👍 1 人点赞 👎 1 人点踩 😄 1 人大笑 🎉 1 人喝彩 😕 1 人困惑 ❤️ 1 人点心 🚀 1 人点火箭 👀 1 人围观 您目前无法执行此操作。
每日HackerNews RSS
Blaise v0.10.0:原生后端、线程与增量编译 Blaise v0.10.0: Native Back End, Threads and Incremental Compilation
22 天前
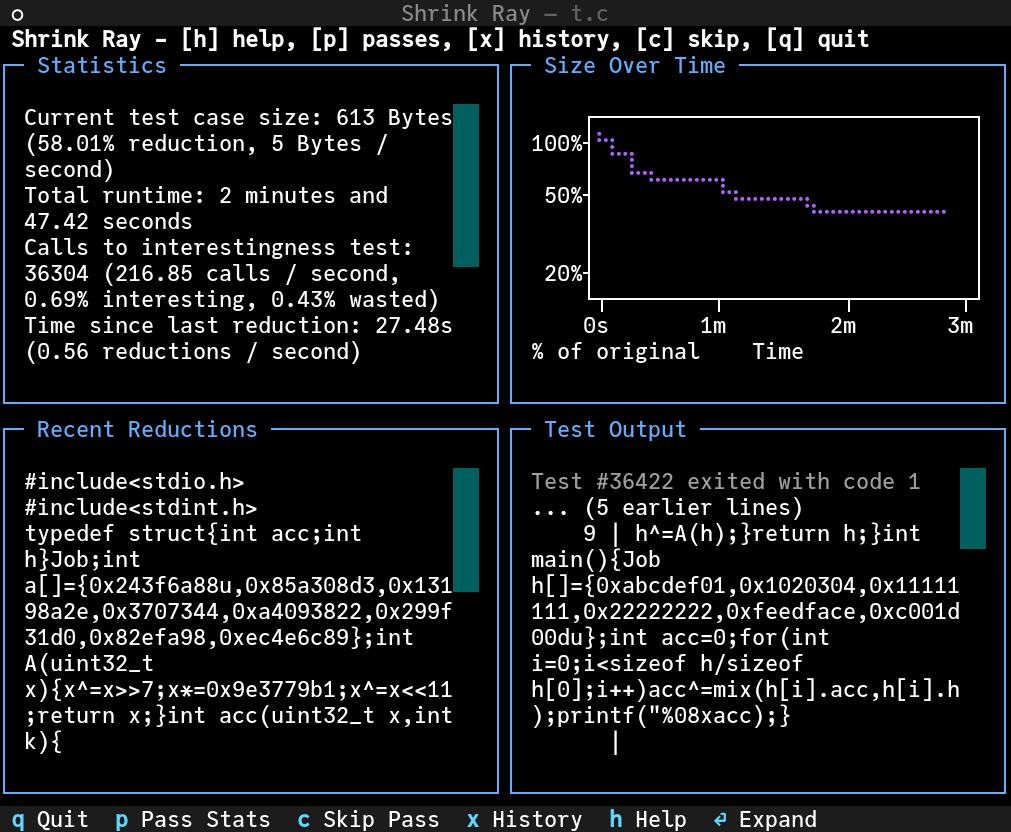 测试用例精简器(Test-case reducers)是一种强大却常被低估的工具,它能自动将庞大的输入文件缩小至能触发特定软件错误的最小版本。通过将繁琐的手动精简过程自动化,此类工具(如“Shrink Ray”)能够将输入大小缩减 90% 以上,从而大幅降低调试难度。
这一过程依赖于“兴趣测试”:即一个脚本,若错误仍然存在则返回成功代码,若错误消失则返回失败代码。由于精简器无需了解程序的内部逻辑,因此它可以应用于几乎任何文件格式。
高级用户可以通过自定义兴趣测试来设定特定目标,从而突破基础长度缩减的局限:
* **管理非确定性:** 通过要求错误在多次运行中持续出现,用户可以强制精简器优先选择确定性更高、更易于调试的输入。
* **设定优化指标:** 通过使用外部的“全局最优”计数器,用户可以引导精简器优化其他次要因素,例如执行时间、内存占用或日志长度,而非仅仅追求原始文件大小。
尽管这些非常规方法往往带有“黑客”色彩,但它们能将测试用例精简器从简单的实用程序转变为多功能的调试助手。
测试用例精简器(Test-case reducers)是一种强大却常被低估的工具,它能自动将庞大的输入文件缩小至能触发特定软件错误的最小版本。通过将繁琐的手动精简过程自动化,此类工具(如“Shrink Ray”)能够将输入大小缩减 90% 以上,从而大幅降低调试难度。
这一过程依赖于“兴趣测试”:即一个脚本,若错误仍然存在则返回成功代码,若错误消失则返回失败代码。由于精简器无需了解程序的内部逻辑,因此它可以应用于几乎任何文件格式。
高级用户可以通过自定义兴趣测试来设定特定目标,从而突破基础长度缩减的局限:
* **管理非确定性:** 通过要求错误在多次运行中持续出现,用户可以强制精简器优先选择确定性更高、更易于调试的输入。
* **设定优化指标:** 通过使用外部的“全局最优”计数器,用户可以引导精简器优化其他次要因素,例如执行时间、内存占用或日志长度,而非仅仅追求原始文件大小。
尽管这些非常规方法往往带有“黑客”色彩,但它们能将测试用例精简器从简单的实用程序转变为多功能的调试助手。
苹果的人工智能现在可以更改你的密码了。这能出什么岔子? Apple's AI Can Now Change Your Passwords. What Could Possibly Go Wrong?
22 天前
苹果即将推出的 iOS 27 更新引入了一项代理功能,利用 Apple Intelligence 和 Safari 自动更新已泄露的网站密码。虽然这有望解决用户忽视违规通知这一常见的安全疏漏,但由于赋予了 AI 代理处理敏感账户凭据的权限,这也带来了巨大的风险。 专家认为,尽管自动化可以提升安全性,但必须克服以下重大障碍: * **提示注入(Prompt Injection):** 浏览器代理运行在不受信任的网站上,这些网站可能会利用隐藏指令操控 AI 执行未经授权的操作(例如禁用多因素认证或更改恢复设置)。 * **操作风险:** 如果新密码未正确保存或同步,工作流的故障可能会导致账户锁定或数据丢失。 * **信任边界:** 在没有用户明确、细致的授权下,不应仅凭设备已解锁就授予代理修改多个账户的广泛权限。 为了确保此功能的安全性,苹果必须确保 AI 模型永远无法直接访问密码,强制执行严格的来源验证,要求对每次更改进行生物识别确认,并保留清晰的审计追踪记录。归根结底,该功能的成功取决于苹果能否从“模糊的智能”转向透明且万无一失的安全架构。
请启用 JavaScript 和 Cookie 以继续。
关于“认为人工智能会取代员工的CEO就是糟糕的CEO”这一观点,讨论中达成了广泛共识:领导层往往从根本上误解了人工智能的角色,以及交付现实世界产品的复杂性。
许多贡献者认为,人工智能是增强人类能力的工具,而非取代人类判断、架构设计或产品策略的手段。参与者指出,虽然人工智能可以简化编程或重复性任务,但在处理创造性的“该构建什么”的决策、跨系统架构维护,以及支持服务和用户获取等艰巨且微妙的工作时,人工智能仍面临困难。
批评者认为,“糟糕”的CEO患有一种“人工智能精神错乱”——这是一种“货物崇拜”心态,即他们看到人工智能的炒作,便将其误解为裁员以取悦股东的理由,而非利用该技术来扩大产出或构建更复杂的系统。此外,对于前沿实验室所宣传的“代理”能力,人们也持强烈的怀疑态度,许多人指出,CEO们往往将人工智能视为掩盖自身无能或人为提升短期利润的灵丹妙药。最终,共识在于,尽管人工智能将继续改变工作流程,但当它被用作替代实际商业策略的手段时,仍是一种危险的干扰。
 GPT-2 是 GPT-1 的直接大规模演进版本,它沿用了相同的 Transformer 解码器架构,但大幅增加了参数数量和训练数据。GPT-1 证明了预训练模型无需有监督微调即可执行任务,而 GPT-2 通过将参数规模扩大至 15 亿并使用海量网络文本语料进行训练,进一步扩展了这一能力。
在最初开发时,OpenAI 因担忧其可能被恶意滥用及其生成的高质量类人文本,并未发布完整模型。这一决定引起了公众对该模型能力的极大兴趣。经过九个月关于负责任披露的研究,OpenAI 最终于 2019 年 11 月发布了完整模型。他们的研究结果强调了该模型输出的逼真度及其被滥用的可能性,同时也指出了对其进行检测的难度。
回望通往 ChatGPT 的发展历程,GPT-2 是识别强大语言模型风险的一项基础性实验。尽管安全措施已有所改进,但在 GPT-2 发布期间所发现的挑战——例如偏见、学术诚信以及检测 AI 生成内容的困难——随着人工智能技术的不断进步,仍然是目前持续关注的问题。
GPT-2 是 GPT-1 的直接大规模演进版本,它沿用了相同的 Transformer 解码器架构,但大幅增加了参数数量和训练数据。GPT-1 证明了预训练模型无需有监督微调即可执行任务,而 GPT-2 通过将参数规模扩大至 15 亿并使用海量网络文本语料进行训练,进一步扩展了这一能力。
在最初开发时,OpenAI 因担忧其可能被恶意滥用及其生成的高质量类人文本,并未发布完整模型。这一决定引起了公众对该模型能力的极大兴趣。经过九个月关于负责任披露的研究,OpenAI 最终于 2019 年 11 月发布了完整模型。他们的研究结果强调了该模型输出的逼真度及其被滥用的可能性,同时也指出了对其进行检测的难度。
回望通往 ChatGPT 的发展历程,GPT-2 是识别强大语言模型风险的一项基础性实验。尽管安全措施已有所改进,但在 GPT-2 发布期间所发现的挑战——例如偏见、学术诚信以及检测 AI 生成内容的困难——随着人工智能技术的不断进步,仍然是目前持续关注的问题。
几十年来,数据中心一直依赖“胖树”(fat-tree)拓扑结构,这种结构具有层级化、刚性且难以扩展的特点。尽管数学研究长期以来认为“随机连接”网络(扩展图)具有最佳的路由潜力,但由于布线、路由和运维方面的挑战,其实际应用一直难以实现。 亚马逊的一个研究团队——由 Giacomo Bernardi、Ratul Mahajan 和 Seshadhri Comandur 领导——通过创建“弹性网络图”(Resilient Network Graphs,简称 RNG)成功跨越了这一鸿沟。通过用“准随机”图取代层级结构,他们解决了三个主要障碍: * **路由:** “Spraypoint”技术实现了流量分发,且不会导致路由器内存过载。 * **布线:** “ShuffleBox”光电设备实现了可预测的随机连接。 * **运维:** 新的诊断软件和数学模型实现了经过验证的、可扩展的部署。 其结果是数据中心设计领域的一次范式转移。与传统的胖树结构相比,基于 RNG 的网络使用的路由器减少了 69%,吞吐量提高了 33%,并将功耗降低了 40%。到 2026 年,RNG 已成为亚马逊大多数新建数据中心的默认设计。这一转变用一种具有统计学性能保证且容量完全可互换的弹性、可增量扩展架构,取代了刚性且容易发生灾难性故障的层级结构。
 这项研究探讨了如何将 **Kolmogorov-Arnold 网络 (KANs)** 与 **FPGA 硬件**相结合,以实现超快、亚微秒级的机器学习性能。
研究证实,KANs 通过可学习的单变量函数取代了固定权重,非常适合在 FPGA 上实现。与依赖密集矩阵乘法的标准多层感知机 (MLPs) 不同,KANs 可以自然地映射到**查找表 (LUTs)** 上。通过将激活函数表示为 LUTs,研究人员在推理速度上比之前的 FPGA 实现提升了 2700 倍。
此外,该研究还引入了一种用于 **FPGA 在线学习**的新方法。利用 KANs 独特的数学特性,即 **B-样条局部性**(只有少量基函数处于活跃状态)和**有界性**,作者实现了硬件上的稳定实时梯度更新。这克服了传统基于 FPGA 训练的不稳定性,使得在高频应用(如量子控制和核聚变)中能够进行高效的模型自适应。
总之,这项工作证明了与 MLPs 相比,KANs 在硬件扩展性和资源效率方面具有显著优势。通过摆脱以 GPU 为中心的架构,作者证明了基于 KAN 的协同设计为实现纳秒级延迟推理和实时片上学习提供了一条稳健的路径。
这项研究探讨了如何将 **Kolmogorov-Arnold 网络 (KANs)** 与 **FPGA 硬件**相结合,以实现超快、亚微秒级的机器学习性能。
研究证实,KANs 通过可学习的单变量函数取代了固定权重,非常适合在 FPGA 上实现。与依赖密集矩阵乘法的标准多层感知机 (MLPs) 不同,KANs 可以自然地映射到**查找表 (LUTs)** 上。通过将激活函数表示为 LUTs,研究人员在推理速度上比之前的 FPGA 实现提升了 2700 倍。
此外,该研究还引入了一种用于 **FPGA 在线学习**的新方法。利用 KANs 独特的数学特性,即 **B-样条局部性**(只有少量基函数处于活跃状态)和**有界性**,作者实现了硬件上的稳定实时梯度更新。这克服了传统基于 FPGA 训练的不稳定性,使得在高频应用(如量子控制和核聚变)中能够进行高效的模型自适应。
总之,这项工作证明了与 MLPs 相比,KANs 在硬件扩展性和资源效率方面具有显著优势。通过摆脱以 GPU 为中心的架构,作者证明了基于 KAN 的协同设计为实现纳秒级延迟推理和实时片上学习提供了一条稳健的路径。

抱歉。
雷霆战机 Rayforce
22 天前
![]() Rayforce 是一款高性能、零依赖的 C17 分析引擎,将列式处理与图遍历融合为一个单一的优化流水线。它专为速度和效率而设计,采用了延迟操作 DAG、多趟优化器,以及能够将数据保留在 L1/L2 缓存中的融合式、基于分块(morsel-driven)的字节码执行器。
主要技术特性包括:
* **执行:** 采用自定义伙伴分配器(避开系统 `malloc`)、线程本地内存池,并通过线程池实现并行执行。
* **图引擎:** 具有支持高级算法(BFS、Dijkstra、PageRank 等)和因子化执行的双索引 CSR 存储。
* **向量搜索:** 包含原生 HNSW 索引,具备支持过滤的 ANN 功能,可进行高速相似度查询。
* **Rayfall:** 一种类似 Lisp 的查询语言,提供交互式 REPL,并能在运行时将表达式直接编译为引擎的字节码虚拟机。
Rayforce 专为生产环境设计,支持基于 mmap 的存储、并行 CSV 解析和高效的内存管理。该项目基于 MIT 许可证发布,提供 Python 绑定,并与 Lynx 合作开发,以支持高要求的金融和分析工作负载。完整文档请访问 [rayforcedb.github.io/rayforce](https://rayforcedb.github.io/rayforce)。
Rayforce 是一款高性能、零依赖的 C17 分析引擎,将列式处理与图遍历融合为一个单一的优化流水线。它专为速度和效率而设计,采用了延迟操作 DAG、多趟优化器,以及能够将数据保留在 L1/L2 缓存中的融合式、基于分块(morsel-driven)的字节码执行器。
主要技术特性包括:
* **执行:** 采用自定义伙伴分配器(避开系统 `malloc`)、线程本地内存池,并通过线程池实现并行执行。
* **图引擎:** 具有支持高级算法(BFS、Dijkstra、PageRank 等)和因子化执行的双索引 CSR 存储。
* **向量搜索:** 包含原生 HNSW 索引,具备支持过滤的 ANN 功能,可进行高速相似度查询。
* **Rayfall:** 一种类似 Lisp 的查询语言,提供交互式 REPL,并能在运行时将表达式直接编译为引擎的字节码虚拟机。
Rayforce 专为生产环境设计,支持基于 mmap 的存储、并行 CSV 解析和高效的内存管理。该项目基于 MIT 许可证发布,提供 Python 绑定,并与 Lynx 合作开发,以支持高要求的金融和分析工作负载。完整文档请访问 [rayforcedb.github.io/rayforce](https://rayforcedb.github.io/rayforce)。
抱歉。
本演示文稿为阿波罗全球管理公司(Apollo Global Management, Inc.)的机密财产,未经事先许可不得分发。所提供信息仅供一般参考之用;阿波罗不对其准确性或完整性做出任何保证,且不承担任何更新义务。 本文内容不构成会计、法律、税务或投资建议,亦非买卖任何证券或产品的要约或招揽。与会者在做出任何决定前,应自行进行独立调查并咨询专业顾问。阿波罗不担任您的顾问,也不提供客户层面的保护。 此外,本演示文稿包含涉及固有风险和不确定性的前瞻性陈述。这些预测反映了当前的判断,可能会发生变化,实际结果可能与预测存在重大差异。提请投资者注意,切勿对这些陈述产生过分依赖。