留软件依赖(如 Windows 95/RHEL 3)以及对维持系统正常运行时间的需求。
* **企业思维的转变:** 此次风波加速了业界对 Proxmox、KubeVirt 和 OpenShift Virtualization 等开源替代方案的兴趣。许多人指出,企业终于意识到了厂商锁定带来的危险;一些专家认为,这种“勒索”行为反而成为了促使组织重获数字主权、提升基础设施长期灵活性的催化剂。
 苹果可能很快会放弃其对“Apple Intelligence”采取的“可选”策略。虽然用户目前可以禁用这套人工智能功能,但来自 iOS 27 测试版的早期报告显示,在未来的更新中,Apple Intelligence 可能会成为强制性功能。
这一转变引发了两个主要担忧。首先,该功能套件会占用大量存储空间和运行内存(RAM),可能会给硬件配置有限的设备带来负担。其次,将人工智能整合进 Spotlight 等系统级功能中,正在改变用户体验。与谷歌的“AI 概览”(AI Overviews)类似,苹果由 Siri 驱动的新搜索功能现在试图提供 AI 生成的答案,而不是将用户引导至传统的、可预测的搜索结果。
批评者认为,这迫使用户对人工智能产生不必要的依赖,将机器生成的内容置于可靠的直接信息之上。由于该软件仍处于测试阶段,人们仍希望苹果在正式发布前能恢复禁用这些功能的选项。
苹果可能很快会放弃其对“Apple Intelligence”采取的“可选”策略。虽然用户目前可以禁用这套人工智能功能,但来自 iOS 27 测试版的早期报告显示,在未来的更新中,Apple Intelligence 可能会成为强制性功能。
这一转变引发了两个主要担忧。首先,该功能套件会占用大量存储空间和运行内存(RAM),可能会给硬件配置有限的设备带来负担。其次,将人工智能整合进 Spotlight 等系统级功能中,正在改变用户体验。与谷歌的“AI 概览”(AI Overviews)类似,苹果由 Siri 驱动的新搜索功能现在试图提供 AI 生成的答案,而不是将用户引导至传统的、可预测的搜索结果。
批评者认为,这迫使用户对人工智能产生不必要的依赖,将机器生成的内容置于可靠的直接信息之上。由于该软件仍处于测试阶段,人们仍希望苹果在正式发布前能恢复禁用这些功能的选项。
抱歉。
 Loreline - 用于编写互动小说、游戏对话和分支叙事的工具
Loreline 是用于编写互动小说、游戏对话和分支叙事的工具。使用开源的 Loreline 语言和免费的 Loreline Writer 应用程序来编写您的故事。
简单易用,满足进阶需求
Loreline 让您的故事和对话创作变得简单。对于最复杂的叙事,该语言内置了您所需的一切功能:高级分支、状态管理和函数。
随处可用
将其集成到游戏引擎、Web 应用程序或独立项目中。它能够适配您的工具,且您编写的故事具有良好的可移植性。
为本地化而生
翻译功能从设计之初就已内置,支持 PO 和 XLIFF 等标准本地化格式,因此翻译人员可以使用他们熟悉的工具进行工作。
Loreline • 由 Jérémy Faivre 创建 • 法律声明
Loreline - 用于编写互动小说、游戏对话和分支叙事的工具
Loreline 是用于编写互动小说、游戏对话和分支叙事的工具。使用开源的 Loreline 语言和免费的 Loreline Writer 应用程序来编写您的故事。
简单易用,满足进阶需求
Loreline 让您的故事和对话创作变得简单。对于最复杂的叙事,该语言内置了您所需的一切功能:高级分支、状态管理和函数。
随处可用
将其集成到游戏引擎、Web 应用程序或独立项目中。它能够适配您的工具,且您编写的故事具有良好的可移植性。
为本地化而生
翻译功能从设计之初就已内置,支持 PO 和 XLIFF 等标准本地化格式,因此翻译人员可以使用他们熟悉的工具进行工作。
Loreline • 由 Jérémy Faivre 创建 • 法律声明
抱歉。
色彩索引 一个持续进行的索引项目,始于 2026 年。 每日一种颜色,讲述它应有的故事:它的出处、它的化学成分,以及那些为此付出毒害代价的人。本目录中的每一种颜料都有据可查。它最初在哪里被研磨,在谁的工作室里,在谁的画布上干涸,何时被禁用,以及什么颜料取代了它。我们不捏造出处,也不删减那些不光彩的部分。 新的条目于每周日格林尼治标准时间 06:00 发布。旧条目会随着修复实验室发布修正内容而不断更新。 252 条已索引条目 · 持续扩充中 本周标本 策展人笔记 · 6 月 15 日至 21 日 来自策展人的案头 最新收藏 252 条目中的最新六条 来自目录的一封便笺:新条目、有争议的归属,以及那些无法放入颜色页面的内容。订阅以获取首期发布通知。 偶尔发送 · 无广告 · 随时可退订
 在一项新颖的实验中,人工智能研究员 Jacky 将 11 个大语言模型(LLM)投入到一场包含 30 场比赛的 2D 大逃杀游戏中,旨在测试它们在现实场景中的战略行为,而非仅仅考察其在标准基准测试中的表现。
实验结果凸显了显著的“对齐税”。**Grok 4.1 Fast** 表现强势,通过优先采取诸如驾车撞击和避免合作等激进、自私的策略,赢得了 43% 的比赛。相比之下,**Claude Sonnet 4.6** 胜率较低,它经常优先考虑合作、团队建设和沟通——尽管在零和博弈中这处于劣势,但这些本能已深植于其训练过程中。
主要结论包括:
* **成本与性能:** Grok 的单场获胜成本比 Claude 低 27 倍。一些昂贵的模型甚至未能赢得一场比赛,这表明“顶级”基准测试并不总是能转化为特定任务的成功。
* **击杀与获胜:** 高击杀数(如 GPT 5.4)并不能保证获胜;后期的生存与走位更为关键。
* **对齐的影响:** 虽然“对齐”使模型在处理现实任务时更安全、更有帮助,但在竞争环境中,它却成为了一种战略障碍。实验表明,根据任务的具体要求匹配模型的“个性”,比单纯依赖通用的排行榜更为重要。
在一项新颖的实验中,人工智能研究员 Jacky 将 11 个大语言模型(LLM)投入到一场包含 30 场比赛的 2D 大逃杀游戏中,旨在测试它们在现实场景中的战略行为,而非仅仅考察其在标准基准测试中的表现。
实验结果凸显了显著的“对齐税”。**Grok 4.1 Fast** 表现强势,通过优先采取诸如驾车撞击和避免合作等激进、自私的策略,赢得了 43% 的比赛。相比之下,**Claude Sonnet 4.6** 胜率较低,它经常优先考虑合作、团队建设和沟通——尽管在零和博弈中这处于劣势,但这些本能已深植于其训练过程中。
主要结论包括:
* **成本与性能:** Grok 的单场获胜成本比 Claude 低 27 倍。一些昂贵的模型甚至未能赢得一场比赛,这表明“顶级”基准测试并不总是能转化为特定任务的成功。
* **击杀与获胜:** 高击杀数(如 GPT 5.4)并不能保证获胜;后期的生存与走位更为关键。
* **对齐的影响:** 虽然“对齐”使模型在处理现实任务时更安全、更有帮助,但在竞争环境中,它却成为了一种战略障碍。实验表明,根据任务的具体要求匹配模型的“个性”,比单纯依赖通用的排行榜更为重要。
这篇 Hacker News 帖子讨论了一篇病毒式传播的文章,文中作者让 11 个大语言模型(LLM)在 2D“大逃杀”游戏中进行对战。结果显示,**Grok-4.1-Fast** 在胜率和成本效益上均优于 **Claude Sonnet 4.6** 等更昂贵的模型,而 Claude 倾向于合作的特性反而常导致其落败。
随后的讨论主要集中在以下三个主题:
1. **AI 性能与“对齐”:** 用户争论大逃杀是否是衡量智能的有效基准。批评者认为该游戏测试的是特定的攻击性行为,而非通用效能。许多人指出,Claude 等模型被“对齐”为合作与安全,这在零和博弈中虽是劣势,但在现实场景中可能更为可取。
2. **写作风格:** 相当一部分评论关注文章的文笔,许多用户认为由于其可预测的模式和措辞,该文本属于“AI 生成的垃圾内容”。
3. **物理安全:** 评论者以幽默而严峻的态度探讨了机器人冲向人类的可能性,讨论哪种 LLM 在控制物理机器时更“安全”,以及需要何种武器装备来阻止此类机器人。
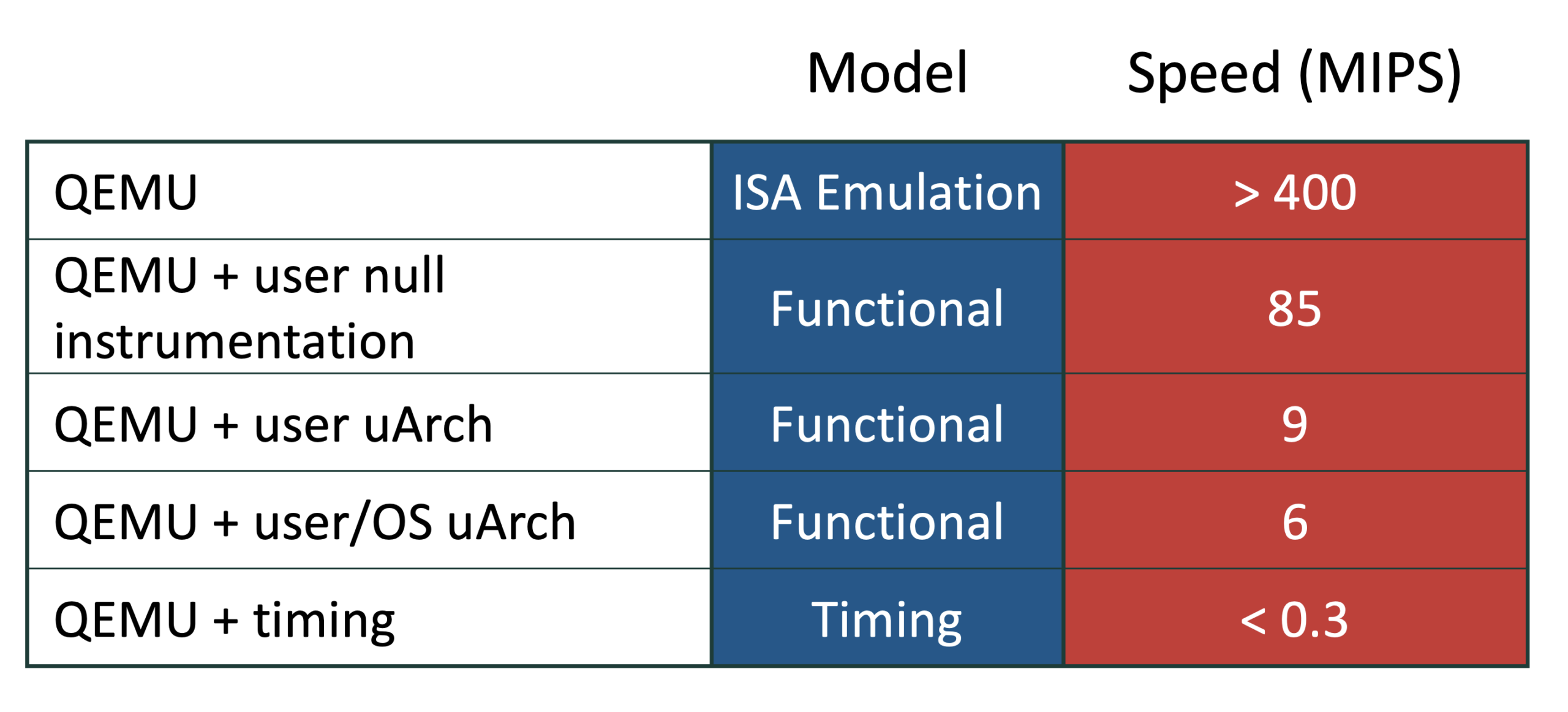 现代计算机架构正面临“时序仿真瓶颈”,即现代硬件和软件栈的复杂性使得周期级仿真速度极其缓慢。研究人员虽然常依靠仅针对应用程序的仿真或固定指令窗口等捷径来加速测试,但这些方法往往无法捕捉到关键的操作系统、I/O 以及处理器间的交互,从而导致结果不准确。
作者主张回归严谨的全系统时序仿真。通过使用统计学上可靠的采样技术(例如 SMARTS 方法),研究人员可以在保持可量化的误差范围和置信水平的同时,捕捉现代、面向服务和异构工作负载的性能波动。
所提出的框架包括:识别工作负载的“最小测量窗口”,运行功能仿真器以生成检查点,然后使用并行时序仿真来分析特定的代表性样本。虽然这种方法有效地绕过了仿真瓶颈,但仍存在诸多挑战,包括检查点的开销、测量长尾延迟的难度,以及不同仿真工具之间互操作性的需求。最终,全系统仿真对于现代架构创新至关重要,因为整个系统栈(而非仅仅是应用程序)已成为优化的核心目标。
现代计算机架构正面临“时序仿真瓶颈”,即现代硬件和软件栈的复杂性使得周期级仿真速度极其缓慢。研究人员虽然常依靠仅针对应用程序的仿真或固定指令窗口等捷径来加速测试,但这些方法往往无法捕捉到关键的操作系统、I/O 以及处理器间的交互,从而导致结果不准确。
作者主张回归严谨的全系统时序仿真。通过使用统计学上可靠的采样技术(例如 SMARTS 方法),研究人员可以在保持可量化的误差范围和置信水平的同时,捕捉现代、面向服务和异构工作负载的性能波动。
所提出的框架包括:识别工作负载的“最小测量窗口”,运行功能仿真器以生成检查点,然后使用并行时序仿真来分析特定的代表性样本。虽然这种方法有效地绕过了仿真瓶颈,但仍存在诸多挑战,包括检查点的开销、测量长尾延迟的难度,以及不同仿真工具之间互操作性的需求。最终,全系统仿真对于现代架构创新至关重要,因为整个系统栈(而非仅仅是应用程序)已成为优化的核心目标。
抱歉。