互联网正遭受一场“人性危机”,74%的消费者认为过去十年里网络变得越来越没有人情味。用户在进行仅仅40分钟的合成交互后就会感到“机器人疲劳”,且61%的用户无法说出一个在信息传达中有效运用人工智能的品牌。 尽管经过了两年的巨额投入,AI品牌可见度仍是一个尚未被征服的领域。目前尚无行业领导者或标准化仪表盘来追踪品牌在AI生成答案中的呈现方式,企业只能在引用监测、SEO叠加和定制化工程解决方案组成的碎片化格局中摸索。 为了取得成功,品牌必须转变其网站策略,以同时服务于两个不同的目标: 1. **AI引擎:** 需要结构化、易于获取的内容,以实现准确引用。 2. **人类访问者:** 需要动态且有价值的体验,以使他们投入的时间变得值得。 目标在于超越肤浅的人工智能应用。首批成功将高质量的AI可发现性与深具人文关怀的数字体验相结合的公司,将定义互联网下一个时代的新标准。随着市场日趋成熟,那些能够证明其AI驱动流量商业价值的品牌,将确立其竞争优势。
每日HackerNews RSS
60% 的美国消费者表示,品牌宣传中的“人工智能”(AI)不仅不能促进销售,反而是一种阻碍。这一观点在 Hacker News 社区引发了激烈讨论,凸显了企业战略与消费者体验之间严重的脱节。
引发这种抵触情绪的主要原因包括:
* **实施质量低劣:** 许多 AI 的应用——例如干扰性强的聊天机器人、家用电器中所谓的“智能”功能,以及毫无帮助的客服代理——被视为“劣质产品”。消费者认为这些功能只是为了削减成本或取悦投资者而进行的“打钩式”更新,而非真正解决问题。
* **非人性化:** AI 越来越多地与取消人工支持、裁员以及平庸、廉价的内容挂钩。许多用户认为,被迫与 AI 交互是对他们时间和自主权的“公然冒犯”。
* **营销脱节:** 消费者更看重功能而非营销热词。普遍共识是:如果一项功能具有真正的价值,就应该以其实用性进行宣传,而不是用背后的技术噱头来包装。
尽管一些精通技术的用户发现 AI 在某些特定领域有所助益,但大众普遍认为当前的“AI 优先”趋势是一种被过度炒作的企业战略,即以牺牲用户体验和可靠性为代价,换取基于热词的营销。
 “废弃及鲜为人知的机场”(Abandoned & Little-Known Airfields)由飞行员保罗·弗里曼(Paul Freeman)于1999年创建,是一个详尽的数字档案库,致力于记录美国全境50个州内已消失的航空遗址及其历史与奥秘。该项目涵盖了超过2800个机场的详细资料与影像,留存了这些曾经服务于航空界的地点所承载的独特遗产。
出于对航空历史的毕生热爱及对飞行安全的关注,弗里曼以独立、非商业的形式维护着这一综合性资源网站。该网站完全依靠访客捐赠而非广告维持运营,以确保其持续的运作与扩展。
2024年,该网站迎来了创立25周年。作为一个依赖公众贡献的动态资料库,作者鼓励航空爱好者们通过经济捐赠,或提供历史资料(如老照片、航空图表及机场名录)来支持该项目,共同为子孙后代保留这些历史故事。欲了解更多信息或进行贡献,请访问网站或直接与保罗·弗里曼联系。
“废弃及鲜为人知的机场”(Abandoned & Little-Known Airfields)由飞行员保罗·弗里曼(Paul Freeman)于1999年创建,是一个详尽的数字档案库,致力于记录美国全境50个州内已消失的航空遗址及其历史与奥秘。该项目涵盖了超过2800个机场的详细资料与影像,留存了这些曾经服务于航空界的地点所承载的独特遗产。
出于对航空历史的毕生热爱及对飞行安全的关注,弗里曼以独立、非商业的形式维护着这一综合性资源网站。该网站完全依靠访客捐赠而非广告维持运营,以确保其持续的运作与扩展。
2024年,该网站迎来了创立25周年。作为一个依赖公众贡献的动态资料库,作者鼓励航空爱好者们通过经济捐赠,或提供历史资料(如老照片、航空图表及机场名录)来支持该项目,共同为子孙后代保留这些历史故事。欲了解更多信息或进行贡献,请访问网站或直接与保罗·弗里曼联系。
“废弃与鲜为人知的机场”(Abandoned and Little-Known Airfields)网站是一个备受推崇、运营已久的数字档案馆,一直以来都深受 Hacker News 社区的喜爱。用户们最近分享了关于该网站的故事与怀旧之情,该网站记录了美国各地现已废弃的航空设施历史。
许多评论者对通用航空的衰落表示遗憾,并指出一旦小型机场被出售并进行开发——通常被住宅或太阳能发电场取代——它们就很难再恢复原貌。讨论涉及了维护这些空间所面临的挑战,包括监管障碍、高昂的成本以及来自邻居的噪音投诉。其他人则分享了个人经历,包括在旧跑道上学开车的记忆、家庭经营机场的故事,以及探索杂草丛生的历史遗迹时的兴奋感。
社区对该网站纯正的 20 世纪 90 年代风格设计大加赞赏,认为在充斥着华丽企业网页布局的时代,这种设计是一份令人耳目一新的“热爱之作”。参与者还表示,虽然互联网档案(Internet Archive)有助于保存此类网站,但这些存储库对于一项正面临被遗忘风险的日渐式微的爱好而言,是至关重要的历史记录。
```HTTP/1.1 200 OK Content-Type: text/csv Accept-Query: "application/jsonpath", "application/xslt+xml" Date: 2025年2月19日 周三, 17:10:01 GMT 年份, 总计, 拒绝, 核实, hdu, 上报 2000, 14, 0, 14, 0, 0 2001, 72, 1, 70, 1, 0 2002, 124, 8, 104, 12, 0 2003, 63, 0, 61, 2, 0 2004, 89, 1, 83, 5, 0 2005, 156, 10, 96, 50, 0 2006, 444, 54, 176, 214, 0 2007, 429, 48, 188, 193, 0 2008, 423, 52, 165, 206, 0 2009, 331, 39, 148, 144, 0 2010, 538, 80, 232, 222, 4 2011, 367, 47, 170, 150, 0 2012, 348, 54, 149, 145, 0 2013, 341, 61, 169, 106, 5 2014, 342, 73, 180, 72, 17 2015, 343, 79, 145, 89, 30 2016, 295, 46, 122, 82, 45 2017, 303, 46, 120, 84, 53 2018, 350, 61, 118, 98, 73 2019, 335, 47, 131, 94, 63 2020, 387, 68, 117, 123, 79 2021, 321, 44, 148, 63, 66 2022, 358, 37, 198, 40, 83 2023, 262, 38, 121, 33, 70 2024, 322, 33, 125, 23, 141 9999, 1, 0, 0, 1, 0```
RFC 10008 引入了 **QUERY**,这是一种新的 HTTP 方法,旨在允许使用带有请求体的请求,同时保持安全、幂等和可缓存性。
该提案旨在解决“大型查询”问题,即复杂的过滤器或庞大的数据集超出了 GET URL 的实际长度限制,且避免了将 POST 用于非变更操作所带来的语义缺陷。与 POST 不同,QUERY 方法明确向缓存、代理和浏览器表明该请求不会改变服务器状态,并且可以安全地重试。
**来自 Hacker News 讨论的要点包括:**
* **优点:** 标准化了需要大负载的只读请求的行为,相比 POST 实现了更好的缓存和自动重试。它还在数据检索和状态修改之间提供了更清晰的语义分离。
* **缺点/质疑:** 批评者认为这是一种“小题大做”的解决方案,需要 CDN、负载均衡器和浏览器的普遍采用才能生效。许多人建议为 GET 标准化请求体本来会更简单,但其他人指出,遗留的中间件通常会丢弃 GET 请求体。
* **实施:** 人们仍然担心,由于缺乏中间件基础设施的支持,它是否会像其他“已废弃”的方法一样遭受同样的命运。
GLM-5.2 (max) 是目前最智能的模型之一,但与同等规模的其他开源权重模型相比,价格非常昂贵。它的运行速度显著较快,但输出内容略显冗长。该模型支持文本输入与输出,并拥有 100 万 token 的上下文窗口。 在人工智能分析智能指数(Artificial Analysis Intelligence Index)中,GLM-5.2 (max) 得分为 51 分,远高于同类模型(平均分为 24 分)。在评估该指数时,它生成了 1.4 亿个 token,相较于 1.1 亿的平均水平,显得较为冗长。 GLM-5.2 (max) 的定价为每 100 万输入 token 1.40 美元(较贵,平均水平为 0.42 美元),每 100 万输出 token 4.40 美元(较贵,平均水平为 1.25 美元)。评估 GLM-5.2 (max) 的智能指数总成本为 867.88 美元。其运行速度为每秒 112 个 token,表现非常快(基准值为 61)。
抱歉。
 受 ElectroBOOM 的启发,这款由 ESP32 驱动的“电容闹钟”是一个费尽心思且带有戏谑性质的项目,旨在设定时间一到就触发一场戏剧性的电容爆炸。
**主要特性:**
* **硬件:** 配备 SSD1315 显示屏、三个电容插槽、USB-C/圆口电源输入,以及用于安全的 10 欧姆限流电阻。
* **连接性:** 支持 NTP 网络对时及基于网页的配置界面。
* **设计:** 紧凑的 72x74x36 毫米外形尺寸。
**操作与构建:**
固件通过 PlatformIO 进行管理。用户可以通过板载按钮或网页界面配置闹钟和设置。设计者指出,目前使用的线性稳压器发热量较大,建议未来改用降压转换器来优化热负载。
**警告:** 本项目涉及具有潜在危险的电气元件。电容爆炸具有破坏性并会产生有害烟雾,用户务必保持极度谨慎。为了达到“最佳”效果,项目建议使用没有顶部泄压槽的大型电容。
完整的文档(包括原理图、物料清单及外壳 CAD 文件)现已提供,供有意通过 JLCPCB 等服务进行制作的人员参考。本项目最初提交至 Hack Club Fallout 杂志。
受 ElectroBOOM 的启发,这款由 ESP32 驱动的“电容闹钟”是一个费尽心思且带有戏谑性质的项目,旨在设定时间一到就触发一场戏剧性的电容爆炸。
**主要特性:**
* **硬件:** 配备 SSD1315 显示屏、三个电容插槽、USB-C/圆口电源输入,以及用于安全的 10 欧姆限流电阻。
* **连接性:** 支持 NTP 网络对时及基于网页的配置界面。
* **设计:** 紧凑的 72x74x36 毫米外形尺寸。
**操作与构建:**
固件通过 PlatformIO 进行管理。用户可以通过板载按钮或网页界面配置闹钟和设置。设计者指出,目前使用的线性稳压器发热量较大,建议未来改用降压转换器来优化热负载。
**警告:** 本项目涉及具有潜在危险的电气元件。电容爆炸具有破坏性并会产生有害烟雾,用户务必保持极度谨慎。为了达到“最佳”效果,项目建议使用没有顶部泄压槽的大型电容。
完整的文档(包括原理图、物料清单及外壳 CAD 文件)现已提供,供有意通过 JLCPCB 等服务进行制作的人员参考。本项目最初提交至 Hack Club Fallout 杂志。
 美国的科研环境正经历一场破坏性的转型,其特征是大规模的预算削减、政治干预,以及对二战后支持基础研究的“社会契约”的背弃。
近期的一系列联邦举措——包括对美国国家航空航天局(NASA)和美国国立卫生研究院(NIH)等机构的剧烈裁减,以及施加意识形态的立场审查(如禁用“结构性种族主义”等术语)——已导致数千个研究项目被迫冻结或取消。由于官僚机构的不稳定性以及部门优先事项的改变,包括AXIS太空望远镜在内的重要任务已经夭折。
这种环境营造了一种恐惧氛围,引发了“人才流失”现象,许多科学家正考虑离开该国或完全放弃科研。在政治任命官员和硅谷利益集团的推动下,科研正向“学术资本主义”转型;这些势力更倾向于追求快速的颠覆,而非长期的探索性科学,即研究成果唯有具备即时的商业或经济效用才被视为有价值。
专家警告称,这种对基础研究的系统性“饥饿疗法”最终将危及未来的医学突破和国家创新。尽管许多科学家为了避免进一步的报复而保持沉默,但另一些人则认为,他们当下的新使命是“见证”并记录科学事业的侵蚀,以便未来追究责任。
美国的科研环境正经历一场破坏性的转型,其特征是大规模的预算削减、政治干预,以及对二战后支持基础研究的“社会契约”的背弃。
近期的一系列联邦举措——包括对美国国家航空航天局(NASA)和美国国立卫生研究院(NIH)等机构的剧烈裁减,以及施加意识形态的立场审查(如禁用“结构性种族主义”等术语)——已导致数千个研究项目被迫冻结或取消。由于官僚机构的不稳定性以及部门优先事项的改变,包括AXIS太空望远镜在内的重要任务已经夭折。
这种环境营造了一种恐惧氛围,引发了“人才流失”现象,许多科学家正考虑离开该国或完全放弃科研。在政治任命官员和硅谷利益集团的推动下,科研正向“学术资本主义”转型;这些势力更倾向于追求快速的颠覆,而非长期的探索性科学,即研究成果唯有具备即时的商业或经济效用才被视为有价值。
专家警告称,这种对基础研究的系统性“饥饿疗法”最终将危及未来的医学突破和国家创新。尽管许多科学家为了避免进一步的报复而保持沉默,但另一些人则认为,他们当下的新使命是“见证”并记录科学事业的侵蚀,以便未来追究责任。
 Z ai 的 **GLM-5.2** 已成为人工智能分析指数(Artificial Analysis Intelligence Index)中领先的开源权重模型,得分为 51 分。尽管其架构与前代产品(GLM-5.1)保持相同的 744B 总参数量/40B 激活参数量,但其性能仍有显著提升,尤其是在科学推理方面,关键评估指标提升了多达 16 分。
主要亮点包括:
* **性能:** 在智能指数(Intelligence Index)和 GDPval-AA v2 评估中,该模型均优于 MiniMax-M3 和 DeepSeek V4 Pro 等竞争对手,并可与 GPT-5.5 等专有模型相媲美。
* **效率:** 虽然单任务成本高于部分同类产品,但 GLM-5.2 在“智能与成本”的帕累托前沿上占据一席之地,以具有竞争力的价格提供了高性能表现。
* **技术升级:** 该模型将上下文窗口从 200K 扩展至 1M Token,并展现出更高的推理密度,单任务输出 Token 达 43k。
* **可用性:** 该模型以 MIT 许可证发布,可通过 Z ai 的 API 及众多第三方提供商获取。
总而言之,GLM-5.2 代表了开源权重模型能力的重大飞跃,在先进的智能体性能、更高的推理准确度以及更低的幻觉率之间实现了平衡。
Z ai 的 **GLM-5.2** 已成为人工智能分析指数(Artificial Analysis Intelligence Index)中领先的开源权重模型,得分为 51 分。尽管其架构与前代产品(GLM-5.1)保持相同的 744B 总参数量/40B 激活参数量,但其性能仍有显著提升,尤其是在科学推理方面,关键评估指标提升了多达 16 分。
主要亮点包括:
* **性能:** 在智能指数(Intelligence Index)和 GDPval-AA v2 评估中,该模型均优于 MiniMax-M3 和 DeepSeek V4 Pro 等竞争对手,并可与 GPT-5.5 等专有模型相媲美。
* **效率:** 虽然单任务成本高于部分同类产品,但 GLM-5.2 在“智能与成本”的帕累托前沿上占据一席之地,以具有竞争力的价格提供了高性能表现。
* **技术升级:** 该模型将上下文窗口从 200K 扩展至 1M Token,并展现出更高的推理密度,单任务输出 Token 达 43k。
* **可用性:** 该模型以 MIT 许可证发布,可通过 Z ai 的 API 及众多第三方提供商获取。
总而言之,GLM-5.2 代表了开源权重模型能力的重大飞跃,在先进的智能体性能、更高的推理准确度以及更低的幻觉率之间实现了平衡。
**GLM-5.2** 的发布在 Hacker News 上引发了热烈讨论,用户将其定位为一款强大的“前沿级”开放权重模型。许多开发者认为,它不仅成本更低,而且是 Claude Opus 4.8 和 GPT-5.5 等行业领先模型的有力替代方案,尤其是在代码编写任务中。
**讨论要点如下:**
* **性能与效率:** 用户反映,虽然 GLM-5.2 能力出众,但其默认的“最大努力”(Max Effort)推理模式会消耗大量 Token 且运行缓慢。在“高”效率模式下运行,往往能以显著降低的成本获得相当的效果。
* **“前沿”差距:** 尽管有人称其为“颠覆性变革”,但也有人认为在复杂的长程任务中,它仍略逊于 GPT-5.5 和 Claude Opus。争议的一个主要焦点在于它缺乏多模态(视觉)能力,而这目前仍是顶级模型的标配。
* **可访问性与基础设施:** 一个反复出现的话题是自托管或使用第三方 API 存在的摩擦。虽然“开放权重”在理论上提供了隐私和自主权,但大型模型对硬件的高要求,以及新兴提供商的可靠性问题,导致部分用户仍倾向于使用 Anthropic 或 OpenAI 提供的受补贴托管服务。
* **市场情绪:** 该讨论串反映了围绕 AI“军备竞赛”的日益激烈的辩论,许多人注意到,中国实验室正在迅速缩小与美国前沿模型之间的差距。
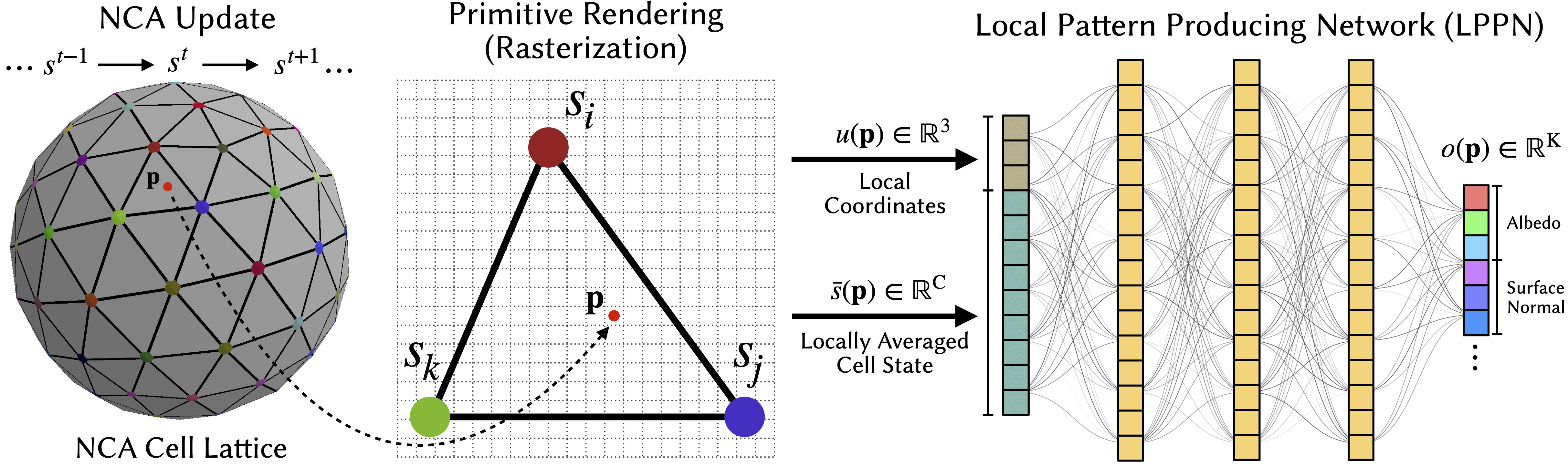 NCA 在粗糙的单元网格(本例中为网格顶点)上运行。中心:三角形图元内的一个采样点 \(\Point\)(红点),其顶点对应于 NCA 单元 \(\State_i,\,\State_j,\,\State_k\)。局部坐标 \(u(\Point)\) 表示该点在图元内的位置,而局部平均单元状态 \(\bar{\State}(\Point)\) 则通过对周围单元状态进行插值获得。右侧:局部模式生成网络(LPPN),即一个共享的轻量级 MLP,它接收 \((\bar{\State}(\Point), u(\Point))\) 作为输入,并输出点 \(\Point\) 处的颜色和表面法线等目标属性。NCA 和 LPPN 采用端到端方式联合训练。通过下方交互式可视化演示,可以查看粗糙的 NCA 单元状态以及 LPPN 生成的输出。
NCA 在粗糙的单元网格(本例中为网格顶点)上运行。中心:三角形图元内的一个采样点 \(\Point\)(红点),其顶点对应于 NCA 单元 \(\State_i,\,\State_j,\,\State_k\)。局部坐标 \(u(\Point)\) 表示该点在图元内的位置,而局部平均单元状态 \(\bar{\State}(\Point)\) 则通过对周围单元状态进行插值获得。右侧:局部模式生成网络(LPPN),即一个共享的轻量级 MLP,它接收 \((\bar{\State}(\Point), u(\Point))\) 作为输入,并输出点 \(\Point\) 处的颜色和表面法线等目标属性。NCA 和 LPPN 采用端到端方式联合训练。通过下方交互式可视化演示,可以查看粗糙的 NCA 单元状态以及 LPPN 生成的输出。
抱歉。
退休一年后,作者将全部时间投入到了 NetNewsWire 的现代化改造中,专注于深层的底层改进,而非企业股东利益。在过去的一年中,该项目进行了 2,188 次代码提交,旨在偿还技术债务并优化性能。 主要成就包括采用 Swift 结构化并发、将旧版 Objective-C 代码迁移至 Swift,以及实现重要的 UI 更新。开发团队优先考虑了系统优化,例如修复崩溃、降低电池和内存消耗,并提升了本地化能力。作者还引入了更好的诊断工具,为用户提供透明的应用活动洞察,这大幅降低了支持工作量。 作者认可了这一工作的协作性质,并强调了 Stuart Breckenridge 等人的贡献。虽然底层工作仍在继续,但该应用目前已处于更加稳定且易于维护的状态。展望未来,这些改进已为作者扫清了障碍,使其能够转向开发社区所请求的新功能。此外,该项目已将其社区中心从 Slack 迁移至公开的 Discourse 论坛,以确保更好的可访问性和协作体验。
抱歉。
![]() 法国里昂:Lab401
美国圣安娜:Hackerwarehouse
英国黑斯廷斯:KSEC
加拿大蒙特利尔:TechSecurityTools
中国深圳:Sneaktechnology
中国广东:MTools Tec
新加坡 Lazada One:Aliexpress by RRG
阅读可用文档。
ChameleonUltraGUI
MTools BLE Mifare Chameleon 工具(仅限 iOS,测试版)
Chameleon Ultra(仅限 Sailfish OS)
请注意,部分说明可能自录制以来已发生变化,如有疑问,请查阅最新文档!
下载并编译官方 CLI
下载 ChameleonUltraGUI
ChameleonUltraGUI 功能概述
使用 ChameleonUltraGUI 和 Chameleon Ultra
MTools BLE - 如何使用 ChameleonUltra 克隆卡片
在哪里可以找到社区?
RFID 破解社区 Discord 服务器
Software/chameleon-dev 用于固件和客户端开发讨论
Devices/chameleon-ultra 用于使用讨论
GameTec_live Discord 服务器
寻找文档仓库?
点击此处查看
法国里昂:Lab401
美国圣安娜:Hackerwarehouse
英国黑斯廷斯:KSEC
加拿大蒙特利尔:TechSecurityTools
中国深圳:Sneaktechnology
中国广东:MTools Tec
新加坡 Lazada One:Aliexpress by RRG
阅读可用文档。
ChameleonUltraGUI
MTools BLE Mifare Chameleon 工具(仅限 iOS,测试版)
Chameleon Ultra(仅限 Sailfish OS)
请注意,部分说明可能自录制以来已发生变化,如有疑问,请查阅最新文档!
下载并编译官方 CLI
下载 ChameleonUltraGUI
ChameleonUltraGUI 功能概述
使用 ChameleonUltraGUI 和 Chameleon Ultra
MTools BLE - 如何使用 ChameleonUltra 克隆卡片
在哪里可以找到社区?
RFID 破解社区 Discord 服务器
Software/chameleon-dev 用于固件和客户端开发讨论
Devices/chameleon-ultra 用于使用讨论
GameTec_live Discord 服务器
寻找文档仓库?
点击此处查看
抱歉。