在谷歌削减了他计划扑克工具的广告收入后,作者意识到问题不在于技术漏洞,而在于内容。由于他的应用程序主要由没有编辑文本的界面“房间”组成,谷歌的算法将这些页面判定为“低价值”,导致“智能定价”调整,使他的收入减半。 作者没有徒劳地去提交支持工单,而是将这一情况视为出版商面临的挑战。他取消了对那些重界面房间页面的索引,并投资建立了一个内容库。通过添加详尽的指南、客观的工具对比以及个人“关于”页面,他向搜索引擎表明该网站是一个合法的实体,而非内容农场。他还优化了着陆页标题,这使他的点击率从 0.2% 提升到了 15%。 一年后,收入和流量都在稳步回升。结论是:如果你通过广告获利,你就是一名出版商。广告网络会惩罚稀薄的内容,因此解决方案是提供真正的价值。身份认同、透明度和以搜索意图为核心的内容不仅仅是修饰——它们是平台生存的必要信号。
每日HackerNews RSS
抱歉。
 该项目是一个轻量级的即时模式 UI 库,由约 1,100 行 ANSI C 代码编写而成。它专为简洁性和可移植性而设计,在固定内存区域内运行,无需动态分配内存。
该库提供了必要的控件(包括窗口、按钮、滑块和文本输入框),并具备一套简明的布局系统。值得注意的是,它与渲染器无关;其本身不执行任何绘制操作,而是要求用户自行处理渲染指令和输入处理。这种模块化设计使开发人员能够轻松将其与任何现有的渲染系统集成,或实现自定义控件。
该项目遵循“保持简单”的哲学,倾向于极简主义的基础架构,而非功能堆砌。它以 MIT 许可证发布,可自由重新分发和修改。详细的文档和使用示例可在仓库中获取。
该项目是一个轻量级的即时模式 UI 库,由约 1,100 行 ANSI C 代码编写而成。它专为简洁性和可移植性而设计,在固定内存区域内运行,无需动态分配内存。
该库提供了必要的控件(包括窗口、按钮、滑块和文本输入框),并具备一套简明的布局系统。值得注意的是,它与渲染器无关;其本身不执行任何绘制操作,而是要求用户自行处理渲染指令和输入处理。这种模块化设计使开发人员能够轻松将其与任何现有的渲染系统集成,或实现自定义控件。
该项目遵循“保持简单”的哲学,倾向于极简主义的基础架构,而非功能堆砌。它以 MIT 许可证发布,可自由重新分发和修改。详细的文档和使用示例可在仓库中获取。
抱歉。
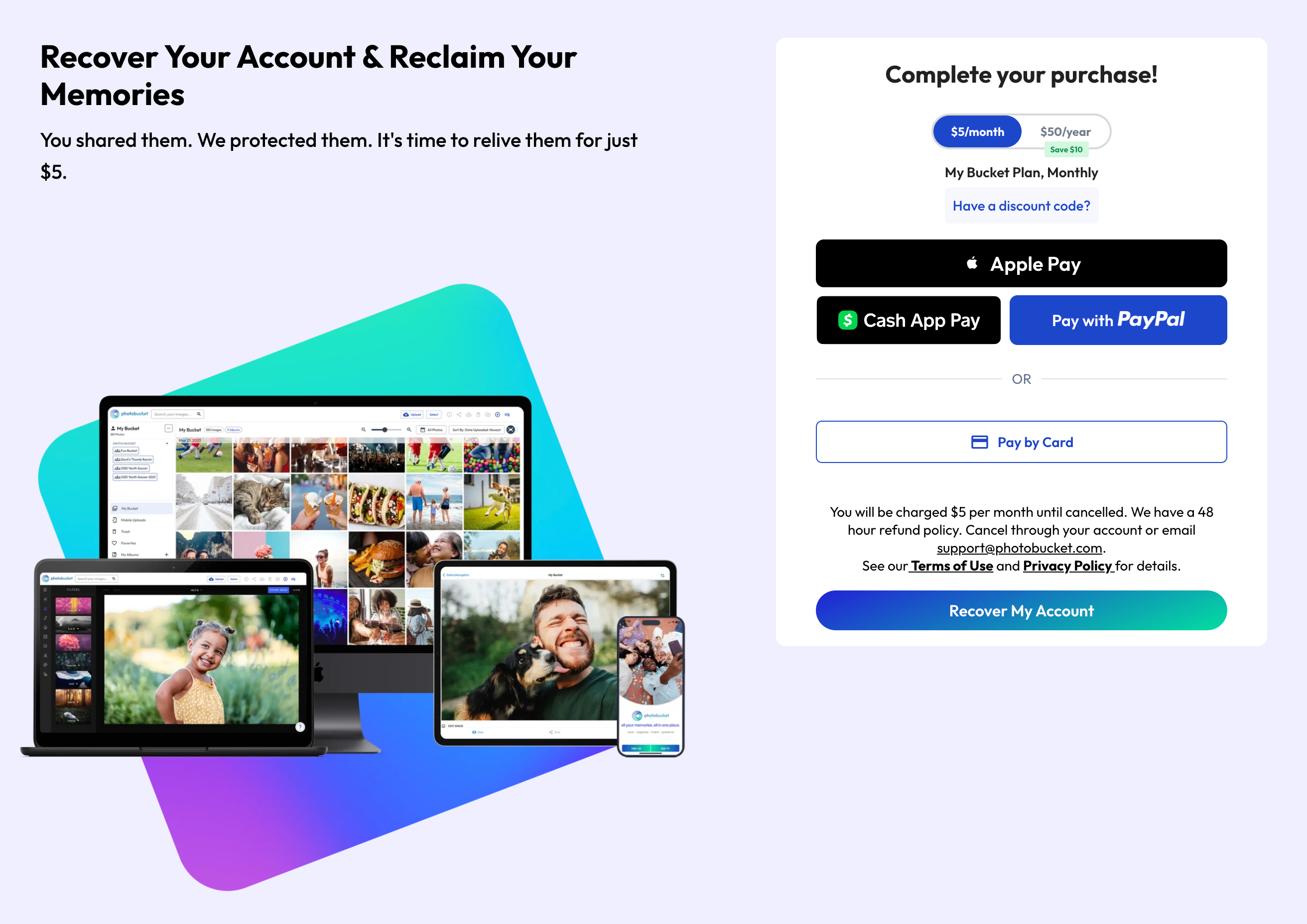 出于怀旧,作者试图从一个废弃的 Photobucket 账户中找回儿时的照片。登录后,他们发现该平台已对用户内容设置了付费墙,要求每月支付 5 美元的订阅费。尽管作者对这种掠夺性的“重拾回忆”策略感到厌恶,但出于对账户内容的好奇,最终还是屈服了。
在不情愿地支付了订阅费后,作者发现账户里空空如也。更糟糕的是,他们后知后觉地意识到,自己忽略了关于交易不可退款的重要脚注。最终,作者不仅钱财尽失,还遭遇了毫无价值的服务。这个故事警示人们,一些公司正利用用户的怀旧心理,通过欺骗性的订阅模式牟取暴利。
出于怀旧,作者试图从一个废弃的 Photobucket 账户中找回儿时的照片。登录后,他们发现该平台已对用户内容设置了付费墙,要求每月支付 5 美元的订阅费。尽管作者对这种掠夺性的“重拾回忆”策略感到厌恶,但出于对账户内容的好奇,最终还是屈服了。
在不情愿地支付了订阅费后,作者发现账户里空空如也。更糟糕的是,他们后知后觉地意识到,自己忽略了关于交易不可退款的重要脚注。最终,作者不仅钱财尽失,还遭遇了毫无价值的服务。这个故事警示人们,一些公司正利用用户的怀旧心理,通过欺骗性的订阅模式牟取暴利。
我们正在验证您的浏览器。网站所有者?请点击此处修复。 Vercel 安全检查点 | sin1::1781701413-dIMYqi9xOJdmVHlqR69O2CFre8zprMee 请启用 JavaScript 以继续。 Vercel 安全检查点 | sin1::1781701413-dIMYqi9xOJdmVHlqR69O2CFre8zprMee
近期 Hacker News 上关于图像压缩的讨论汇集了多种观点,从对现代编解码器的技术争论到对特定格式的偏好,内容十分广泛。
主要结论包括:
* **格式对比:** 虽然 JPEG 和 PNG 等传统格式依然是行业标准,但参与者认为 **AVIF** 凭借其优异的压缩性能和近期实现的浏览器通用支持,目前处于领先地位。**JPEG XL** 也因其多功能性(支持 HDR 和无损模式)以及在专业 RAW 工作流中的应用而受到赞誉,但其能否被主流广泛采用仍不明朗。
* **速度与简洁性:** **QOI** 格式因其简洁性和令人印象深刻的“速度与压缩比”而受到好评,可作为特定使用场景下的轻量级替代方案。
* **行业趋势:** 讨论探讨了计算开销与存储效率之间的权衡,并指出 AVIF 等编码器提供可调节的“工作量(effort)”设置,以平衡这些需求。
* **社区观点:** 用户就新格式的必要性展开了辩论;一些人优先考虑兼容性和通用支持,而另一些人则主张推动新格式的普及,以从大幅降低的带宽和存储成本中受益。
总的来说,此次讨论突显了人们在不牺牲质量的前提下优化数字图像的共同兴趣。
互联网正遭受一场“人性危机”,74%的消费者认为过去十年里网络变得越来越没有人情味。用户在进行仅仅40分钟的合成交互后就会感到“机器人疲劳”,且61%的用户无法说出一个在信息传达中有效运用人工智能的品牌。 尽管经过了两年的巨额投入,AI品牌可见度仍是一个尚未被征服的领域。目前尚无行业领导者或标准化仪表盘来追踪品牌在AI生成答案中的呈现方式,企业只能在引用监测、SEO叠加和定制化工程解决方案组成的碎片化格局中摸索。 为了取得成功,品牌必须转变其网站策略,以同时服务于两个不同的目标: 1. **AI引擎:** 需要结构化、易于获取的内容,以实现准确引用。 2. **人类访问者:** 需要动态且有价值的体验,以使他们投入的时间变得值得。 目标在于超越肤浅的人工智能应用。首批成功将高质量的AI可发现性与深具人文关怀的数字体验相结合的公司,将定义互联网下一个时代的新标准。随着市场日趋成熟,那些能够证明其AI驱动流量商业价值的品牌,将确立其竞争优势。
60% 的美国消费者表示,品牌宣传中的“人工智能”(AI)不仅不能促进销售,反而是一种阻碍。这一观点在 Hacker News 社区引发了激烈讨论,凸显了企业战略与消费者体验之间严重的脱节。
引发这种抵触情绪的主要原因包括:
* **实施质量低劣:** 许多 AI 的应用——例如干扰性强的聊天机器人、家用电器中所谓的“智能”功能,以及毫无帮助的客服代理——被视为“劣质产品”。消费者认为这些功能只是为了削减成本或取悦投资者而进行的“打钩式”更新,而非真正解决问题。
* **非人性化:** AI 越来越多地与取消人工支持、裁员以及平庸、廉价的内容挂钩。许多用户认为,被迫与 AI 交互是对他们时间和自主权的“公然冒犯”。
* **营销脱节:** 消费者更看重功能而非营销热词。普遍共识是:如果一项功能具有真正的价值,就应该以其实用性进行宣传,而不是用背后的技术噱头来包装。
尽管一些精通技术的用户发现 AI 在某些特定领域有所助益,但大众普遍认为当前的“AI 优先”趋势是一种被过度炒作的企业战略,即以牺牲用户体验和可靠性为代价,换取基于热词的营销。
 “废弃及鲜为人知的机场”(Abandoned & Little-Known Airfields)由飞行员保罗·弗里曼(Paul Freeman)于1999年创建,是一个详尽的数字档案库,致力于记录美国全境50个州内已消失的航空遗址及其历史与奥秘。该项目涵盖了超过2800个机场的详细资料与影像,留存了这些曾经服务于航空界的地点所承载的独特遗产。
出于对航空历史的毕生热爱及对飞行安全的关注,弗里曼以独立、非商业的形式维护着这一综合性资源网站。该网站完全依靠访客捐赠而非广告维持运营,以确保其持续的运作与扩展。
2024年,该网站迎来了创立25周年。作为一个依赖公众贡献的动态资料库,作者鼓励航空爱好者们通过经济捐赠,或提供历史资料(如老照片、航空图表及机场名录)来支持该项目,共同为子孙后代保留这些历史故事。欲了解更多信息或进行贡献,请访问网站或直接与保罗·弗里曼联系。
“废弃及鲜为人知的机场”(Abandoned & Little-Known Airfields)由飞行员保罗·弗里曼(Paul Freeman)于1999年创建,是一个详尽的数字档案库,致力于记录美国全境50个州内已消失的航空遗址及其历史与奥秘。该项目涵盖了超过2800个机场的详细资料与影像,留存了这些曾经服务于航空界的地点所承载的独特遗产。
出于对航空历史的毕生热爱及对飞行安全的关注,弗里曼以独立、非商业的形式维护着这一综合性资源网站。该网站完全依靠访客捐赠而非广告维持运营,以确保其持续的运作与扩展。
2024年,该网站迎来了创立25周年。作为一个依赖公众贡献的动态资料库,作者鼓励航空爱好者们通过经济捐赠,或提供历史资料(如老照片、航空图表及机场名录)来支持该项目,共同为子孙后代保留这些历史故事。欲了解更多信息或进行贡献,请访问网站或直接与保罗·弗里曼联系。
“废弃与鲜为人知的机场”(Abandoned and Little-Known Airfields)网站是一个备受推崇、运营已久的数字档案馆,一直以来都深受 Hacker News 社区的喜爱。用户们最近分享了关于该网站的故事与怀旧之情,该网站记录了美国各地现已废弃的航空设施历史。
许多评论者对通用航空的衰落表示遗憾,并指出一旦小型机场被出售并进行开发——通常被住宅或太阳能发电场取代——它们就很难再恢复原貌。讨论涉及了维护这些空间所面临的挑战,包括监管障碍、高昂的成本以及来自邻居的噪音投诉。其他人则分享了个人经历,包括在旧跑道上学开车的记忆、家庭经营机场的故事,以及探索杂草丛生的历史遗迹时的兴奋感。
社区对该网站纯正的 20 世纪 90 年代风格设计大加赞赏,认为在充斥着华丽企业网页布局的时代,这种设计是一份令人耳目一新的“热爱之作”。参与者还表示,虽然互联网档案(Internet Archive)有助于保存此类网站,但这些存储库对于一项正面临被遗忘风险的日渐式微的爱好而言,是至关重要的历史记录。
```HTTP/1.1 200 OK Content-Type: text/csv Accept-Query: "application/jsonpath", "application/xslt+xml" Date: 2025年2月19日 周三, 17:10:01 GMT 年份, 总计, 拒绝, 核实, hdu, 上报 2000, 14, 0, 14, 0, 0 2001, 72, 1, 70, 1, 0 2002, 124, 8, 104, 12, 0 2003, 63, 0, 61, 2, 0 2004, 89, 1, 83, 5, 0 2005, 156, 10, 96, 50, 0 2006, 444, 54, 176, 214, 0 2007, 429, 48, 188, 193, 0 2008, 423, 52, 165, 206, 0 2009, 331, 39, 148, 144, 0 2010, 538, 80, 232, 222, 4 2011, 367, 47, 170, 150, 0 2012, 348, 54, 149, 145, 0 2013, 341, 61, 169, 106, 5 2014, 342, 73, 180, 72, 17 2015, 343, 79, 145, 89, 30 2016, 295, 46, 122, 82, 45 2017, 303, 46, 120, 84, 53 2018, 350, 61, 118, 98, 73 2019, 335, 47, 131, 94, 63 2020, 387, 68, 117, 123, 79 2021, 321, 44, 148, 63, 66 2022, 358, 37, 198, 40, 83 2023, 262, 38, 121, 33, 70 2024, 322, 33, 125, 23, 141 9999, 1, 0, 0, 1, 0```
RFC 10008 引入了 **QUERY**,这是一种新的 HTTP 方法,旨在允许使用带有请求体的请求,同时保持安全、幂等和可缓存性。
该提案旨在解决“大型查询”问题,即复杂的过滤器或庞大的数据集超出了 GET URL 的实际长度限制,且避免了将 POST 用于非变更操作所带来的语义缺陷。与 POST 不同,QUERY 方法明确向缓存、代理和浏览器表明该请求不会改变服务器状态,并且可以安全地重试。
**来自 Hacker News 讨论的要点包括:**
* **优点:** 标准化了需要大负载的只读请求的行为,相比 POST 实现了更好的缓存和自动重试。它还在数据检索和状态修改之间提供了更清晰的语义分离。
* **缺点/质疑:** 批评者认为这是一种“小题大做”的解决方案,需要 CDN、负载均衡器和浏览器的普遍采用才能生效。许多人建议为 GET 标准化请求体本来会更简单,但其他人指出,遗留的中间件通常会丢弃 GET 请求体。
* **实施:** 人们仍然担心,由于缺乏中间件基础设施的支持,它是否会像其他“已废弃”的方法一样遭受同样的命运。
GLM-5.2 (max) 是目前最智能的模型之一,但与同等规模的其他开源权重模型相比,价格非常昂贵。它的运行速度显著较快,但输出内容略显冗长。该模型支持文本输入与输出,并拥有 100 万 token 的上下文窗口。 在人工智能分析智能指数(Artificial Analysis Intelligence Index)中,GLM-5.2 (max) 得分为 51 分,远高于同类模型(平均分为 24 分)。在评估该指数时,它生成了 1.4 亿个 token,相较于 1.1 亿的平均水平,显得较为冗长。 GLM-5.2 (max) 的定价为每 100 万输入 token 1.40 美元(较贵,平均水平为 0.42 美元),每 100 万输出 token 4.40 美元(较贵,平均水平为 1.25 美元)。评估 GLM-5.2 (max) 的智能指数总成本为 867.88 美元。其运行速度为每秒 112 个 token,表现非常快(基准值为 61)。
抱歉。
 受 ElectroBOOM 的启发,这款由 ESP32 驱动的“电容闹钟”是一个费尽心思且带有戏谑性质的项目,旨在设定时间一到就触发一场戏剧性的电容爆炸。
**主要特性:**
* **硬件:** 配备 SSD1315 显示屏、三个电容插槽、USB-C/圆口电源输入,以及用于安全的 10 欧姆限流电阻。
* **连接性:** 支持 NTP 网络对时及基于网页的配置界面。
* **设计:** 紧凑的 72x74x36 毫米外形尺寸。
**操作与构建:**
固件通过 PlatformIO 进行管理。用户可以通过板载按钮或网页界面配置闹钟和设置。设计者指出,目前使用的线性稳压器发热量较大,建议未来改用降压转换器来优化热负载。
**警告:** 本项目涉及具有潜在危险的电气元件。电容爆炸具有破坏性并会产生有害烟雾,用户务必保持极度谨慎。为了达到“最佳”效果,项目建议使用没有顶部泄压槽的大型电容。
完整的文档(包括原理图、物料清单及外壳 CAD 文件)现已提供,供有意通过 JLCPCB 等服务进行制作的人员参考。本项目最初提交至 Hack Club Fallout 杂志。
受 ElectroBOOM 的启发,这款由 ESP32 驱动的“电容闹钟”是一个费尽心思且带有戏谑性质的项目,旨在设定时间一到就触发一场戏剧性的电容爆炸。
**主要特性:**
* **硬件:** 配备 SSD1315 显示屏、三个电容插槽、USB-C/圆口电源输入,以及用于安全的 10 欧姆限流电阻。
* **连接性:** 支持 NTP 网络对时及基于网页的配置界面。
* **设计:** 紧凑的 72x74x36 毫米外形尺寸。
**操作与构建:**
固件通过 PlatformIO 进行管理。用户可以通过板载按钮或网页界面配置闹钟和设置。设计者指出,目前使用的线性稳压器发热量较大,建议未来改用降压转换器来优化热负载。
**警告:** 本项目涉及具有潜在危险的电气元件。电容爆炸具有破坏性并会产生有害烟雾,用户务必保持极度谨慎。为了达到“最佳”效果,项目建议使用没有顶部泄压槽的大型电容。
完整的文档(包括原理图、物料清单及外壳 CAD 文件)现已提供,供有意通过 JLCPCB 等服务进行制作的人员参考。本项目最初提交至 Hack Club Fallout 杂志。
 美国的科研环境正经历一场破坏性的转型,其特征是大规模的预算削减、政治干预,以及对二战后支持基础研究的“社会契约”的背弃。
近期的一系列联邦举措——包括对美国国家航空航天局(NASA)和美国国立卫生研究院(NIH)等机构的剧烈裁减,以及施加意识形态的立场审查(如禁用“结构性种族主义”等术语)——已导致数千个研究项目被迫冻结或取消。由于官僚机构的不稳定性以及部门优先事项的改变,包括AXIS太空望远镜在内的重要任务已经夭折。
这种环境营造了一种恐惧氛围,引发了“人才流失”现象,许多科学家正考虑离开该国或完全放弃科研。在政治任命官员和硅谷利益集团的推动下,科研正向“学术资本主义”转型;这些势力更倾向于追求快速的颠覆,而非长期的探索性科学,即研究成果唯有具备即时的商业或经济效用才被视为有价值。
专家警告称,这种对基础研究的系统性“饥饿疗法”最终将危及未来的医学突破和国家创新。尽管许多科学家为了避免进一步的报复而保持沉默,但另一些人则认为,他们当下的新使命是“见证”并记录科学事业的侵蚀,以便未来追究责任。
美国的科研环境正经历一场破坏性的转型,其特征是大规模的预算削减、政治干预,以及对二战后支持基础研究的“社会契约”的背弃。
近期的一系列联邦举措——包括对美国国家航空航天局(NASA)和美国国立卫生研究院(NIH)等机构的剧烈裁减,以及施加意识形态的立场审查(如禁用“结构性种族主义”等术语)——已导致数千个研究项目被迫冻结或取消。由于官僚机构的不稳定性以及部门优先事项的改变,包括AXIS太空望远镜在内的重要任务已经夭折。
这种环境营造了一种恐惧氛围,引发了“人才流失”现象,许多科学家正考虑离开该国或完全放弃科研。在政治任命官员和硅谷利益集团的推动下,科研正向“学术资本主义”转型;这些势力更倾向于追求快速的颠覆,而非长期的探索性科学,即研究成果唯有具备即时的商业或经济效用才被视为有价值。
专家警告称,这种对基础研究的系统性“饥饿疗法”最终将危及未来的医学突破和国家创新。尽管许多科学家为了避免进一步的报复而保持沉默,但另一些人则认为,他们当下的新使命是“见证”并记录科学事业的侵蚀,以便未来追究责任。