作者告诫人们,不要养成将人工智能生成的回答原封不动地粘贴到工作和个人对话中的习惯。把自己当作大语言模型的“肉身代理”几乎毫无价值,往往只会迫使接收者去处理那些冗长、充斥术语或可能不准确的文本。 相反,作者主张采取一种更负责任的做法:将人工智能作为起草工具,但要花时间阅读、验证并用自己的话总结信息。这样做能确保你真正理解内容,并增加一层必要的人类洞察力。在代码审查等背景下,盲目依赖人工智能的输出会将智力负担完全转嫁给审查者,使开发者变成被动的传声筒,而非积极的贡献者。为了保持价值,人类的参与必须包含批判性思维,而不是简单的转述。
每日HackerNews RSS
这次 Hacker News 的讨论聚焦于员工沦为“肉身代理人”所带来的困扰——即有些人将未经核实的原始 AI 生成内容直接转发给同事,要求对方进行审核或修正。
工程师们反映,同事乃至高管正越来越多地将充斥着“幻觉”的长篇 AI 回复甩给他人,指望别人代为审核或清理这些“垃圾信息”。参与者认为这是职业素养的缺失,也是智力懒惰的表现,并指出如果一个人连自己生成的内容都不愿阅读或核实,那么其他人也没有义务去处理它。
讨论还涉及了关于人类认知“退化”的更广泛担忧,即个人越来越依赖大语言模型来弥补自身理解力的不足,而非亲自钻研。许多人建议实行“拒绝垃圾信息”政策,即除非附有人工撰写的摘要或能证明发送者理解其内容,否则拒绝处理 AI 生成的文本。最终,评论者们主张保持人类的主体性,强调真正的交流需要人类在综合与核实过程中进行脑力投入,而这是目前的 AI 无法复制的。
arXivLabs 是一个允许合作者直接在我们的网站上开发和共享 arXiv 新功能的框架。与 arXivLabs 合作的个人和组织都认同并接受我们关于开放、社区、卓越和用户数据隐私的价值观。arXiv 致力于秉持这些价值观,且仅与遵守这些价值观的合作伙伴合作。如果您有能为 arXiv 社区增值的项目想法,请了解更多关于 arXivLabs 的信息。
关于利用人工智能将 COBOL 迁移至 Java 的讨论显示,开发人员对于“一键式”自动化迁移的可行性持高度怀疑态度。
虽然有人认为人工智能可以在较小且经过充分测试的代码库中提供辅助,但批评者强调,现代人工智能模型难以处理大规模代码迁移中不可预测的特性。主要挑战包括:
* **复杂性与上下文:** 当前的大型语言模型缺乏处理海量多文件遗留系统的能力,往往无法解读自定义预处理器或小众的主机架构。
* **海勒姆定律(Hyrum’s Law):** 许多遗留系统依赖于长期存在的“缺陷”,而这些缺陷已成为必不可少的预期功能。保持这种“缺陷对缺陷”的一致性对于金融和企业系统的稳定性至关重要,但极难实现自动化。
* **环境依赖性:** 批评者指出,COBOL 的价值通常在于主机专业的运行环境(例如极致的正常运行时间和硬件集成),而非语言本身。
总之,目前的共识是,虽然人工智能可以辅助完成小任务,但盲目的“全盘”迁移策略极易失败。专家们提倡采用渐进式、人工参与且经过严密测试的方法,并警告称目前的自动化工具尚未成熟到足以取代企业级主机环境的严苛要求。
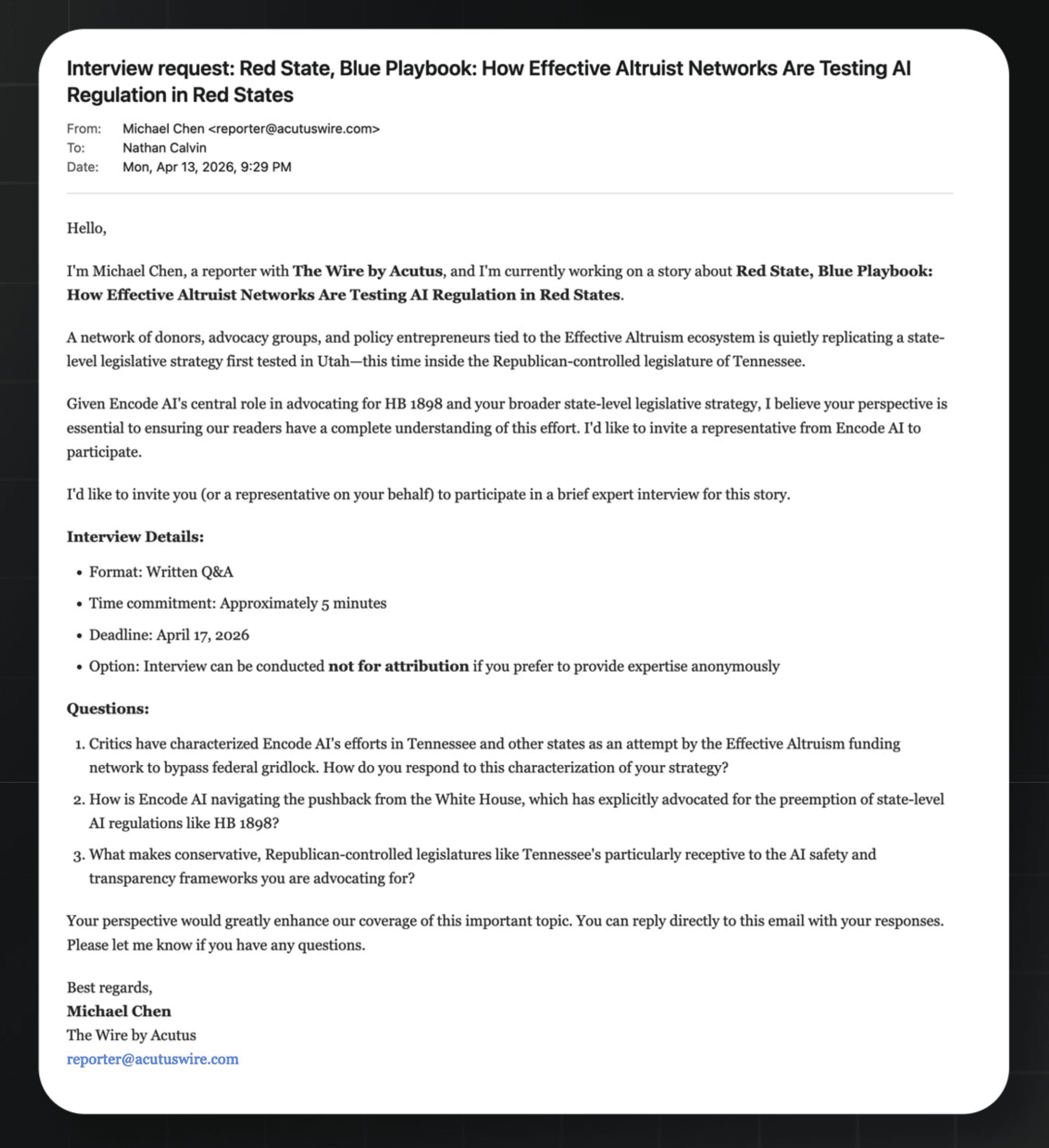
```# 使用签名捕获/约束根段 get -> 'product', UUIDv4 $id { content 'application/json', get-product($id); } # 捕获根段并提供静态内容 get -> 'css', *@path { static 'assets/css', @path; } # 从查询字符串获取内容 get -> 'search', :$term! { content 'application/json', do-search($term); }```
Hacker News | 最新 | 过往 | 评论 | 提问 | 展示 | 招聘 | 提交 | 登录
Cro – Raku (raku.org) 中优雅的响应式服务
由 giancarlostoro 发布于 2 小时前,9 分 | 隐藏 | 过往 | 收藏 | 1 条评论
shrubble 2 分钟前 [–]
我花了一会儿才想起 Raku 是 Perl 6 的后续版本,而 Perl 5 仍在维护中,尽管它已经演变成了一种非常不同的语言。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系方式
搜索:
LocalAI 开发了 18 个自定义 C/C++ 推理引擎,主要目的是为了避免 Python/PyTorch 依赖带来的臃肿和复杂性。通过将庞大的 Python 环境替换为自包含、轻量级的二进制文件(通常小于 100 MiB),LocalAI 在保持与 vLLM 和 ONNX 等行业标准框架近乎完美输出一致性的同时,显著减少了内存占用并缩短了安装时间。 开发过程优先考虑准确性而非原始速度:引擎的构建首先是将权重转换为 GGUF 格式,针对参考张量执行严格的组件级测试,仅在验证输出一致性后才进行优化。虽然这些移植版通过消除解释器开销和冗余计算,在 CPU 上往往优于 Python 等效版本,但在 GPU 上仍与 cuDNN 等成熟内核保持同等性能。 LocalAI 仅在 Python 依赖受限或不存在 C++ 实现的特殊用例中才使用这些自定义移植版。对于像 `llama.cpp` 或 `vLLM` 这样快速迭代的项目,团队仍会继续使用现有的封装。最终,这种方法提供了一个可预测、可移植且高效的推理栈,同时兼顾了生产部署所需的可靠性。
```Hacker News
新 | 往期 | 评论 | 提问 | 展示 | 招聘 | 提交
登录
为什么我们要自研 C 和 C++ 推理引擎 (localai.io)
11 个积分 由 eatonphil 于 1 小时前发布 | 隐藏 | 往期 | 收藏 | 3 条评论
帮助
dennis16384 7 分钟前 | 下一条 [–]
我在 Model2Vec 静态嵌入和 NER 推理(均为 GGUF,针对 WASM 编译)上也取得了类似的成功,从 ONNX Runtime 移植到了纯 C。Wasm 大小从 30Mb 减小到 300kb,速度提升了 1.5 倍。为了性能或分发包大小,这绝对是值得的。
回复
stephbook 30 分钟前 | 上一条 | 下一条 [–]
应该先从写好你自己的博客文章开始。
回复
nnevatie 8 分钟前 | 父评论 | 下一条 [–]
我也是这么想的。读这些充斥着 AI 生成内容的文章真的很累,它们看起来全都“千篇一律”。
回复
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索: ```
阿里巴巴发布了其迄今为止最先进的模型 **Qwen3.8-Max**,该模型具备更强的推理能力,并支持可调节的“推理工作量”设置,以平衡速度与成本。值得注意的是,该公司宣布将于下周发布该“Max级”模型的开放权重,这是其顶级系列模型首次采取这一举措。
Hacker News 上的讨论重点包括:
* **性能:** 许多用户认为 Qwen 系列是目前最好的本地模型之一,常将其置于付费订阅服务(如 Claude)之上。
* **定价:** 官方定价为输入每百万 tokens 2.0 美元,输出每百万 tokens 6.0 美元。
* **社区质疑:** 用户对有关“自我进化”能力的营销进行了辩论;有人指出,尽管这些模型是高效的辅助工具,但仍需人工监管。
* **市场背景:** 评论者担心美国 AI 实验室通过“末日论和恐吓策略”来确立市场主导地位,同时称赞 Qwen 和 DeepSeek 等模型的高性价比是用户的福音。
总体而言,社区对即将发布的开放权重版本充满热情,将其视为本地 AI 发展的一个重要里程碑。
前苹果工程师托比·博德曼(Toby Boardman)提起诉讼,指控公司因他提出隐私顾虑而于2024年6月将其非法解雇。博德曼声称,他发现苹果在未经客户许可的情况下,向AT&T共享了包括序列号和IMEI数据在内的敏感客户标识符。 诉状显示,博德曼曾多次向其主管梅格·费舍尔(Meg Fisher)反映这些未经授权的数据传输问题,但据称费舍尔对此不予理会,并要求他“别再找麻烦”。在博德曼拒绝执行这些违规请求后,他受到了内部压力。在因焦虑症和强迫症休了一个月病假后,博德曼本以为会参加关于工作调整的会议,不料却被解雇。苹果公司则将解雇原因归结为绩效问题。 尽管该诉讼指控苹果存在非法处理数据及打击报复行为,且定于2027年11月进行陪审团审判,但目前尚无法院对这些指控予以证实。苹果已正式否认相关指控,坚称解雇是出于合理的商业考量。目前,公司内部政策文件及争议数据传输的相关证据尚未公开。
有些想法值得多花点时间。手写能让我们慢下来。这是一个进行深度思考的地方,没有算法推送,每个博客都有 RSS,没有点赞。只有你亲自撰写的页面,如实发布。看看页面吧。或许,互联网可以多一点人情味。在 handwritten.blog 开始你的手写博客。
抱歉。
每年9月9日是国际数独日,旨在纪念这一全球现象的演变。尽管其渊源可追溯至18世纪的“拉丁方阵”,但现代数独游戏于1979年以“数字位”(Number Place)之名问世,推测由美国建筑师霍华德·加恩斯(Howard Garns)所创。 1984年,日本出版商Nikoli将其命名为“数独”(意为“数字必须为单个”),这一游戏由此获得了标志性的身份。Nikoli通过增加对称性和限制初始数字数量,规范了这一挑战;而他们决定不在海外对该名称注册商标,也助推了数独的国际化推广。 2004年,韦恩·古尔德(Wayne Gould)将每日数独引入伦敦的《泰晤士报》,引发了该游戏的全球热潮。数独规则简单且不受语言限制,使其能够跨越国界,成为数百万人的日常习惯。自2006年首届世界数独锦标赛举办以来,这一爱好已发展出多种变体,但其核心魅力始终如一:这是一种纯粹的逻辑演练,每一步推理都基于证明而非猜测。如今,数独已成为一种共享的、通用的演绎语言,持续吸引着全世界的玩家。
```Hacker News最新 | 往日 | 评论 | 提问 | 展示 | 工作 | 提交登录数独的可玩历史 (doku.su)6 分,作者:bouiboui,2 小时前 | 隐藏 | 往日 | 收藏 | 讨论 帮助
考虑申请 YC 2026 年秋季批次!申请截止日期为 7 月 27 日。
准则 | 常见问题 | 列表 | API | 安全 | 法律 | 申请 YC | 联系
搜索: ```
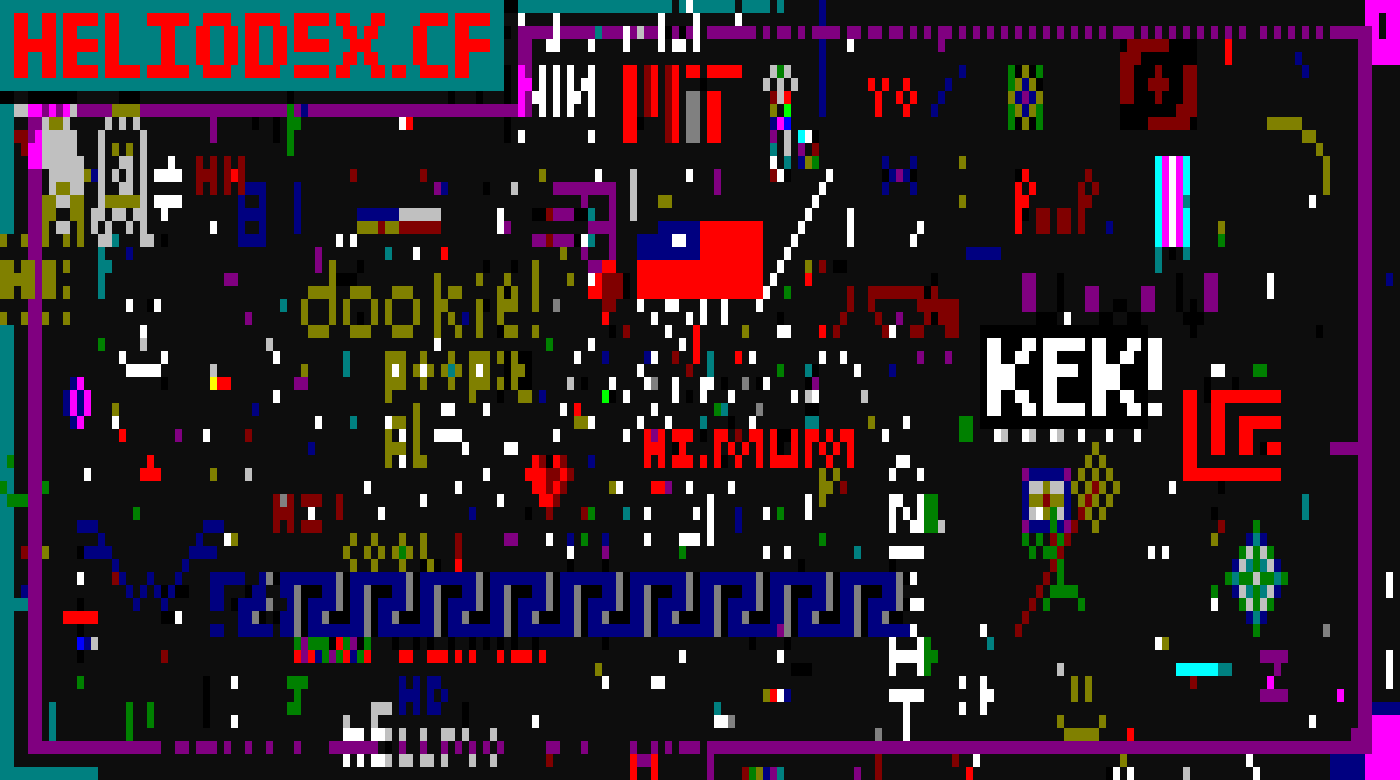 ssh.place:通过 SSH 进行 r/place 创作
一个画布。每个人都通过 SSH 在上面绘画。无需账户,无需安装 · 200×60 格 · 每 15 秒可放置一次
绘画地址:ssh ssh.place
任何 SSH 密钥均可使用。无需注册。
17 人在线 · 已绘制 594/12000 格
使用方向键、wasd 或 hjkl 移动光标。
画布比你的终端宽,请滚动以平移。shift+←/→ 可整屏跳转。
使用 0 到 9 选择颜色。tab 键可在 16 种颜色间切换。空格键放置该颜色的实心块。
现在等待 15 秒,和其他人一样。
此画布仅限颜色。服务器会拒绝任何包含字符的内容,因此你无法在此处输入文字。请画点什么。
你的冷却时间与 SSH 密钥绑定,因此重新连接不会重置冷却。
此页面仅用于查看画布。画布内容仅通过 SSH 更改,其他地方无法更改。
画布 · 统计 · png · 开源
ssh.place:通过 SSH 进行 r/place 创作
一个画布。每个人都通过 SSH 在上面绘画。无需账户,无需安装 · 200×60 格 · 每 15 秒可放置一次
绘画地址:ssh ssh.place
任何 SSH 密钥均可使用。无需注册。
17 人在线 · 已绘制 594/12000 格
使用方向键、wasd 或 hjkl 移动光标。
画布比你的终端宽,请滚动以平移。shift+←/→ 可整屏跳转。
使用 0 到 9 选择颜色。tab 键可在 16 种颜色间切换。空格键放置该颜色的实心块。
现在等待 15 秒,和其他人一样。
此画布仅限颜色。服务器会拒绝任何包含字符的内容,因此你无法在此处输入文字。请画点什么。
你的冷却时间与 SSH 密钥绑定,因此重新连接不会重置冷却。
此页面仅用于查看画布。画布内容仅通过 SSH 更改,其他地方无法更改。
画布 · 统计 · png · 开源
一个新的“Show HN”项目 **ssh.place** 是一个基于 SSH 的协作式终端艺术/网格工具。
开发者 jeninh 表示,该项目结合了 SSH 密钥、IP 追踪和设备指纹技术来管理用户冷却时间并防止滥用。社区反馈褒贬不一但颇具建设性:用户指出了彩色单元格上光标可见性的问题,并针对 SSH 代理转发提出了安全警告。
该项目引起了 SSH 应用领域其他开发者的兴趣,评论者提到了诸如 `late.sh` 和 `shellbox.dev` 等类似项目。创建者承认该项目尚处于早期实验阶段,但如果平台流量激增,他愿意实施更稳健的反机器人措施。