 在一项新颖的实验中,人工智能研究员 Jacky 将 11 个大语言模型(LLM)投入到一场包含 30 场比赛的 2D 大逃杀游戏中,旨在测试它们在现实场景中的战略行为,而非仅仅考察其在标准基准测试中的表现。
实验结果凸显了显著的“对齐税”。**Grok 4.1 Fast** 表现强势,通过优先采取诸如驾车撞击和避免合作等激进、自私的策略,赢得了 43% 的比赛。相比之下,**Claude Sonnet 4.6** 胜率较低,它经常优先考虑合作、团队建设和沟通——尽管在零和博弈中这处于劣势,但这些本能已深植于其训练过程中。
主要结论包括:
* **成本与性能:** Grok 的单场获胜成本比 Claude 低 27 倍。一些昂贵的模型甚至未能赢得一场比赛,这表明“顶级”基准测试并不总是能转化为特定任务的成功。
* **击杀与获胜:** 高击杀数(如 GPT 5.4)并不能保证获胜;后期的生存与走位更为关键。
* **对齐的影响:** 虽然“对齐”使模型在处理现实任务时更安全、更有帮助,但在竞争环境中,它却成为了一种战略障碍。实验表明,根据任务的具体要求匹配模型的“个性”,比单纯依赖通用的排行榜更为重要。
在一项新颖的实验中,人工智能研究员 Jacky 将 11 个大语言模型(LLM)投入到一场包含 30 场比赛的 2D 大逃杀游戏中,旨在测试它们在现实场景中的战略行为,而非仅仅考察其在标准基准测试中的表现。
实验结果凸显了显著的“对齐税”。**Grok 4.1 Fast** 表现强势,通过优先采取诸如驾车撞击和避免合作等激进、自私的策略,赢得了 43% 的比赛。相比之下,**Claude Sonnet 4.6** 胜率较低,它经常优先考虑合作、团队建设和沟通——尽管在零和博弈中这处于劣势,但这些本能已深植于其训练过程中。
主要结论包括:
* **成本与性能:** Grok 的单场获胜成本比 Claude 低 27 倍。一些昂贵的模型甚至未能赢得一场比赛,这表明“顶级”基准测试并不总是能转化为特定任务的成功。
* **击杀与获胜:** 高击杀数(如 GPT 5.4)并不能保证获胜;后期的生存与走位更为关键。
* **对齐的影响:** 虽然“对齐”使模型在处理现实任务时更安全、更有帮助,但在竞争环境中,它却成为了一种战略障碍。实验表明,根据任务的具体要求匹配模型的“个性”,比单纯依赖通用的排行榜更为重要。
每日HackerNews RSS
这篇 Hacker News 帖子讨论了一篇病毒式传播的文章,文中作者让 11 个大语言模型(LLM)在 2D“大逃杀”游戏中进行对战。结果显示,**Grok-4.1-Fast** 在胜率和成本效益上均优于 **Claude Sonnet 4.6** 等更昂贵的模型,而 Claude 倾向于合作的特性反而常导致其落败。
随后的讨论主要集中在以下三个主题:
1. **AI 性能与“对齐”:** 用户争论大逃杀是否是衡量智能的有效基准。批评者认为该游戏测试的是特定的攻击性行为,而非通用效能。许多人指出,Claude 等模型被“对齐”为合作与安全,这在零和博弈中虽是劣势,但在现实场景中可能更为可取。
2. **写作风格:** 相当一部分评论关注文章的文笔,许多用户认为由于其可预测的模式和措辞,该文本属于“AI 生成的垃圾内容”。
3. **物理安全:** 评论者以幽默而严峻的态度探讨了机器人冲向人类的可能性,讨论哪种 LLM 在控制物理机器时更“安全”,以及需要何种武器装备来阻止此类机器人。
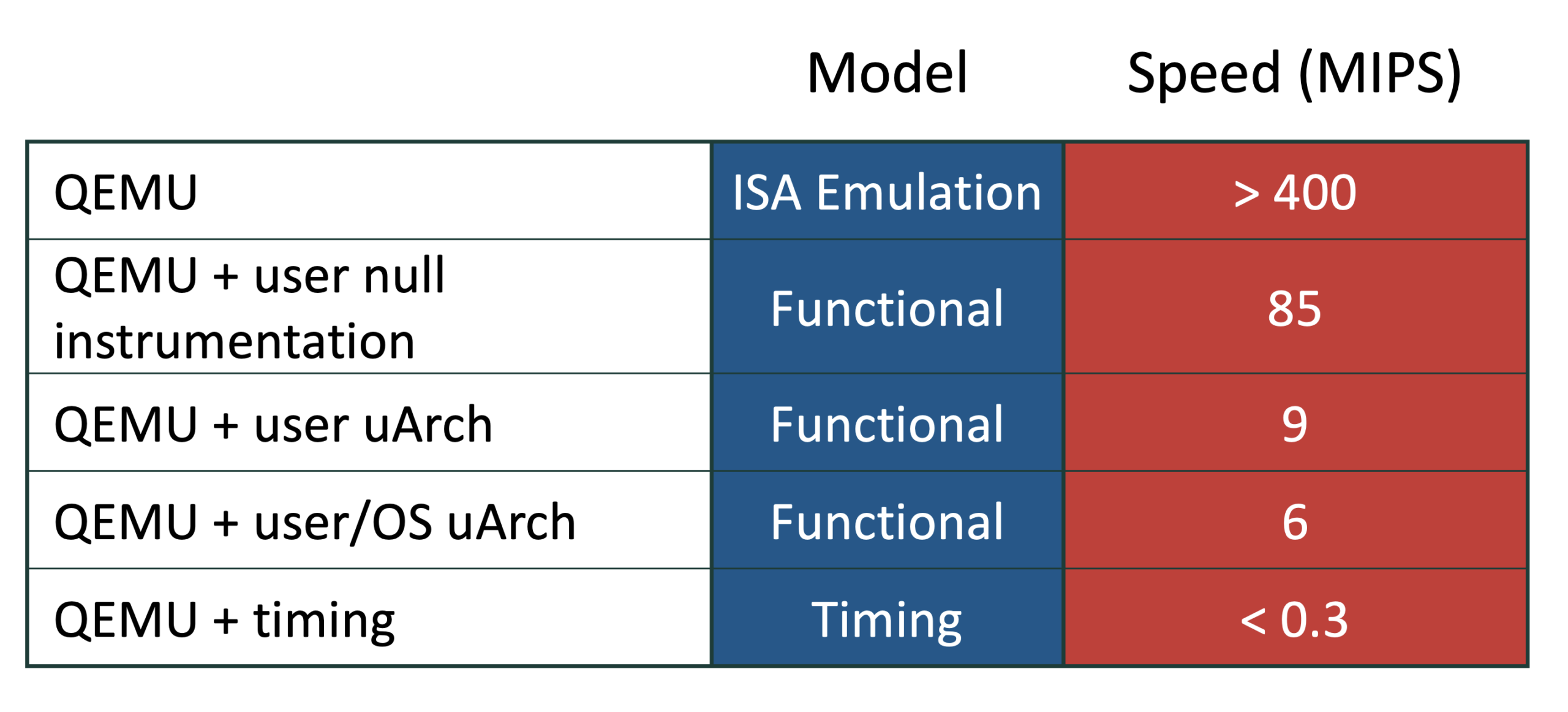 现代计算机架构正面临“时序仿真瓶颈”,即现代硬件和软件栈的复杂性使得周期级仿真速度极其缓慢。研究人员虽然常依靠仅针对应用程序的仿真或固定指令窗口等捷径来加速测试,但这些方法往往无法捕捉到关键的操作系统、I/O 以及处理器间的交互,从而导致结果不准确。
作者主张回归严谨的全系统时序仿真。通过使用统计学上可靠的采样技术(例如 SMARTS 方法),研究人员可以在保持可量化的误差范围和置信水平的同时,捕捉现代、面向服务和异构工作负载的性能波动。
所提出的框架包括:识别工作负载的“最小测量窗口”,运行功能仿真器以生成检查点,然后使用并行时序仿真来分析特定的代表性样本。虽然这种方法有效地绕过了仿真瓶颈,但仍存在诸多挑战,包括检查点的开销、测量长尾延迟的难度,以及不同仿真工具之间互操作性的需求。最终,全系统仿真对于现代架构创新至关重要,因为整个系统栈(而非仅仅是应用程序)已成为优化的核心目标。
现代计算机架构正面临“时序仿真瓶颈”,即现代硬件和软件栈的复杂性使得周期级仿真速度极其缓慢。研究人员虽然常依靠仅针对应用程序的仿真或固定指令窗口等捷径来加速测试,但这些方法往往无法捕捉到关键的操作系统、I/O 以及处理器间的交互,从而导致结果不准确。
作者主张回归严谨的全系统时序仿真。通过使用统计学上可靠的采样技术(例如 SMARTS 方法),研究人员可以在保持可量化的误差范围和置信水平的同时,捕捉现代、面向服务和异构工作负载的性能波动。
所提出的框架包括:识别工作负载的“最小测量窗口”,运行功能仿真器以生成检查点,然后使用并行时序仿真来分析特定的代表性样本。虽然这种方法有效地绕过了仿真瓶颈,但仍存在诸多挑战,包括检查点的开销、测量长尾延迟的难度,以及不同仿真工具之间互操作性的需求。最终,全系统仿真对于现代架构创新至关重要,因为整个系统栈(而非仅仅是应用程序)已成为优化的核心目标。
抱歉。
```tal@mac ~/code/flickey % git commit -m "ship it" [main 9f3c2a1] ship it 1 file changed, 12 insertions(+), 3 deletions(-) tal@mac ~/code/flickey % EN ↔ HEDE ↔ RUFR ↔ AR ENHE 这是一个用于展示构想的实验场,而非实际应用。```
开发者发布了一款名为 **Flickey** 的免费 macOS 菜单栏应用,旨在解决因输入法布局错误而带来的常见困扰。
与常规的系统设置不同,Flickey 可以针对不同的应用程序甚至浏览器标签页记忆你的首选语言,确保你在开始打字前已切换至正确的布局。如果出现输入错误,双击 Shift 键即可纠正最后一段文本。该应用完全在本地运行,无需账号,并采用“随心付费”模式。
这款工具在 Hacker News 社区反响良好,尤其是对于那些因 macOS 缺乏 Windows 上早已具备的细粒度窗口级语言设置而感到苦恼的多语言用户来说。尽管一些用户对基于辅助功能的应用提出了一些常见的安全顾虑,但许多人还是称赞开发者解决了一个长期存在的痛点。讨论还涉及了各大操作系统对多语言用户需求关注不足的普遍不满,一些贡献者也分享了诸如 Karabiner-Elements 或类似开源项目的替代方案。
 2026年前五个月,公用事业规模太阳能发电量在加州独立系统运营商(CAISO)电网中超过天然气,成为主要电力来源。与2024年相比,太阳能发电量增长了21%,而天然气发电量则骤降60%。
这一转变归功于基础设施的显著增长:自2024年4月以来,太阳能装机容量增至25吉瓦(增长19%),电池储能容量激增79%达到16吉瓦,而天然气装机容量则停滞在29吉瓦。电池储能在平衡中午太阳能盈余以供高峰时段使用方面发挥了关键作用,其放电率较2024年增长了两倍。
尽管电力需求增长了7%,但净内部发电量却下降了19%。这一缺口通过电力进口翻倍得到了填补,并得益于太平洋西北地区水电供应的增加以及新墨西哥州SunZia风电项目的助力。这些因素,加上对天然气依赖的停滞和电池的战略性整合,凸显了加州能源格局正向可再生能源和区域互联互通进行重大转型。
2026年前五个月,公用事业规模太阳能发电量在加州独立系统运营商(CAISO)电网中超过天然气,成为主要电力来源。与2024年相比,太阳能发电量增长了21%,而天然气发电量则骤降60%。
这一转变归功于基础设施的显著增长:自2024年4月以来,太阳能装机容量增至25吉瓦(增长19%),电池储能容量激增79%达到16吉瓦,而天然气装机容量则停滞在29吉瓦。电池储能在平衡中午太阳能盈余以供高峰时段使用方面发挥了关键作用,其放电率较2024年增长了两倍。
尽管电力需求增长了7%,但净内部发电量却下降了19%。这一缺口通过电力进口翻倍得到了填补,并得益于太平洋西北地区水电供应的增加以及新墨西哥州SunZia风电项目的助力。这些因素,加上对天然气依赖的停滞和电池的战略性整合,凸显了加州能源格局正向可再生能源和区域互联互通进行重大转型。
StarScope 是一个现代化的移动优先平台,旨在为全球业余天文学家填补信息鸿沟。与那些优先考虑北半球视角并设置会员门槛的传统组织不同,StarScope 实现了真正的南北半球对等,确保南半球的观测者也能获得一流且定制化的工具。 该平台提供实时的天体观测指南,包括针对行星、深空天体和流星雨的本地化“今夜星空”建议。用户可以通过实时自动化推送随时了解最新资讯,涵盖 NASA GCN 瞬变源、NOAA 空间天气、近地天体以及最新的 Arxiv 天体物理学预印本。 除了技术数据流,StarScope 还建立了一个全球性、经过监管的社区,供爱好者们交流心得并获取精选的设备指南。通过摒弃复杂且过时的界面并注重易用性,StarScope 为现代观测者提供了一个精简、全面的资源,无论他们身处何地或处于何种经验水平。
抱歉。
这篇文章认为,埃隆·马斯克之所以能成为世界首富,是建立在一种“庞氏骗局”之上,而非交付了其所承诺的未来技术。尽管马斯克在超级高铁、火星殖民和全自动驾驶出租车等项目上屡屡做出无法兑现的承诺,但他通过利用投资者的信任和财务操纵,维持住了公司的高估值。 作者指出,马斯克的商业帝国是一系列相互关联的“空壳游戏”。在收购X导致投资银行巨额亏损后,马斯克据称利用其政治影响力及人工智能热潮来救助旗下公司。通过将xAI等表现不佳的资产与真正成功的SpaceX合并,马斯克策划了一场估值达1.77万亿美元的首次公开募股(IPO),作者认为这完全脱离了财务现实。 令人担忧的是,这个“庞然大物”目前正受到华尔街的支持,华尔街通过修改规则允许SpaceX直接纳入主要股票指数。由于许多美国人持有指数基金,作者警告称,普通公民正被迫为这种脆弱的金融结构买单;一旦该计划最终崩盘,数百万人的退休储蓄将面临巨大风险。
这篇 Hacker News 讨论帖针对保罗·克鲁格曼(Paul Krugman)的一篇文章展开了热议。克鲁格曼在文中声称,埃隆·马斯克(Elon Musk)的财富和商业成功并非源于真正的创新,而是依赖于“金融把戏”和投资者炒作,本质上如同庞氏骗局。
讨论呈现出高度的两极分化:
* **批评者**认为,马斯克的财富很大程度上是投机性的,建立在狂热崇拜、政府补贴以及操纵市场的能力之上。许多人强调,他过度承诺(例如超级高铁、全自动驾驶承诺)以及向极右翼的政治立场转变,损害了他的声誉。一些人认为他仅仅是一个缺乏深厚技术理解的“管理骗子”。
* **支持者**则捍卫马斯克,称他是一位罕见的远见卓识者,成功攻克了其他人认为不可能或无利可图的行业(如电动汽车、商业航天)。他们认为,他在彻底改变汽车工业和降低发射成本等方面的实质性成就不可磨灭,克鲁格曼的批评不过是一位脱离现实的评论员所发表的党派偏见。
归根结底,该讨论帖反映了一种更广泛的社会分歧:一方认为马斯克是一个利用缺陷金融体系、被过度吹捧的危险“兄弟寡头”;而另一方则认为他是一位极其大胆的企业家,其“账面财富”是对他推动巨大工业进步的合理回报。
请启用 JavaScript 并关闭广告拦截器

抱歉。
在这个痴迷于自动化的世界里,许多组织误将效率等同于卓越,却忘记了“连接的工作”并非额外成本,而是核心目的。 真正的忠诚如同“大理石罐”一样建立:它并非源于宏大的姿态或交易性的指标,而是源于持续不断、点滴真诚的关怀。服务是一场独白,即产品的技术交付;而待客之道则是一场对话,它发生在你让客户感受到你与他们站在同一阵线之时。 随着人工智能将商业的交易层面商品化,人类的共情能力成为唯一持久的竞争优势。组织往往陷入“麦克纳马拉谬误”,忽视那些无法量化的事物,并优化掉了那些促进客户留存的、极具人情味的互动。苹果和西南航空之所以成功,是因为它们利用技术来“垫高底线”(提高效率),同时将人类从琐事中解放出来去“提升上限”(建立连接)。 为了建立真正的护城河,领导者必须停止将指标视为目标,转而关注“关系层面”。通过将枯燥的工作自动化,并赋予员工倾听、记忆和关怀的能力,企业可以建立起一种无形的、可复利的,且竞争对手无法复制的信任根基。
抱歉。
 这六个数学谜题各不相同,涵盖了遗产纠纷、椰子分配、图论以及洗牌等多个领域,但它们都共享一个优雅的共同策略。这些问题乍看之下似乎难以解决,甚至无法实现,但只要引入一个看似无关的“催化剂”元素,就能迎刃而解。
正如经典的“17只骆驼”谜题一样——通过临时借入第18只骆驼简化遗产分配计算,最后再将其取回——这些解决方案都依赖于添加一个辅助对象来平衡数学关系。无论是向一副牌中加入一张小丑牌、在天平上放置一枚“已知重量”的硬币,还是在森林的树木之间架设一座虚构的桥梁,这些添加的组件都能简化逻辑,并在目标达成后随之消失。
这种“添加元素以满足约束、解决问题,最后舍弃辅助”的原则,是一种强大的启发式思维。这些谜题展示了创造性思维如何通过暂时扩展系统,将复杂且陷入僵局的场景转化为简单直观的问题,从而达到优雅的解决方案。
这六个数学谜题各不相同,涵盖了遗产纠纷、椰子分配、图论以及洗牌等多个领域,但它们都共享一个优雅的共同策略。这些问题乍看之下似乎难以解决,甚至无法实现,但只要引入一个看似无关的“催化剂”元素,就能迎刃而解。
正如经典的“17只骆驼”谜题一样——通过临时借入第18只骆驼简化遗产分配计算,最后再将其取回——这些解决方案都依赖于添加一个辅助对象来平衡数学关系。无论是向一副牌中加入一张小丑牌、在天平上放置一枚“已知重量”的硬币,还是在森林的树木之间架设一座虚构的桥梁,这些添加的组件都能简化逻辑,并在目标达成后随之消失。
这种“添加元素以满足约束、解决问题,最后舍弃辅助”的原则,是一种强大的启发式思维。这些谜题展示了创造性思维如何通过暂时扩展系统,将复杂且陷入僵局的场景转化为简单直观的问题,从而达到优雅的解决方案。
对不起。